
Задачи статистической группировки: 2. Основные задачи и виды группировок. Общая теория статистики: конспект лекции
основные понятия, этапы, группировка материалов, задачи
В методе статистических группировок совокупность изучаемых явлений делится на классы и подклассы, которые имеют однородную структуру по определенным характеристикам. Каждое такое разделение описывается системой статистических показателей. Сгруппированные данные могут быть представлены в таблицах.
Данное действие является основным методом, используемым при фактическом изучении социальных явлений. Оно возникает в качестве предпосылки для применения различных группировок статистических данных, процедур и аналитических методов. Например, классификация необходима для того, чтобы использовать любые обобщающие индексы, например, средние.
Вклад В.И. Ленина
В дореволюционной российской статистике, в частности, в различных земствах (это органы местного самоуправления), значительный опыт был приобретен в группировке различных видов организаций. И также в это время был проделан существенный труд по разработке не только таблиц с классификацией по одной характеристике, но и более сложных схем. В них все данные группируются по двум и более параметрам. Однако теоретические вопросы, связанные с использованием методов статистических группировок, не получили научного обоснования. Такое положение дел сохранялось вплоть до работ В.И. Ленина. Он имел высокое мнение о познавательной ценности и практической важности классификации. В отношении таблиц, основанных на признаках статистической группировки, по более чем одной характеристике, Ленин писал: «Можно без преувеличения сказать, что они произведут революцию в науке и, конечно же, в экономике сельского хозяйства».
В них все данные группируются по двум и более параметрам. Однако теоретические вопросы, связанные с использованием методов статистических группировок, не получили научного обоснования. Такое положение дел сохранялось вплоть до работ В.И. Ленина. Он имел высокое мнение о познавательной ценности и практической важности классификации. В отношении таблиц, основанных на признаках статистической группировки, по более чем одной характеристике, Ленин писал: «Можно без преувеличения сказать, что они произведут революцию в науке и, конечно же, в экономике сельского хозяйства».
Принципиальное значение имеют рекомендации Владимира Ильича о необходимости предварительного политико-экономического анализа характера закономерностей и определения типов явлений перед началом экспериментов с классифицированием исходных данных.
Этапы статистических группировок
Систематизирование используется не только при анализе структуры населения, но также при определении типов явлений и при изучении взаимосвязей между различными характеристиками или факторами. Примерами группировок, которые выражают структуру населения, являются классификации людей по возрасту (с интервалами в один год или, чаще, пять лет) и предприятий по размеру.
Примерами группировок, которые выражают структуру населения, являются классификации людей по возрасту (с интервалами в один год или, чаще, пять лет) и предприятий по размеру.
Путем объединения классов или установления неравномерных интервалов, можно установить качественные различия между отдельными системами, а затем определить технико-экономические или социально-экономические типы соответствующих субъектов (например, предприятий или ферм). Таким образом, группирование населения страны по возрасту может осуществляться на основе, помимо простых хронологических объектов, таких специальных разделений, как женщины в возрасте от 16 до 54 лет и мужчины от 16 до 59 лет. Использование этих специальных классов позволяет рассчитывать национальный экономический индекс, известный как трудовые ресурсы страны. Границы интервалов несколько произвольны и могут отличаться в разных государствах.
Задача
Детальное количественное классифицирование предприятий и фирм позволяет перейти к определению нескольких основных качественных групп, таких как малые, средние и крупные организации. После этого можно прояснить ряд общих экономических проблем, например, процесс концентрации производства, рост эффективности промышленности и увеличение результативности труда. Новые данные Владимира Ильича Ленина о законах, регулирующих развитие капитализма в сельском хозяйстве, представляют собой блестящий пример глубокого анализа, который использует группировку для демонстрации сложного характера закономерностей. И также отношений между размером предприятия и его полной производительностью.
После этого можно прояснить ряд общих экономических проблем, например, процесс концентрации производства, рост эффективности промышленности и увеличение результативности труда. Новые данные Владимира Ильича Ленина о законах, регулирующих развитие капитализма в сельском хозяйстве, представляют собой блестящий пример глубокого анализа, который использует группировку для демонстрации сложного характера закономерностей. И также отношений между размером предприятия и его полной производительностью.
Самая главная и трудная задача статистических группировок, заключается в выявлении и подробном описании типов социально-экономических явлений. Такие субъекты представляют собой выражение форм определенного социального процесса или основных характеристик. Именно они представляются общими для многих отдельных явлений. В своем анализе расслоения крестьянства Владимир Ильич Ленин использовал группировку основательно и всесторонне. В первую очередь он раскрыл процесс формирования основных социальных классов в дореволюционной России, в западноевропейской деревне и в сельском хозяйстве США.
И, как оказалось, советские данные имеют значительный опыт типологических и статистических группировок. Например, баланс народного хозяйства СССР предполагает сложную и разветвленную систему классифицирования. Другие примеры типологической статистической группировки в советском пространстве, включают в себя систематизирование населения по социальным классам. А также объединение основных производственных фондов по социально-экономическим типам промышленных единиц. И также можно привести такой пример, как группировка статистической совокупности общественного продукта.
Буржуазная классификация недостаточно использует систематизацию. Когда применяется группировка, она, по большей части, неверна и не способствует характеристике истинного положения дел в капиталистических странах. Например, классифицирование сельскохозяйственных предприятий по площади земли, преувеличивает положение мелкого производства в данном русле. А группировка населения по профессиям не раскрывает истинную классовую структуру буржуазного общества.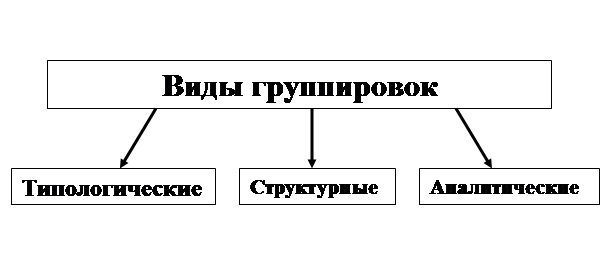
Социально-экономические характеристики социалистического государства предоставляют новые приложения для статистической группировки. Классифицирование используется для анализа выполнения национальных экономических планов, определения причин отставания некоторых предприятий и секторов. И также выявления неиспользованных ресурсов. Например, предприятия могут быть сгруппированы в соответствии со степенью выполнения плана или уровнем рентабельности. Большое значение для характеристики внедрения научно-технического прогресса в промышленность имеет группировка предприятий, по таким технико-экономическим данным, как степень автоматизации и механизации и количество электроэнергии, доступной для труда.
Сгруппированные данные являются сведениями, сформированными путем объединения отдельных группировок статистического наблюдения о наличии переменного на отдельные классы, так что распределение частот этих систем служит удобным средством обобщения и анализа всех материалов.
Информация
Данные могут быть определены как группы с материалом, которые представляют качественные или количественные атрибуты переменной или набора непостоянных. Это аналогично утверждению, что классы могут быть любым набором информации, которая описывает сущность. Системы, в группировке статистических данных, могут быть классифицированы на сгруппированные и не сгруппированные объекты.
Это аналогично утверждению, что классы могут быть любым набором информации, которая описывает сущность. Системы, в группировке статистических данных, могут быть классифицированы на сгруппированные и не сгруппированные объекты.
Любая информация, которую человек соберет в первую очередь, является неклассифицированной. Не сгруппированные статистические группировки — это данные, но только в не обработанном виде. Примером таких систем является любой список чисел, который только можно придумать.
Первый тип классификаций
Сгруппированные данные — это информация, которая была организована в группы, известные как классы. Такой тип уже был классифицирован, и, таким образом, был проведен некоторый уровень анализа. Это означает, что вся информация больше не является необработанной.
Класс данных — это группа, которая связана с определенным пользовательским свойством. Например, если руководитель предприятия собирал людей, которых он принимает на работу в определенный год, он мог бы сгруппировать их в системы по возрасту: двадцати, тридцати, сорока годам и так далее. И каждая из этих групп называется классом.
И каждая из этих групп называется классом.
В свою очередь, это не последнее разделение. Каждый из этих классов имеет определенную ширину, и это называется интервалом или размером. Это понятие очень важно, когда речь идет о построении гистограмм и частотных диаграмм. Все классы могут иметь одинаковый или разный размер, в зависимости от того, как будет группироваться вся информация. Интервал системы всегда является целым числом.
Ограничения класса и его границы
Первое понятие относится к фактическим значениям, которые можно увидеть в конечной таблице. Ограничения класса делятся на две категории: нижний предел системы и верхняя граница. Конечно же, для обеспечения правильности и информативности используются все разделения при составлении таблиц.
Но, с другой стороны, границы классов не всегда соблюдаются в таблице частот. Данное понятие дает истинный интервал систем и, подобно различным ограничениям, также делится на рубежи нижнего и верхнего значения.
Живые и неживые группы
Наука стремится понять и объяснить природные явления. Ученые понимают вещи, классифицируя их. Это относится как к живым существам, так и к неживым группировкам статистических материалов.
Ученые понимают вещи, классифицируя их. Это относится как к живым существам, так и к неживым группировкам статистических материалов.
В свою очередь, такие типы можно разделить на группы в зависимости от контрастных свойств. Например, если студенты составили списки в своих научных журналах о различных материалах и предметах, которые они изучали, они могут использовать эти данные для расширения знаний и информации о системах, которые они исследовали.
Все знания могут быть отсортированы или классифицированы по различным контрастным свойствам. Вот некоторые примеры:
- Металлы против различных неметаллов.
- Каменная местность вместо пустыни или луга.
- Видимые кристаллы против незримых минералов.

- Естественный процесс вместо искусственного.
- Вещества плотнее воды или менее весомые, чем данная жидкость.
- Магнитный против немагнитного.

А также можно составить групповые различия по следующим признакам:
- Состояние веществ при комнатной температуре (твердое, жидкость, газ).
- Плавкость металлов.
- Физические свойства и так далее.

Материалы:
- Различные статьи, которые служат примерами категорий выше.
- Магниты для проверки свойств материалов.
- Контейнер с водой, чтобы проконтролировать, плавают ли предметы или тонут.
- Научные журналы.
Процедура работы
Как именно все происходит:
- Студенты работают в группах. Каждой дают некоторые материалы и просят найти способы группировки предметов по категориям. Они разрабатывают критерии, которые будут использовать, а затем сортируют элементы соответствующим образом. Таблицы результатов фиксируются в их научных журналах.
- После группировки материалов они снова сортируются по другим критериям. Следующим шагом также будет составления списка результатов. И после этого пишется дополнительный ряд элементов, которые были отсортированы по-разному из-за изменения критериев.
- Студенты фиксируют наблюдения и таблицы в своих научных журналах.
 Они разрабатывают критерии, которые будут использовать, а затем сортируют элементы соответствующим образом. Таблицы результатов фиксируются в их научных журналах.
Они разрабатывают критерии, которые будут использовать, а затем сортируют элементы соответствующим образом. Таблицы результатов фиксируются в их научных журналах.Результаты
Студенты фиксируют серию таблиц, которые показывают, как их предметы сортируются на основе каждого из критериев. Например, у группы учеников есть скрепка, маленький кусочек гранита, пробка, пластиковая игрушка. И тогда пара таблиц сортировки может выглядеть так, как написано ниже.
- Предметы отсортированы по магнетизму.
- Реагируют на магнит: скрепка для бумаг, гранит. Не реагируют: пробка, пластик.
- Предметы отсортированы по плотности, по сравнению с водой.
- Всплывают: пробка, пластик. Тонут: скрепка для бумаги, гранит.
После этого, студенты делают презентации для класса. Они обсуждают, почему разные предметы классифицируются по-разному в зависимости от используемых критериев.
Студенты повторяют эти наблюдения каждый раз, применяя разные свойства.
Обсуждение
На этом этапе:
- Студенты могут распространить эти наблюдения на другие материалы, уже без каких-либо практических исследований.
- Примерами могут служить образцы разных типов горных пород. Студенты узнают, как делать более тщательные наблюдения и писать точно о том, что они видят, с помощью луп и других предметов, которые они используют.
- Если ученики создали индексный файл свойств, записанный на карточках, их также можно отсортировать. Это будет полезно, если указатель содержит дополнительные материалы, которых нет в классе.

Распространенным способом обработки непрерывных количественных данных является подразделение всего диапазона смыслов на несколько поддиапазонов. Необходимо присваивать каждому материалу постоянное значение класса, в который он попадает. Стоит обратить внимание, что набор данных изменяется от непрерывного к дискретному.
Понятие статистической группировки
Систематизирование выполняется путем определения набора диапазонов, а затем подсчета количества данных, попадающих в каждый из них. Поддиапазоны не перекрываются. Они должны охватывать весь диапазон набора данных.
Поддиапазоны не перекрываются. Они должны охватывать весь диапазон набора данных.
Одним из наиболее удачных способов визуализации сгруппированных систем является гистограмма. Она представляет собой набор прямоугольников, где основание фигуры охватывает значения в диапазоне, связанном с ним. А высота соответствует количеству информации.
Статистическая сводка и группировка. Решение задач и контрольных работ по статистике онлайн
Группировка — это разграничение изучаемой совокупности по значениям одного или нескольких признаков на качественно однородные группы и характеристика их системой показателей. В зависимости от поставленной цели и конкретного содержания исследуемого материала посредством группировок решают три основные задачи:
- выделяются социально-экономические
типы явлений;выявляются состав и структура совокупности;устанавливаются, изучаются причинно-следственные связи между признаками явлений.
Соответственно
этим задачам используются три вида группировок — типологические, структурные и
факторные.
На основе типологических группировок осуществляется образование однокачественных групп или типов явлений. Структурные группировки позволяют выявить внутреннее состояние явлений. При построении структурных группировок по количественным признакам устанавливаются границы выделяемых групп. Решая вопрос о величине интервала групп (или, что то же, о числе групп), необходимо иметь в виду, что следует выбирать такое число групп, чтобы при этом не наблюдалось существенных отклонений от равномерного распределения внутри каждой группы. Величина равного интервала в этом случае определяется по формуле:
и -минимальное и максимальное значения группировочного признака; n — число выделяемых групп. Хороший способ приближенного определения интервала группировки может быть получен на основе формулы Стерджесса:
где
-
число единиц совокупности.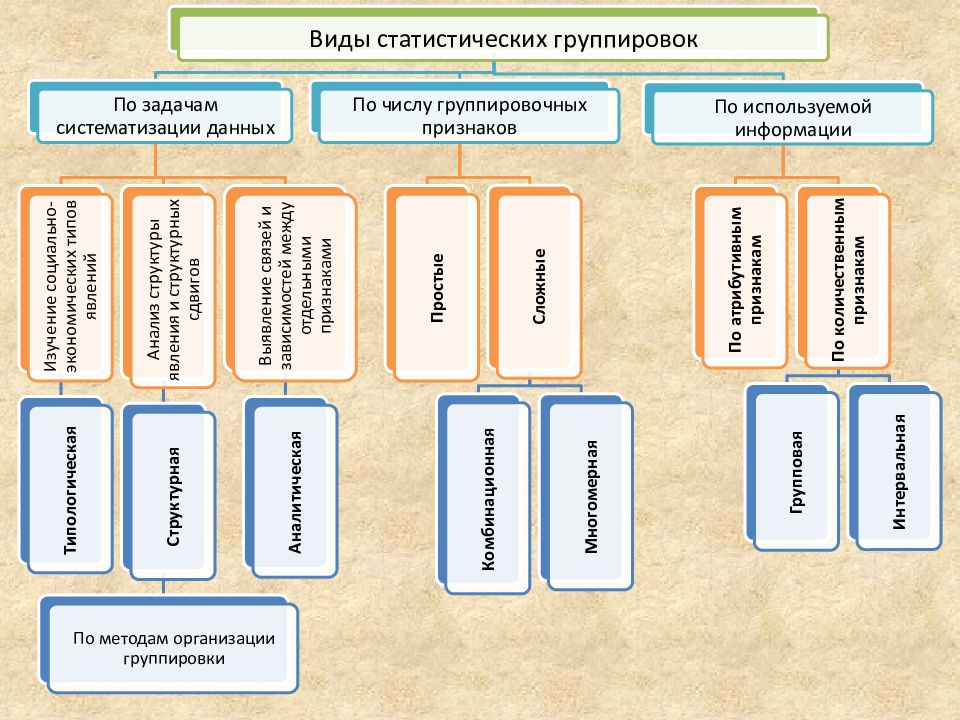
Статистические ряды, в которых показывается только распределение единиц в изучаемой совокупности в зависимости от величины признака, обычно называют рядами распределения или вариационными рядами.
Величина равного интервала при построении вариационных рядов распределения используется в тех случаях, если соотношение максимального и минимального значений группировочного признака не превышает десятикратного значения. В случаях значительной вариации группировочного признака целесообразно применять кратные интервалы. В практике статистических исследований обычно используют удвоенные кратные интервалы, т. е. величина каждого последующего интервала по сравнению с предыдущим удваивается. Для выявления специфических особенностей распределений, допустим изучение характера концентрации производства, могут быть использованы неравные интервалы.
Интервалы группировки считаются обоснованными, если
коэффициент вариации признака в них не превышают 33%. Посредством факторной группировки
устанавливаются и изучаются причинно-следственные связи между признаками
однородных явлений.
Посредством факторной группировки
устанавливаются и изучаются причинно-следственные связи между признаками
однородных явлений.
Задача
Имеются следующие данные об урожайности картофеля и количеством внесенных минеральных удобрений по 10 сельскохозяйственным предприятиям:
| Номер колхоза | Урожайность, ц/га | Внесено минеральных удобрений на 1 га, кг | Номер колхоза | Урожайность, ц/га | Внесено минеральных удобрений на 1 га, кг |
| 1 | 140 | 6 | 183 | 197 | |
| 2 | 179 | 262 | 7 | 201 | 246 |
| 3 | 221 | 289 | 8 | 276 | |
| 4 | 136 | 191 | 9 | 141 | 187 |
| 5 | 164 | 202 | 10 | 192 | 253 |
Для изучения зависимости
между урожайностью картофеля и внесенными минеральными удобрениями произведите
группировку сельскохозяйственных предприятий, образовав 3 группы предприятий с
равными интервалами.
- число предприятий;
- среднюю урожайность картофеля;
- средний объем внесенных минеральных удобрений на 1 га, кг.
Результаты представьте в таблице и сделайте выводы.
Если не находите примера, аналогичного вашему, если сами не успеваете выполнить работу, если впереди экзамен по предмету и нужна помощь — свяжитесь со мной:
ВКонтакте
WhatsApp
Telegram
Я буду работать с вами, над вашей проблемой, пока она не решится.
Решение
Расположим предприятия в таблице по возрастанию урожайности.
Произведем расчет групп:
Длина интервала:
1-я группа: 128 –159 ц/га
2-я группа: 159 –190 ц/га
3-я группа: 190 –221 ц/га
| Номер колхоза | Урожайность, ц/га | Внесено минеральных удобрений на 1 га, кг |
| 1 | 128 | 140 |
| 4 | 136 | 191 |
| 9 | 141 | 187 |
| Итого | 405 | 518 |
| 159 – 190 | ||
| 5 | 164 | 202 |
| 2 | 179 | 262 |
| 6 | 183 | 197 |
| Итого | 526 | 661 |
| 190 – 221 | ||
| 10 | 192 | 253 |
| 8 | 195 | 276 |
| 7 | 201 | 246 |
| 3 | 221 | 289 |
| Итого | 809 | 1064 |
Получаем следующую группировку:
Группировка сельскохозяйственных предприятий по урожайности
| Урожайность, ц/га | Число предприятий | Средняя урожайность, ц/га | Средний объем внесенных минеральных удобрений на 1 га, кг |
| 128 – 159 | 135,0 | 172,7 | |
| 159 – 190 | 3 | 175,3 | 220,3 |
| 190 -221 | 4 | 202,3 | 266,0 |
| Итого | 10 | 174,0 | 224,3 |
Таким
образом получаем, что между урожайностью и внесением
минеральных удобрений существует прямая зависимость. Чем больше урожайность на
предприятии, тем больше предприятие вносило минеральных удобрений на 1 га.
Чем больше урожайность на
предприятии, тем больше предприятие вносило минеральных удобрений на 1 га.
Организация государственной статистики в Российской Федерации
Сводка и группировка статистических данных
Статистическая сводка. Организационные вопросы сводки. Виды сводки по глубине и форме обработки материала, технике выполнения. Программа статистической сводки. Результаты сводки. Группировка статистических данных. Группировочные признаки. Принцип оптимизации числа групп. Формула Стерджесса. Простые и сложные группировки. Факторные и результативные признаки. Перегруппировка статистических данных. Обеспечение сравнимости статистических группировок. Понятие о рядах распределения. Атрибутивные и вариационные ряды распределения. Дискретные и интервальные вариационные ряды распределения. Графическое изображение рядов распределения: полигон, гистограмма, кумулята и огива.
После изучения этой темы Студент должен:
знать:
— задачи и порядок организации статистической сводки;
— задачи и порядок организации статистической сводки;
— виды статистической сводки;
— сущность и содержание метода группировок в статистике;
— виды статистических группировок;
— принципы построения и виды рядов распределения в статистике;
— способы графического изображения рядов распределения;
уметь:
— построить группировку данных в соответствии с поставленными целями и задачами;
— определить вид представленной группировки;
— произвести перегруппировку статистических данных для обеспечения их сопоставимости. — построить ряд распределения, представить его графическое изображение и произвести анализ полученных результатов.
— построить ряд распределения, представить его графическое изображение и произвести анализ полученных результатов.
Термины и понятия
Сводка. Группировка. Типологическая группировка. — Структурная группировка. Аналитическая группировка. Группировочный признак. Классификация. Интервал. Величина интервала. Открытые интервалы. Закрытые интервалы. Ряд распределения. Варианты. Частоты. Частости. Атрибутивный ряд. Вариационный ряд. Дискретный вариационный ряд. Интервальный вариационный ряд. Группировка с равными интервалами. Группировки с неравными интервалами. Специализированные интервалы. Полигон. Гистограмма. Кумулята. Огива. Вторичная группировка.
Вопросы для самоконтроля
1) В чем заключается суть сводки статистических материалов?
2) Какие существуют виды сводки?
3) Какие задачи решаются в статистике при помощи метода группировок.
4) Какие существуют виды группировок?
5) Чем надо руководствоваться при выборе группировочных признаков?
6) Как определяется число групп?
7) Какие бывают интервалы?
8) Что понимается под классификацией в статистике?
9) Как определяется величина интервала при группировке по количественному признаку?
10) Что представляют собой ряды распределения?
11) По каким признакам могут быть образованы ряды распределения?
12) Как подразделяются вариационные ряды и на каких признаках основано такое деление?
13) Что такое полигон и гистограмма, для чего они применяются и как строятся?
14) Что такое частота и частность ряда распределения?
15) В чем заключается особенность рядов распределения как простейший группировки?
16) В чем сущность метода вторичной группировки?
Рекомендуемая литература:
основная [3]; [4];[5];
дополнительная [15]; [8].
Статистика » Сущность классификации и группировки и их задачи
Массовые явления весьма разнообразны, сложны и, как правило, проявляются в разных формах. Совокупности, отражающие их, обладают определенной динамичностью: в их состав вступают новые единицы, другие выбывают, некоторые переходят из одной совокупности в другую.
Выделение качественно однородных совокупностей требует в статическом исследовании учета роли составляющих их единиц в данном конкретном массовом процессе. Поэтому появляется необходимость классификации самих объектов, а часто дальнейшего расчленения единиц внутри совокупности. Необходимо различать понятия «классификация» и «группировка».
Под классификацией в статистике следует понимать устойчивое общепринятое разграничение объектов на основании их сходства и различия по группам. Например, классификация промышленных предприятий по отраслям промышленности, классификация основных фондов по видам, классификация работников по категориям, профессиям и специальностям, по уровню квалификации.
В отличие от этого группировка может быть произведена только для целей данного исследования.
Группировкой в статистике называется разделение единиц изучаемого массового явления по существенным признакам для того, чтобы выделить качественно однородные части единиц совокупности (подмножества или группы единиц совокупности) и охарактеризовать совокупности или взаимосвязи в изменении варьирующих признаков.
Значение группировки при обработке статистических данных можно показать на примере статистики населения. Численность населения приводится в целом по стране, в разрезе областей, районов, городов, поселков городского типа, сельских населенных пунктов. Эти цифры очень важны. Однако, используя группировки, можно изучить закономерности изменения культурного уровня населения, изменение состава населения по роду занятий и профессиям и т.д.
Метод группировки является одним из важнейших методов, применяемых статистикой при изучении массовых явлений.
Чтобы изучить то или иное массовое явление, прежде всего необходимо найти в нем качественно однородные группы единиц, охарактеризовать их статистическими показателями, сравнить между собой. Только тогда можно обнаружить все особенности и характерные черты изучаемого явления. Без группировки нельзя правильно и всесторонне изучить, глубоко проанализировать практически ни одно конкретное массовое явление.
Только тогда можно обнаружить все особенности и характерные черты изучаемого явления. Без группировки нельзя правильно и всесторонне изучить, глубоко проанализировать практически ни одно конкретное массовое явление.
Решение крупнейших задач социально-экономического анализа – характеристика типов, вскрытие их взаимосвязей, установление причинно-следственных зависимостей между отдельными факторами и результатами развития процесса или явления – возможно только на основе использования метода группировки.
Таким образом, группировки представляют собой исходный и необходимый этап обработки материалов статистического наблюдения. От качества группировки во многом зависит глубина последующего анализа статистического материала, его ценность.
При помощи группировки в статистике решают различные конкретные задачи, которые можно в конечном счете свести к основным:
1) разделение всей совокупности на качественно однородные типы или группы ее единиц;
2) характеристика структуры изучаемого явления;
3) характеристика взаимосвязей между варьирующими признаками.
3 Сводка и группировка статистического материала
Тема 3. Сводка и группировка статистического материала
1. Сводка статистического материала, ее организация и техника исчисления. Метод группировки. Виды статистических группировок.
2 Принципы построения статистических группировок.
4. Ряды распределения, их виды.
-1-
Статистическая сводка – это вторая стадия статистического исследования, которая представляет собой научную обработку данных в целях получения обобщённых характеристик изучаемого явления по ряду существенных для него признаков.
Составными элементами сводки является:
Рекомендуемые файлы
1. Программа, определяющая группировки, которые будут применяться, и систему показателей, характеризующих совокупность в целом и отдельные её группы.
2. Подсчёт групповых и общих итогов.
1. Оформление полученных данных в статистические таблицы.
С точки зрения организации сводка может быть централизованной и децентрализованной.
При централизованной сводке весь первичный материал наблюдения сосредотачивается и обобщается в центральной организации.
При децентрализованной сводке материалы предприятий учреждений сначала сводятся в пределах административных районов или объединений, полученные итоги передаются для обобщения в последующие вышестоящие звенья.
Группировкой в статистике называют разбиение изучаемого явления на части по существенным признакам.
В соответствии с делением признаков на атрибутивные (качественные или описательные) и количественные различают группировку по атрибутивному признаку и по количественному признаку.
Варьирующие признаки, положенные в основание группировки, называются группировочными признаками.
Группировки в статистике решают многие задачи, но все они преследуют одну цель — упорядочить первичный статистический материал, разделить его на группы с тем, чтобы подвергнуть дальнейшему анализу.
Выделяют три основные задачи, которые решаются с помощью метода группировок:
1. Выделение социально-экономических типов. Данная задача решается с помощью типологических группировок.
Выделение социально-экономических типов. Данная задача решается с помощью типологических группировок.
2. Изучение состава совокупности по тем или иным признакам – такие группировки называются структурные.
3. Изучение взаимосвязанного (изменения) варьирующих признаков в пределах той или иной совокупности; данная задача решается с помощью аналитических группировок.
Явления общественной жизни и их признаки тесно связаны между собой и зависят друг от друга. Взаимосвязанные признаки: факторные и результативные.
Факторным называется признак под воздействием, которого изменяется другой, зависящей от него признак, называемый результативным.
Взаимосвязь проявляется в том, что с изменением значения факторного признака увеличивается или уменьшается значение результативного признака. Группировочный признак обычно является факторным, а характеризующий группировку — результативным.
В зависимости от того, сколько группировочных признаков положено в основание группировки, различают простые (по одному признаку) и сложные или комбинационные группировки (по двум или более признакам взятые в сочетании).
-2-
Характер образования группировок зависит от признаков, на которых основывается группировка, и от задач группировки. При группировке по количественному признаку возникает вопрос о количестве групп:
1. При типологической группировке количество групп определяется задачей исследования, т.е. количеством типов явления ( например, предприятия можно разделить на 3 типа: малые, средние, крупные).
2. Если перед группировкой по количественному признаку стоит задача показать, как по этому признаку распределяются единицы совокупности, в этом случае число групп должно быть достаточным, чтобы выявить характер распределения. Для этого должно быть принята во внимание колеблемость группировочного признака, чем больше колеблемость, тем больше образуется групп и наоборот.
При группировке по количественному признаку возникает вопрос об интервалах групп.
Интервалом называется разница между максимальным и минимальным значением признаков в каждой группе.
Интервалы могут быть равными и неравными, открытыми и закрытыми.
Равными называются такие, у которых разница между верхним и нижним значением в каждой группе одинаково.
Неравные те, у которых эта разница не одинакова.
Закрытые – это такие интервалы, у которых указана верхняя и нижняя границы признака.
Открытые — указана либо нижняя, либо верхняя граница признака.
Пример: зарплата: 2000 – 7000 – закрытый
Свыше 2000
7000 и более – открытые
Расчет величины интервала при равноинтервальном распределении определяется по формуле:
D=(X max – X min)/n
D — величина интервала.
Xmax – максимальное значение признака.
Xmin – минимальное значение признака.
n – количество групп, на которое разбивается совокупность.
При группировке единиц совокупности по непрерывно варьирующему признаку следует уделить особое внимание вопросу отношения отдельных единиц совокупности, значения которых являются граничными той или иной группы.
Пример:
Группировка строительно-монтажных организаций по объему работ в млн. тенге.
1. I. до1 млн.
II. 1 — 3,2
III V3,2 — 5,0
IV 5,0 и выше.
Из обозначения последнего интервала следует, что V=5,0 млн.т. относится к последней группе, соответственно и все другие пограничные значения будут учитываться по левой стороне т.е. V=3,2 будет отнесён к третьей группе.
2. I. до1
II. 1 — 3,2V
III. 3.2 — 5.0
IV свыше 5,0
В данном случае из обозначения последнего интервала следует что V=5 млн.т. относится к III группе соответственно и все другие пограничные значения будут учитываться по правой стороне, т.е. V=3,2 отнесем к II группе.
3. I. до1
II. 1 — 3,2
III. V3.2 — 5.0
IV 5,0 — 8,0
При таком обозначении групп учёт пограничных значений ведется по левой стороне.
Построение группировки по атрибутивному признаку (пол, национальность, специальность) может быть сравнительно простым, где число групп предопределено самим группировочным признаком (группировка населения по полу) и сложным (группировка рабочих по профессии) такие сложные группировки по атрибутивному признаку называются классификацией.
Классификация – это устойчивая группировка по атрибутивному признаку, которая содержит очень подробную номенклатуру групп и подгрупп и их перечень рассматривается как статистический стандарт, утверждаемый национальным статистическим агентством.
-3-
Результатом статистической сводки могут быть ряды статистических данных характеризующих (изменение объема) совокупностей в динамике, либо рассмотрение единиц совокупности по тем или иным варьирующим признакам в статике, в первом случае образуются динамические ряды, анализ которых выявляет закономерности динамики; во втором случае образуются ряды распределения, анализ которых имеет задачей выявить характер и закономерность распределения.
Рядом распределения в статистике называется упорядоченное распределение единиц совокупности на группы по какому-либо варьирующему признаку. Распределение может быть по атрибутивному признаку (рассмотрение занятого населения по отраслям) и по количественному признаку. Ряды рассмотрения единиц совокупности по признакам, имеющим количественное выражение, называются вариационными рядами.
Ряды рассмотрения единиц совокупности по признакам, имеющим количественное выражение, называются вариационными рядами.
В вариационном ряду различают 2 элемента: варианты и частоты.
Вариантом называют отдельное значение группировки признака, которые он принимает в данном ряду.
Числа, которые показывают, как часто встречается тот или иной вариант, называется частотами. Частоты могут быть выражены в процентах или долях единицы в этом случае их называют частостями.
Вариационные ряды могут быть интервальными и дискретными.
Интервальные вариационные ряды – это такие ряды, где значение варианта даны в виде интервалов (распределение рабочих по возрасту).
Дискретные вариационные ряды характеризуются тем, что варианты имеют значения целых чисел.
Если вариационный ряд имеет группы с неравными интервалами, то частоты в отдельных интервалах непосредственно несопоставимы, т.к. зависят от величины интервала.
Для того чтобы частоты можно было сравнить, исчисляют плотность распределения.
Информация в лекции «4 Классификация систем учета затрат на производство и калькулирования продукции» поможет Вам.
Плотность распределения – это частота, рассчитанная на единицу величины интервала.
Распределение рабочих по стажу.
Правила построения рядов распределения аналогичны правилам образования групп.
Сводка и группировка статистических данных
РЯЗАНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ им. А.С. ЕСЕНИНА
ФАКУЛЬТЕТ СОЦИОЛОГИИ И УПРАВЛЕНИЯ
КОНТРОЛЬНАЯ РАБОТА
По дисциплине: Статистика
На тему: Сводка и группировка статистических данных
Выполнила студентка 3 г.о.
заочной формы обучения
Машкова А. А.
А.
Проверил _______________
РЯЗАНЬ 2012 г.
Содержание
1. Задачи сводки и её основное содержание
2. Задачи группировок и их значение в статистическом исследовании
3. Виды группировок
4. Суть и виды статистических группировок
5. Выполнение группировки по количественному признаку
6. Ряды распределения, их виды и графическое изображение
7. Приёмы статистических группировок
8. Правила построения статистических таблиц
1. Задачи сводки и её основное содержание
Собранный в процессе статистического наблюдения статистический материал нуждается в определённой обработке, сведений разрозненный данных воедино. Научно организованная обработка материалов наблюдения (по заранее разработанной программе), включая в себя кроме обязательного контроля собранных данных систематизацию, классификацию (группировку) материала, составление таблиц, получение итогов и производных показателей (средних, относительных величин), именуется в статистике сводкой и представляет собой второй этап статистического исследования.
В результате сводки достигается возможность по данным, относящимся к отдельным единицам наблюдения, характеризовать совокупность в целом. Так, например, на основе отчётов отдельных промышленных предприятий получают сведения о многих показателях отдельных отраслей и всей промышленности в целом: о выпуске продукции, числе занятых, производительности труда и т.п. Получение различного рода структурных характеристик (например, определение доли отдельных отраслей промышленности в общем, объеме промышленного производства) также возможно только на основе данных, полученных в результате сводки.
Таким образом, целью сводки является сведение воедино материалов статистического наблюдения и получение обобщающих статистических показателей, отражающих сущность социально-экономических и иных явлений и определённые статистические закономерности.
Различают следующие виды статистической сводки:
Простая статистическая сводка — это такая сводка, когда производится только подсчёт общих итогов статистического наблюдения;
Сводка вторичная — это обработка и подсчёт данных, полученных в результате первичной сводки;
Сводка децентрализованная — это способ организации сводки данных, состоящий в том, что обработка первичных данных, полученных в результате статистического наблюдения, производится на местах.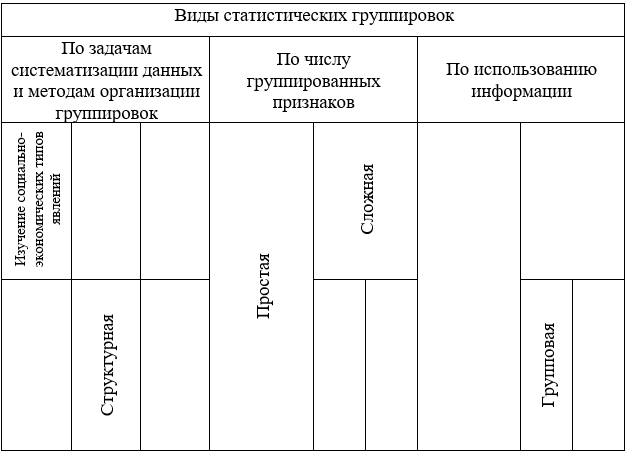 Она проходит несколько этапов. Сначала данные сводятся в пределах административно-
Она проходит несколько этапов. Сначала данные сводятся в пределах административно-
Сводка ручная — это способ выполнения статистической сводки, при котором все основные операции (главным образом подсчёт групповых и общих итого) осуществляется вручную.
Сводка механизированная — это способ выполнения статистической сводки, при котором все операции осуществляются на основе применения электронно-вычислительных машин (ЭВМ).
Сводка первичная — это сводка, при которой обработка и подсчёт данных происходит непосредственно в процессе статистического наблюдения.
Сводка централизованная — это способ организации сводки статистических данных, при котором все первичные материалы, полученные в результате статистического наблюдения, сосредотачиваются в центральном органе, где и подвергаются сводке.
Статистическая сводка проводится по определённой программе. Причём эта программа должна быть разработана ещё до сбора статистических данных, т.е. практически одновременно с составлением плана статистического наблюдения.
Разработать программу сводки — это, значит, определить, какие группы и подгруппы будут выделены в изучаемой совокупности, какие показатели в виде итого, средних или относительных величин должны быть подсчитаны для групп и в целом по совокупности, в каких таблицах будет оформлен результат сводки. Выделение данных групп должно быть обоснованным, а не формальным. Сводка кроме получения итоговых и групповых показателей даёт основу для последующего анализа и выявления различного рода закономерностей. Она упорядочивает статистический материал, полученный при наблюдении, классифицирует и систематизирует его.
Упорядоченные в результате сводки статистические совокупности выражаются часто в виде статистических рядов.
В зависимости от того, по какому принципу группируются единицы статистической совокупности, статистические ряды могут носить разный характер. Если единицы совокупности систематизируются по какому-либо имманентному их признаку, то они образуют ряды распределения (например, распределение населения по полу, возрасту, национальности и т.п., распределение промышленных предприятий по отраслям, размерам производства и т.п.). К рядам распределения близко примыкают и так называемые территориальные, или географические, ряды. Которые характеризуют распределение, какой либо совокупности по отдельным территориальным единицам.
Если единицы совокупности систематизируются по какому-либо имманентному их признаку, то они образуют ряды распределения (например, распределение населения по полу, возрасту, национальности и т.п., распределение промышленных предприятий по отраслям, размерам производства и т.п.). К рядам распределения близко примыкают и так называемые территориальные, или географические, ряды. Которые характеризуют распределение, какой либо совокупности по отдельным территориальным единицам.
Если единицы совокупности наблюдаются в течение длительного периода, то они могут быть систематизированы по времени. Получаемые в результате такой систематизации данные именуют рядами динамики.
Анализ различного рода рядов распределения и рядов динамики составляет основу статистического анализа, направленного на выявление статистических закономерностей.
2. Задачи группировок и их значение в статистическом исследовании
Сводка статистических данных производится таким образом, чтобы наиболее существенные различия между группами не затушёвывались а, наоборот, выделялись с целью их изучения. В то же время объединение в группы сходных между собой однотипных явлений помогает выявить такие их черты и особенности, которые при изучении отдельно каждого явления могли бы остаться незамеченными. Следовательно, научное исследование массовых общественных явлений невозможно без разграничения групп, существенно различающихся между собой, и объединения в группы явлений, сходных в существенном отношении. Поэтому статистическая группировка является основой научной сводки.
В то же время объединение в группы сходных между собой однотипных явлений помогает выявить такие их черты и особенности, которые при изучении отдельно каждого явления могли бы остаться незамеченными. Следовательно, научное исследование массовых общественных явлений невозможно без разграничения групп, существенно различающихся между собой, и объединения в группы явлений, сходных в существенном отношении. Поэтому статистическая группировка является основой научной сводки.
Статистическая группировка представляет собой расчленение совокупностей общественных явлений на однородные, типичные группы по существенным для них признакам. Группировка является центральным моментом любой сводки. Именно благодаря группировкам материал наблюдения принимает систематизированный вид. Способствуя выявлению наиболее существенных черт и признаков изучаемых явлений, выделению и характеристике основных общественно-экономических явлений, типов предприятий, хозяйств и групп населения, метод группировок служит вместе с тем основой научного применения других методов статистики — средних величин, индексов и т. д. С помощью абсолютных, относительных, средних величин или индексов можно правильно характеризовать только однородные, однотипные группы явлений, выделенные в состав изучаемой совокупности методом группировок.
д. С помощью абсолютных, относительных, средних величин или индексов можно правильно характеризовать только однородные, однотипные группы явлений, выделенные в состав изучаемой совокупности методом группировок.
Важнейшей задачей статистических группировок является выделение существующих в действительности общественно-экономических типов явлений. На основе теоретического анализа изучаемой совокупности явлений выделяются главные, наиболее характерные группы, типы явлений, из которых она состоит, определяются существенные различия между ними, а также признаки, являющиеся общими для каждой группы. К числу таких группировок относятся группировки предприятий и хозяйств по формам собственности, группировка населения по общественным группам, группировка предприятий и организаций по отраслям народного хозяйства и др.
Признаки, положенные в основу группировки, называются группировочными, а группировка единиц совокупности по тому или иному признаку приводит к рядам распределения.
Таким образом, метод группировок даёт возможность глубоко изучать общественные явления, отражать действительность такой, какой она есть, во всей её сложности и переплетении существенных черт и особенностей.
3. Виды группировок
Группировка — это процесс образования групп единиц совокупности, однородных в каком либо существенном отношении, а также имеющих одинаковые или близкие значения группировочного признака.
Для осуществления статистической группировки устанавливают признак, по которому единицы совокупности распределяют по группам, число групп и их обозначение (границы). Каждая единица совокупности в зависимости от значения у неё группировочного признака
Группировочные признаки могут иметь количественное выражение (например, возраст, заработная плата, число детей в семье, урожайность отдельных сельскохозяйственных культур и т.д.). Эти признаки называются количественными, а ряды распределения, построенные по этим признакам, называются вариационными рядами.
Другие признаки не имеют количественного выражения. Они отражают определённые свойства, качества единиц совокупности. Эти признаки условно называют качественными (например, пол, национальность, семейное положение и т.п.). Группировки, построенные по таким качественным признакам, называют атрибутивными рядами распределения.
Эти признаки условно называют качественными (например, пол, национальность, семейное положение и т.п.). Группировки, построенные по таким качественным признакам, называют атрибутивными рядами распределения.
Группировки, при помощи которых выявляется взаимосвязь между явлениями, называют аналитическими. При построении таких группировок, прежде всего из двух взаимосвязанных один рассматривается как фактор (т.е. влияющий на другой), а второй — как результат влияния первого. Однако следует иметь в виду, что понятие факторного и результативного признаков рассматривается для каждого конкретного случая особо, ибо то, что служит факторным признаком в одном случае, в другом может выступать как результативный.
Чтобы при помощи группировки выявить зависимость между показателями, необходимо разгруппировать единицы совокупности по факторному признаку и для каждой выделенной группы рассматривать среднее значение результативного показателя, а затем проследить за изменением последнего от группы к группе. Примером может служить группировка фермерских хозяйств по площади земельных угодий. Статистическую группировку можно строить как по одному, так и по нескольким признакам. Группировка по одному признаку называется простой. Группировка по нескольким признакам называется комбинационной. Комбинационные группировки приобретают особое значение в тех случаях, когда для выделения отдельных групп особенно социальных типов и форм явлений одного признака бывает недостаточно. Тогда приходится один признак брать в сочетании с другими. В статистической практике широко применяются вторичные группировки, к которым относятся группировки, которые формируются на уже обработанном ранее статистическом материале, т.е. в данном случае происходит перегруппировка уже ранее сгруппированного материала. К вторичной группировке прибегают тогда: когда из большого числа первоначально обработанных групп надо получить меньшее число более крупных, более характерных групп; когда в целях сравнения нужно привести в сопоставимый вид по-разному сгруппированный материал.
Примером может служить группировка фермерских хозяйств по площади земельных угодий. Статистическую группировку можно строить как по одному, так и по нескольким признакам. Группировка по одному признаку называется простой. Группировка по нескольким признакам называется комбинационной. Комбинационные группировки приобретают особое значение в тех случаях, когда для выделения отдельных групп особенно социальных типов и форм явлений одного признака бывает недостаточно. Тогда приходится один признак брать в сочетании с другими. В статистической практике широко применяются вторичные группировки, к которым относятся группировки, которые формируются на уже обработанном ранее статистическом материале, т.е. в данном случае происходит перегруппировка уже ранее сгруппированного материала. К вторичной группировке прибегают тогда: когда из большого числа первоначально обработанных групп надо получить меньшее число более крупных, более характерных групп; когда в целях сравнения нужно привести в сопоставимый вид по-разному сгруппированный материал.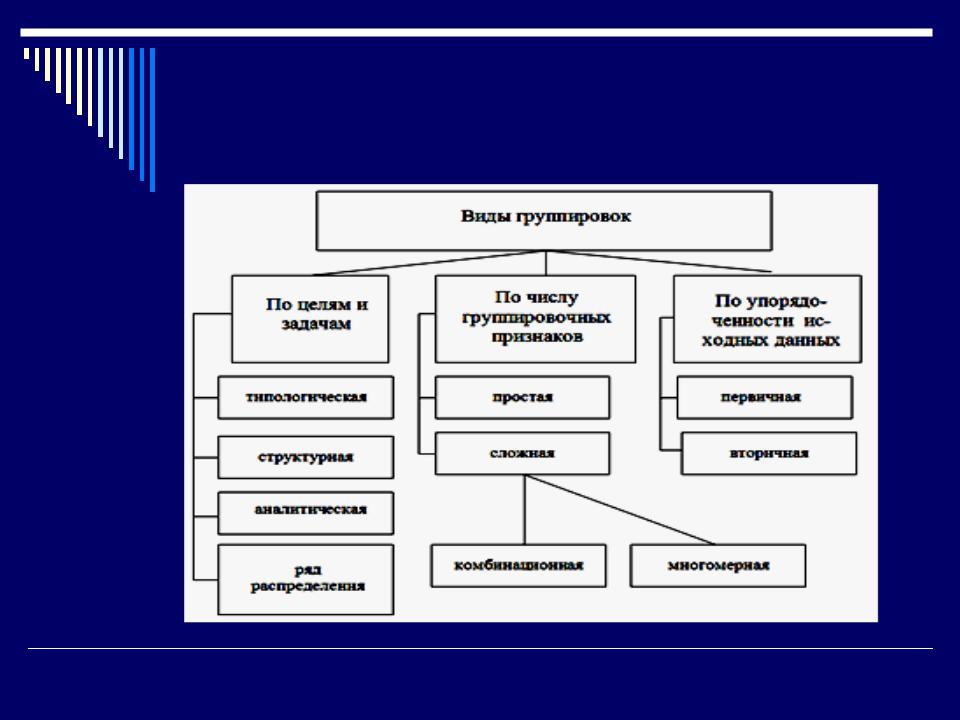
4. Суть и виды статистических группировок
В результате первой стадии статистических исследований (статистического наблюдения) получают статистическую информацию, представляющую собой большое количество первичных, разрозненных сведений об отдельных единицах объекта исследования (например, записи о каждом гражданине страны при переписи населения: пол, национальность, возраст, образование и др.).
Дальнейшая задача статистики заключается в этом, чтобы привести эти материалы в определенный порядок, систематизировать и на этой основе дать сводную характеристику всей совокупности фактов для того, чтобы изучить характерные черты и отличительные особенности изучаемого явления и выявить закономерности его развития. Это достигается на второй стадии статистического исследования, первой ступенью которой является статистическая сводка.
Статистическая сводка – это научно организованная обработка первичных данных в целях получения обобщающих характеристик изучаемого явления по ряду существенных для него признаков.
Сводка и группировка статистических данных
Содержание
Введение…………………………………………………………
- Сводка и группировка статистических данных…………………………….4
- Содержание сводки, виды сводки, элементы сводки………………….4
- Сущность и классификация группировки статистических данных……6
- Основные правила образования групп…………………………………11
- Ряды распределения……………………………………………
……….14 - Статистические таблицы………………………………………………..16
2. Практическая часть………………………………………………………….18
Заключение……………………………………………………
Список литературы……………………………………………………
Введение
В курсовой работе рассматриваются первый
и исходный этап статистического исследования,
который включает сбор статистической
информации (статистическое наблюдение)
и ее обработку в виде сводки, группировки,
таблиц и графиков. Объектами изучения являются также ряды распределения
и наиболее широко используемые в статистике
различные абсолютные и относительные
показатели.
Объектами изучения являются также ряды распределения
и наиболее широко используемые в статистике
различные абсолютные и относительные
показатели.
Целью курсовой работы является рассмотрение понятия сводки и группировки статистических данных.
Задачи курсовой работы:
- Рассмотреть содержание, виды и элементы сводки
- Определить задачи, решаемые с помощью статистических группировок
- Обосновать виды группировок и технику их проведения
- Раскрыть назначение и содержание статистических таблиц
- Обосновать аналитические возможности рядов распределения как составной части статистической сводки
- Рассмотреть виды рядов распределения и особенности их построения
- Рассмотреть графическое изображение рядов распределения
1. Сводка и группировка статистических данных
1.1 Содержание сводки, виды сводки, элементы сводки
Сводка – научно организованная обработка
материалов наблюдения (по заранее разработанной
программе), включающая в себя кроме обязательного
контроля собранных данных, систематизацию,
группировку материалов, составление
таблиц, получение итогов по группам и
в целом. Программа сводки включает определение
групп и подгрупп, системы показателей
и видов таблиц.
Программа сводки включает определение
групп и подгрупп, системы показателей
и видов таблиц.
Статистическая сводка — научная обработка первичных данных в целях получения обобщенных характеристик изучаемого явления по ряду существенных для него признаков.
По глубине и точности обработки материала различают сводку простую и сложную.
Простая статистическая сводка – это операция по подсчету общих итоговых и групповых данных непосредственно по совокупности единиц наблюдения и оформление этого материала в таблицах.
Сложная статистическая сводка – это комплекс операций, включающих распределение единиц и наблюдения изучаемого социально-экономического явления или процесса на группы, составление системы показателей для характеристики типичных групп и подгрупп изучаемых совокупности явлений, подсчет числа единиц и итогов в каждой группе и подгруппах и оформление результатов этой работы в виде статистических таблиц.
По форме обработки материала сводка
бывает децентрализованной и централизованной.
Децентрализованная статистическая сводка – это специфический способ организации сводки статистических данных. Он состоит в том, что обработка данных производится на местах. Материал разрабатывается поэтапно по мере укрупнения территории и позволяет более оперативно получить результаты сводки. Однако это ограничивает возможности применения группировок.
Централизованная статистическая сводка – это способ организации сводки статистических данных, при котором все первичные данные, полученные в результате статистического наблюдения, сосредотачиваются в одной центральной организации и подвергаются в ней обработке от начала до конца.
По технике выполнения статистическая сводка бывает механизированная (с использованием электронно-вычислительной техники) и ручная.
В результате сводки первичные материалы
образуют статистические совокупности,
которые характеризуются абсолютными
обобщающими показателями. В дальнейшем
на основе сводных итогов рассчитывают
и другие обобщающие показатели (средние
и относительные величины) и различные
методы статистического анализа.
Неумелая сводка может привести к тому, что сущность изучаемого явления может исчезнуть, потеряться в ней. Чтобы этого не случилось, следует руководствоваться научно обоснованным учением о законах развития данного явления.
Составными элементами сводки являются:
1) программа, определяющая группировки,
которые будут применяться в
разработке, и систему показателей,
характеризующих совокупность
2) подсчет групповых и общих итогов;
3) оформление конечных
Программа сводки содержит перечень групп, на которые может быть разбита или разбивается совокупность единиц наблюдения, а также систему показателей, характеризующих изучаемую совокупность явлений и процессов как в целом, так и отдельных ее частей.
1.2. Сущность и классификация
группировки статистических
Группировка – разбиение совокупности
на группы, однородные по какому-либо признаку
или объединение отдельных единиц совокупности
в группы, однородные по каким-либо признакам. Устойчивое разграничение объектов называется
классификацией или стандартом, в котором
каждая атрибутивная запись может быть
отнесена лишь к одной группе или подгруппе.
Метод группировки основывается на двух
категориях – группировочном признаке
и интервале.
Устойчивое разграничение объектов называется
классификацией или стандартом, в котором
каждая атрибутивная запись может быть
отнесена лишь к одной группе или подгруппе.
Метод группировки основывается на двух
категориях – группировочном признаке
и интервале.
Варьирующими признаками единиц совокупности называются признаки, принимающие разное значение (качественное или количественное) у отдельных единиц совокупности.
Признаки, принимающие качественное значение (пол, образование, специальность), называются атрибутивными, а признаки, которые варьируют количественно (стаж работы, заработная плата), – количественными.
С помощью метода группировок решают ряд задач, среди которых выделяются четыре:
- разделение совокупности на качественно однородные группы (выделение социально-экономических типов) – типологические группировки;
- изучение состава совокупности по тем или иным признакам – структурные группировки;
- изучение взаимосвязанного изменения варьирующих признаков в пределах той или иной совокупности – аналитические группировки;
- распределение единиц совокупности по
двум взаимосвязанным признакам, взятым
в комбинации — корреляционные группировки.

Важнейшие проблемы:
1) Определение группировочного признака (основания группировки).
2) Выделение числа групп.
3) Интервал
Группировочный признак – признак, по которому происходит объединение отдельных единиц совокупности в однородные группы. Он может носить как количественный, так и качественный характер. В ряде случаев группировка, которая представляется чисто качественной, в конечном итоге оказывается основанной на количественном признаке. Такова, например, классификация промышленных предприятий по отраслям. Поскольку одно и то же предприятие выпускает продукцию разных видов, статистика решает этот вопрос по количественному преобладанию того или иного вида.
Интервал
очерчивает количественные границы групп
и представляет собой промежуток между
максимальным и минимальным значениями
признака в группе. Интервалы бывают равные,
неравные, закрытые (когда имеется верхняя
и нижняя граница) и открытые (когда одна
из границ
отсутствует).
Виды группировок:
- Типологические группировки
Типологические группировки
— это разделение разнородной
совокупности на классы
Их задача – выявление социально-экономических типов или однородных в существенном отношении групп.
№ п/п | Социально-экономические типы | Мужчины 1980 1992 | Женщины 1980 1992 | ||
1 | Работники | — | — | — | — |
2 | Крестьяне | — | — | — | — |
3 | Служащие | — | — | — | — |
- Структурные группировки
Структурная группировка – это расчленение однородной
в качественном отношении совокупности
единиц по определенным, существенным
признакам на группы, характеризующие
ее состав и структуру. Структурные группировки
применяются практически в изучении всех
социально-экономических процессов и
явлений. При построении структурной группировки
в качестве группировочных признаков
могут выступать как количественные, так
и атрибутивные (качественные) признаки
Структурные группировки
применяются практически в изучении всех
социально-экономических процессов и
явлений. При построении структурной группировки
в качестве группировочных признаков
могут выступать как количественные, так
и атрибутивные (качественные) признаки
Практическое применение структурных группировок позволяет на локальном уровне раскрыть структуру совокупности, проанализировать изучаемые явления и процессы, изменения состава совокупности во времени, если они прослеживаются за ряд последовательных периодов времени.
Их задача – изучение состава отдельных типических групп при помощи объединения единиц совокупности, близких друг к другу по величине группировочного признака.
№ п/п | Количество посадочных мест | Количество столов | Число занятых | Товарооборот на 1 место |
1 | До 25 | — | — | — |
2 | 16-50 | — | — | — |
3 | 51-70 | — | — | — |
4 | 71-100 | — | — | — |
- Аналитические группировки
Аналитическая группировка – это группировка, выявляющая взаимосвязи
и взаимозависимости между изучаемыми
социально-экономическими явлениями и
признаками их характеризующими.
В статистике все признаки делятся на факторные и результативные.
Факторные признаки – это признаки, которые оказывают влияние на изменение результативных признаков.
Результативные признаки – это признаки, которые изменяются под влиянием факторных признаков. Взаимосвязь проявляется в том, что с возрастанием роли факторного признака и под его влиянием более интенсивно изменяется результативный признак.
Особенности аналитической группировки состоят в том, что единицы совокупности группируются по факторному признаку, а расчет групповых средних производится по значениям результативного признака.
Их задача – выявления влияния одних признаков на другие ( выявить связь
между социально-экономическими явлениями).
№ п/п | Группы магазинов по числу рабочих мест | Число магазинов | Товарооборот | |
На 1 работника | На 1 раб место | |||
1 | До 5 | 100 | 12,0 | 13,0 |
2 | 6-10 | 50 | 14,0 | 16,0 |
3 | 11-15 | 10 | 15,0 | 17,0 |
4 | 16-20 | 4 | 30,0 | 39,0 |
5 | 21-25 | 2 | 31,0 | 42,0 |
4) Комбинационные группировки
Образование групп по двум и
более признакам, взятым в определенном
сочетании, называется комбинированной
группировкой. При этом группировочные
признаки принято располагать, начиная
с атрибутивного, в определенной последовательности, исходя
из логики взаимосвязи показателей. Группы,
образованные по одному признаку, разбиваются
на подгруппы по другому признаку.
При этом группировочные
признаки принято располагать, начиная
с атрибутивного, в определенной последовательности, исходя
из логики взаимосвязи показателей. Группы,
образованные по одному признаку, разбиваются
на подгруппы по другому признаку.
Применение комбинированных группировок обусловлено многообразием экополитических явлений, а также необходимостью их всестороннего изучения. Но увеличение числа группировочных признаков ограничивается уменьшением наглядности, что снижает эффективность использования статистической информации. Примером комбинированной группировки может служить разделение образованных групп по формам хозяйствования на подгруппы по уровню рентабельности или по другим признакам (производительность труда, фондоотдача и т.д.).
Задачи определяют, что изучается при визуальном статистическом обучении.
Методы обобщают вместе 4 эксперимента. Все процедуры были утверждены Наблюдательным советом Университета Делавэра.
Участников
участника (эксперимент 1: N = 20, эксперимент 2: N = 30, эксперимент 3: N = 25) были студентами Университета Делавэра и были набраны онлайн через Amazon Mechanical Turk (эксперимент 4: N = 104), сообщали нормально или исправили- до нормальной остроты зрения и цветового зрения.Им была выплачена компенсация в виде кредита или наличных и предоставлено информированное согласие.
Аппарат
В экспериментах1-3 использовались компьютеры под управлением Linux с 17-дюймовыми ЭЛТ-мониторами (разрешение: 1280 x 1024 при 75 Гц), работающие с MATLAB 2015a (Mathworks; Натик, Массачусетс) с Psychophysics Toolbox 3 (Brainard, 1997; Kleiner et al., 2007; Пелли, 1997). Участники сидели на расстоянии ~ 54 см от экрана и отвечали через клавиатуру. В эксперименте 4 веб-браузер и компьютер участника использовали jsPsych 5.0.3 (de Leeuw, 2015) и Psiturk (Gureckis et al., 2016).
Стимулы
изображений лиц были получены из базы данных FERET (Phillips, Wechsler, Huang, & Rauss, 1998) и были обрезаны для минимизации фона. Сюжетные фотографии были собраны из Интернета и изображали внутренние и внешние сцены. Изображения были 200 x 200 пикселей (приблизительно 5,3 ° x 5,3 °).
Процедуры
Участники завершили ознакомительную фазу, за которой последовала фаза неожиданного признания в 1-часовых занятиях.
Этап ознакомления
Перед ознакомлением случайным образом были заданы 16 пар изображений AB, (32 «парных» изображения) (рис. 1a): A всегда предшествовали B во время ознакомления. Пары были определены таким образом, чтобы существовала одна уникальная комбинация самки, самца, внутреннего и внешнего вида (например, 4 пары состояли из разных самок ( A, ), за которыми следовали ( B) женщина / самец / внутренний / внешний вид).Для экспериментов 1-3 также появилось 16 непарных «одноэлементных» изображений (по 4 на каждый тип изображения). Все изображения появлялись 4 раза в каждом из 5 блоков, в каждом блоке 192 испытания (Эксперименты 1-3; Рисунок 1b) и 128 испытаний (Эксперимент 4, который исключал одиночные попытки во время ознакомления). Последовательности были псевдо-рандомизированы, поэтому пары никогда не повторялись сразу. Изображения появлялись в течение 1 с с ITI, равным 1 с. Желтый круговой маркер фиксации рамки был наложен на центр, оставаясь присутствующим во время ITI.
Рисунок 1.(a) Пример пары AB для одного предмета. Не показано: 16 одноэлементных элементов (по 4 каждого типа), которые не были предсказуемыми или предсказуемыми в обучающей последовательности (одиночные элементы не появлялись в эксперименте 4). (b) Пример пробной последовательности из обучающей последовательности. Цветные контуры предназначены для изображения класса пары и не показывались испытуемым. Каждое изображение появлялось на 1 секунду, а ISI — на 1 секунду. Желтый круг фиксации появился на изображениях и в период ISI (не показан). Круг стал зеленым после правильного ответа и красным после неправильного.Испытания после первого испытания в блоке были классифицированы в соответствии с их отношением к предыдущему испытанию (требуется та же / другая задача и тот же / другой ответ) и их членством (или нет) в парном наборе, что делало их непредсказуемыми или предсказуемыми. (c) Пример стадии признания.
Для эксперимента 1 участники классифицировали изображения как женские / внутренние с помощью клавиши «z» и левой рукой или мужские / внешние с помощью клавиши «m» и правой руки.Для эксперимента 2 единственное отличие заключалось в том, что использовались клавиши «n» и «m», и участники использовали два пальца одной руки, чтобы убедиться, что эффекты реакции не зависят от использования разных рук. Мы поощряли точность и быстрые ответы, которые были приняты в пределах 2-секундного интервала от начала стимула. Правильные и ошибочные ответы привели к тому, что маркер фиксации стал зеленым или красным, соответственно, до конца ITI.
В эксперименте 3 участники наблюдали за изображениями и нажимали клавишу пробела, когда изображение «мигало».”Для 25% презентаций изображение на короткое время отключается (53,3 мс) через 453,3 мс. Ответы, возникающие до появления следующего стимула, были попаданиями.
В эксперименте 4 участников случайным образом распределили по группам. Группа категоризации выполнила задачу, описанную в эксперименте 1, за исключением того, что сопоставления мужского / женского пола и внутреннего / наружного с ключами «z» и «m» были рандомизированы среди участников. Группа обнаружения отслеживала потоки изображений на предмет «покачивания» событий, происходящих один раз для каждого изображения в блоке, и нажимала пробел при возникновении покачивания.Колебания возникали в несмежных парах и начинались через 300 мс после представления изображения с 2 циклами смещения на 5 пикселей влево / вправо от центра, каждый цикл занимал 200 мс. Участники получили больше отзывов (например, «Ошибка — нажмите клавишу Z для выхода на улицу, клавишу M для помещения»; 3000 мс), чтобы учесть возможное невнимание во время инструкций. Участники завершили ознакомительную фазу из 32 испытаний с изображениями, которые не использовались повторно.
Фаза распознавания
Фаза распознавания состояла из 64 испытаний с принудительным выбором, в которых целевая пара сравнивалась с фольгированной парой (представленной с тем же временем, что и ознакомление, и предшествовавшим 0.Этикетка с порядковым номером, равная 5 с, за которой следует пробел 0,5 с). Перед этим этапом участники были проинформированы о AB парах и указали, какая последовательность появилась во время ознакомления. Испытания проходили в индивидуальном темпе, ответы не были скоростными, и никакой обратной связи предоставлено не было.
Пары фольги имели тот же состав, что и мишени, но были рекомбинированы из элементов A и B . Изображения A и B в парах из фольги постоянно оставались в позиции A или B , но менялись местами между парами.Все пары мишени и фольги появлялись четыре раза во время фазы распознавания.
Критерии исключения
S6 Мы исключили из анализа участников с точностью ознакомления <80% (Эксперименты 1-2, группа классификации эксперимента 4) или с частотой ложных тревог / промахов> 20% во время ознакомления (Эксперимент 3, Группа обнаружения эксперимента 4). Один участник был исключен из экспериментов 1 и 2, а четверо — из эксперимента 3.В эксперименте 4 двое были исключены из группы классификации и ни одного из группы обнаружения.
Использование Excel для анализа данных
Использование Excel для анализа данныхИспользование Excel для статистического анализа данных — предостережения
Ева Голдуотер
Консультационный центр биостатистики
Школа общественного здравоохранения Массачусетского университета
обновлено: февраль 2007 г.,
Краткий обзор
Введение
Общие вопросы
Результаты анализа
Резюме
Мы использовали Excel для выполнения некоторых основных задач анализа данных, чтобы увидеть, является ли это разумной альтернативой использованию статистического пакета для тех же задач.Мы пришли к выводу, что Excel — плохой выбор для статистического анализа, помимо примеров из учебников, простейшей описательной статистики или для более чем нескольких столбцов. Проблемы, с которыми мы столкнулись, которые привели к такому выводу, относятся к четырем основным направлениям:
- Отсутствующие значения обрабатываются непоследовательно, а иногда и неправильно.
- Организация данных различается в зависимости от анализа, что вынуждает вас реорганизовать данные разными способами, если вы хотите провести много разных анализов.
- Многие анализы могут выполняться только для одного столбца за раз, что затрудняет выполнение одного и того же анализа для нескольких столбцов.
- Вывод плохо организован, иногда неправильно маркирован, и нет записи о том, как был проведен анализ.
Excel удобен для ввода данных и быстрого управления строками и столбцами перед статистическим анализом. Однако, когда вы будете готовы провести статистический анализ, мы рекомендуем использовать статистический пакет, такой как SAS, SPSS, Stata, Systat или Minitab.
Excel, вероятно, является наиболее часто используемой электронной таблицей для ПК. Недавно приобретенные компьютеры часто поставляются с уже загруженным Excel. Его легко использовать для выполнения различных расчетов, он включает набор статистических функций и пакет инструментов для анализа данных. В результате, если вы вдруг обнаружите, что вам нужно провести статистический анализ, вы можете обратиться к нему как к очевидному выбору. Мы решили провести небольшое тестирование, чтобы увидеть, насколько хорошо Excel будет служить приложением для анализа данных.
Чтобы представить результаты, мы будем использовать небольшой пример. Данные для этого примера вымышлены. Было выбрано две категориальные и две непрерывные переменные, чтобы мы могли протестировать множество основных статистических методов. Поскольку почти во всех реальных наборах данных есть по крайней мере несколько недостающих точек, и поскольку способность правильно обрабатывать отсутствующие данные является одной из функций, которые мы принимаем как должное в пакете статистического анализа, мы ввели две пустые ячейки в данные:
Лечение | Результат | Х | Я |
1 | 1 | 10.2 | 9,9 |
1 | 1 | 9,7 | |
2 | 1 | 10,4 | 10,2 |
1 | 2 | 9.8 | 9,7 |
2 | 1 | 10,3 | 10,1 |
1 | 2 | 9,6 | 9,4 |
2 | 1 | 10.6 | 10,3 |
1 | 2 | 9,9 | 9,5 |
2 | 2 | 10,1 | 10 |
2 | 2 | 10.2 |
Каждая строка таблицы представляет тему. Первый субъект получил лечение 1 и имел Результат 1. X и Y — значения двух измерений для каждого субъекта. Нам не удалось получить измерение Y для второго объекта или X для последнего объекта, поэтому эти ячейки пусты. Субъекты вводятся в том порядке, в котором данные стали доступны, поэтому данные не упорядочены каким-либо определенным образом.
Мы использовали эти данные, чтобы провести простой анализ и сравнить результаты со стандартным статистическим пакетом.При сравнении учитывалась точность результатов, а также простота использования интерфейса для больших наборов данных, т. Е. Большего количества столбцов. Мы использовали SPSS в качестве стандарта, хотя любой из статистических пакетов, поддерживаемых OIT, также подходит для этой цели. В этой статье, когда мы говорим «статистический пакет», мы имеем в виду SPSS, SAS, STATA, SYSTAT или Minitab.
Большинство статистических процедур Excel являются частью пакета инструментов анализа данных, который находится в меню «Инструменты».Он включает в себя множество вариантов, включая простую описательную статистику, t-тесты, корреляции, одно- или двусторонний дисперсионный анализ, регрессию и т. Д. Если у вас нет пункта «Анализ данных» в меню «Инструменты», вам необходимо установить «Данные». Пакет инструментов анализа. Найдите в справке «Инструменты анализа данных» инструкции по загрузке ToolPak.
Две другие функции Excel полезны для определенного анализа, но пакет инструментов анализа данных — единственный, который обеспечивает достаточно полные тесты статистической значимости.Сводную таблицу в меню «Данные» можно использовать для создания сводных таблиц средних значений, стандартных отклонений, подсчетов и т. Д. Кроме того, вы можете использовать функции для создания некоторых статистических показателей, таких как коэффициент корреляции. Функции генерируют одно число, поэтому, используя функции, вам, вероятно, придется комбинировать кусочки и кусочки, чтобы получить то, что вы хотите. Даже в этом случае вы не сможете создать все части, необходимые для полного анализа.
Если не указано иное, все статистические тесты с использованием Excel проводились с помощью пакета Data Analysis ToolPak.Для проверки различных статистических тестов мы выбрали следующие задачи:
- Получите средние и стандартные отклонения X и Y для всей группы и для каждой экспериментальной группы.
- Получите корреляцию между X и Y.
- Выполните двухвыборочный t-тест, чтобы проверить, различаются ли две группы лечения по X и Y.
- Проведите парный t-тест, чтобы проверить, отличаются ли X и Y статистически друг от друга.
- Сравните количество субъектов с каждым результатом по группам лечения, используя критерий хи-квадрат.
Все эти задачи являются стандартными для набора данных такого рода, и все они могут быть легко выполнены с использованием любого из перечисленных выше статистических пакетов.
Включить пакет инструментов анализа
Пакет Data Analysis ToolPak не устанавливается со стандартной установкой Excel. Посмотрите в меню «Инструменты». Если у вас нет элемента анализа данных, вам необходимо установить инструменты анализа данных.Для получения инструкций поищите в справке «Инструменты анализа данных».
Отсутствующие значения
Пустая ячейка — единственный способ для Excel обработать недостающие данные. Если у вас есть другие коды отсутствующих значений, вам нужно будет заменить их пустыми.
Организация данных
Для разных анализов необходимо, чтобы данные были упорядочены по-разному. Если вы планируете проводить множество различных тестов, возможно, не будет какой-либо единой схемы, которая будет работать. Возможно, вам придется переставить данные несколькими способами, чтобы получить все, что вам нужно.
Диалоговые окна
Выберите Инструменты / Анализ данных и выберите тип анализа, который вы хотите провести. Типичное диалоговое окно будет содержать следующие элементы:
Диапазон ввода: введите верхний левый и нижний правый угол ячейки. например A1: B100. Вы можете выбирать только соседние строки и столбцы. Если не установлен флажок для группировки данных по строкам или столбцам (а его обычно нет), все данные рассматриваются как один глобус.
Ярлыки. Иногда можно установить флажок, чтобы указать, что первая строка вашего листа содержит ярлыки.Если у вас есть метки в первой строке, установите этот флажок, и ваш результат МОЖЕТ быть помечен вашей меткой. Опять же, это не может быть.
Место вывода — по умолчанию используется новый лист. Или введите адрес ячейки в верхнем левом углу того места, где вы хотите разместить вывод на текущем листе. Новый рабочий лист — еще один вариант, который я не пробовал. Разветвления этого выбора обсуждаются ниже.
Остальные предметы, в зависимости от анализа.
Расположение выхода
Выходные данные каждого анализа могут быть перенесены на новый лист в текущем файле Excel (это значение по умолчанию), или вы можете поместить его в текущий лист, указав ячейку в верхнем левом углу, где вы хотите, чтобы она была размещена.В любом случае это немного неудобно. Если каждый вывод находится на новом листе, вы получаете много листов, на каждом из которых выводится небольшой бит. Если вы разместите их на текущем листе, вам нужно будет разместить их соответствующим образом; оставьте место для добавления комментариев и меток; изменения, которые необходимо внести для правильного форматирования одного вывода, могут отрицательно повлиять на другой вывод. Пример: в выходных данных Descriptives есть столбец с метками, такими как «Стандартное отклонение», «Стандартная ошибка» и т. Д. Вы захотите сделать этот столбец широким, чтобы можно было читать метки.Но если простой выход Frequency находится прямо под ним, тогда столбец, отображающий подсчитываемые значения, который может содержать только небольшие целые числа, также будет широким.
Описательная статистикаСамый быстрый способ получить средние значения и стандартные отклонения для всей группы — использовать описательные элементы в инструментах анализа данных. Вы можете выбрать несколько соседних столбцов для диапазона ввода (в данном случае столбцы X и Y), и каждый столбец будет анализироваться отдельно.Метки в первой строке используются для маркировки вывода, а пустые ячейки игнорируются. Если у вас есть больше несмежных столбцов, которые вам нужно проанализировать, вам придется повторить процесс для каждой группы смежных столбцов. Процедура проста, позволяет достаточно эффективно управлять множеством столбцов, а пустые ячейки обрабатываются должным образом.
Чтобы получить средние значения и стандартные отклонения X и Y для каждой группы лечения, необходимо использовать сводные таблицы (если вы не хотите переупорядочить лист данных, чтобы разделить две группы).После выбора (непрерывного) диапазона данных в параметре «Макет» мастера сводных таблиц перетащите «Обработка» в область переменных строки, а X — в область «Данные». Дважды щелкните «Count of X» в области данных и измените его на «Среднее». Снова перетащите X в поле данных и на этот раз измените Count на StdDev. Наконец, перетащите X еще раз, оставив его как Count of X. Это даст нам Среднее, стандартное отклонение и количество наблюдений в каждой группе обработки для X. Сделайте то же самое для Y, чтобы мы получили среднее, стандартное отклонение и количество наблюдений для Y тоже.Это поместит в общей сложности шесть элементов в поле данных (три для X и три для Y). Как видите, если вы хотите получить разнообразную описательную статистику для нескольких переменных, процесс станет утомительным.
Статистический пакет позволяет вам выбрать любое количество переменных для описательной статистики, независимо от того, являются ли они смежными или нет. Вы можете получить описательную статистику по всем предметам вместе или с разбивкой по категориальной переменной, такой как лечение. Вы можете выбрать статистику, которую хотите просмотреть один раз, и она будет применяться ко всем выбранным переменным.
КорреляцииПри использовании инструментов анализа данных диалоговое окно для корреляций во многом похоже на диалог для описательных элементов — вы можете выбрать несколько смежных столбцов и получить выходную матрицу всех пар корреляций. Пустые ячейки игнорируются соответствующим образом. Выходные данные НЕ включают количество пар точек данных, используемых для вычисления каждой корреляции (которое может варьироваться в зависимости от того, где у вас отсутствуют данные), и не указывает, являются ли какие-либо из корреляций статистически значимыми.Если вам нужны корреляции для несмежных столбцов, вам придется либо включить промежуточные столбцы, либо скопировать нужные столбцы в смежное место.
Статистический пакет позволит вам выбирать несмежные столбцы для корреляций. Выходные данные сообщат вам, сколько пар точек данных использовалось для вычисления каждой корреляции и какие корреляции являются статистически значимыми.
Двухвыборочный Т-тестЭтот тест можно использовать для проверки, различаются ли две экспериментальные группы по значениям X или Y.Для проведения теста вам необходимо ввести диапазон ячеек для каждой группы. Поскольку данные не были введены по группе лечения, нам сначала нужно отсортировать строки по лечению. Обязательно возьмите все остальные столбцы вместе с лечением, чтобы данные по каждому предмету остались нетронутыми. . После сортировки данных вы можете ввести диапазон ячеек, содержащий измерения X для каждого лечения. Не включайте строку с метками, потому что вторая группа не имеет строки с метками. Поэтому ваш вывод не будет помечен, чтобы указать, что этот вывод предназначен для X.Если вы хотите, чтобы результат был помечен, вам нужно скопировать ячейки, соответствующие второй группе, в отдельный столбец и ввести строку с меткой для второй группы. Если вы также хотите провести t-тест для измерений Y, вам нужно будет повторить процесс. Пустые ячейки игнорируются, и, за исключением проблем с маркировкой вывода, результаты верны.
Статистический пакет выполнит эту задачу без необходимости сортировать данные или копировать их в другой столбец, а выходные данные всегда будут правильно помечены в той степени, в которой вы предоставляете ярлыки для своих переменных и групп лечения.Это также позволит вам выбрать более одной переменной за раз для t-теста (например, X и Y).
Парный t-тестПарный t-критерий — это метод проверки того, существенно ли отличается разница между двумя измерениями на одном и том же предмете от 0. В этом примере мы хотим проверить разницу между X и Y, измеренными на одном и том же предмете. Важной особенностью этого теста является то, что он сравнивает измерения в пределах каждого предмета.Если вы просканируете столбцы X и Y по отдельности, они не будут выглядеть явно по-разному. Но если вы посмотрите на каждую пару X-Y, вы заметите, что в каждом случае X больше, чем Y. Парный t-тест должен быть чувствителен к этой разнице. В двух случаях, когда отсутствует X или Y, невозможно сравнить две меры по предмету. Следовательно, для парного t-критерия можно использовать только 8 строк.
Когда вы запускаете парный t-тест для этих данных, вы получаете t-статистику 0,09 с вероятностью 2 хвостов, равной 0.93. Тест не обнаруживает какой-либо существенной разницы между X и Y. При более внимательном рассмотрении результатов мы замечаем, что в нем указано 9 наблюдений. Как отмечалось выше, их должно быть только 8. Похоже, что Excel не удалось исключить наблюдения, для которых не использовались измерения X и Y. Чтобы получить правильные результаты, скопируйте X и Y в два новых столбца и удалите данные в ячейках, которые не имеют значения для другой меры. Теперь повторно запустите парный t-тест. На этот раз t-статистика равна 6.14817 с 2-хвостовой вероятностью 0,000468. Вывод совершенно другой!
Конечно, это крайний пример. Но дело в том, что Excel неправильно вычисляет парный t-критерий, когда в некоторых наблюдениях есть одно из измерений, а другое нет. Хотя возможно получить правильный результат, у вас не будет причин подозревать полученные результаты, если только вы не будете достаточно внимательны, чтобы заметить, что количество наблюдений неверно. В интерактивной справке нет ничего, что могло бы предупредить вас об этой проблеме.
Интересно, что есть также функция TTEST, которая дает правильные результаты для этого примера. Очевидно, функции и инструменты анализа данных несовместимы в том, как они работают с отсутствующими ячейками. Тем не менее, я не могу рекомендовать использовать функции вместо инструментов анализа данных, потому что результатом использования функции является одно число — в данном случае вероятность с двумя хвостами t-статистики. Функция не предоставляет вам саму t-статистику, степени свободы или любое количество других элементов, которые вы хотели бы видеть, выполняя статистический тест.
Статистические пакеты будут правильно исключать случаи, когда одно из измерений отсутствует, и предоставят всю вспомогательную статистику, необходимую для интерпретации выходных данных.
Перекрестная таблица и критерий независимости хи-квадратНаша последняя задача — подсчитать два результата в каждой группе лечения и использовать критерий независимости хи-квадрат для проверки взаимосвязи между лечением и результатом.Чтобы подсчитать результаты по группам лечения, вам необходимо использовать сводные таблицы. В параметре «Макет» мастера сводных таблиц перетащите «Обработка» в строку, «Результат» в столбец, а также в «Данные». В области данных должно быть указано «Счетчик результатов» — если нет, дважды щелкните по нему и выберите «Счетчик». Если вам нужны проценты, дважды щелкните «Count of Outcome» и нажмите «Параметры»; в появившемся окне «Показать данные как» выберите «% строки». Если вам нужны и подсчеты, и проценты, вы можете дважды перетащить одну и ту же переменную в область данных и использовать ее один раз для подсчетов и один раз для процентов.
Однако пройти тест хи-квадрат не так-то просто. Он доступен только как функция, и входными данными, необходимыми для функции, являются наблюдаемые количества в каждой комбинации лечения и результата (которые у вас есть в вашей сводной таблице) и ожидаемые количества в каждой комбинации. Ожидаемые подсчеты? Кто они такие? Как их получить? Если у вас есть достаточный статистический фон, чтобы знать, как рассчитывать ожидаемые числа, и вы можете выполнять вычисления в Excel с использованием относительных и абсолютных адресов ячеек, вы должны иметь возможность перемещаться по ним.Если нет, то тебе не повезло.
Предполагая, что вы преодолели проблему ожидаемых чисел, вы можете использовать функцию Chitest, чтобы получить вероятность наблюдения значения хи-квадрат, большего, чем значение для этой таблицы. Опять же, поскольку мы используем функции, вы не получаете многих других необходимых частей вычислений, особенно значения статистики хи-квадрат или ее степеней свободы.
Ни один статистический пакет не потребует от вас предоставления ожидаемых значений перед вычислением критерия независимости хи-квадрат.Кроме того, результаты всегда будут включать статистику хи-квадрат и ее степени свободы, а также ее вероятность. Часто вы также получаете дополнительную статистику.
Остальные анализы по этому набору данных не проводились, но некоторые комментарии по ним включены для полноты.
Простые частоты
Для получения простых частот можно использовать сводные таблицы. (Подробнее о том, как получить сводные таблицы, см. в разделе «Перекрестные таблицы».) При использовании сводных таблиц каждый столбец рассматривается как отдельная переменная, и на выходе появляются метки в строке 1. Вы можете использовать только одну переменную за раз.
Другая возможность — использовать функцию «Частоты». Основное преимущество этого метода заключается в том, что после того, как вы определили функцию частот для одного столбца, вы можете использовать Копировать / Вставить, чтобы получить ее для других столбцов. Во-первых, вам нужно будет ввести столбец со значениями, которые вы хотите подсчитать (ячейки). Если вы собираетесь задать периодичность для многих столбцов, обязательно введите значения для столбца с наибольшим количеством категорий.например, если 3 столбца имеют значения 1 или 2, а четвертый имеет значения 1,2,3,4, вам нужно будет ввести значения ячеек как 1,2,3,4. Теперь выберите достаточно пустых ячеек в одном столбце для хранения результатов — 4 в этом примере, даже если текущий столбец имеет только 2 значения. Затем выберите в меню Вставка / Функция / Статистические данные / Частоты. Заполните диапазон ввода для первого столбца, который вы хотите подсчитать, используя относительные адреса (например, A1: A100). Заполните диапазон бункеров, используя абсолютные адреса мест, в которые вы ввели значения для подсчета (например,г. $ M $ 1: $ M $ 4). Щелкните Готово. Обратите внимание на поле над заголовками столбцов листа, где отображается формула. Он начинается с «= ЧАСТОТА («. Поместите курсор слева от знака = в формуле и нажмите Ctrl-Shift-Enter. Теперь в выбранных ячейках отображаются счетчики частоты.
Чтобы получить количество частот для других столбцов, выберите ячейки с частотами в них и выберите в меню «Правка / Копировать». Если следующий столбец, который вы хотите подсчитать, находится на один столбец справа от предыдущего, выберите ячейку справа от первой частотной ячейки и выберите «Правка / Вставить» (ctrl-V).Продолжайте перемещаться вправо и вставлять для каждого столбца, который вы хотите подсчитать. Каждый раз, когда вы перемещаете один столбец вправо от ячеек исходной частоты, столбец для подсчета сдвигается вправо от первого столбца, который вы подсчитали.
Если вам также нужны проценты, вам нужно будет использовать функцию Sum, чтобы вычислить сумму частот, и определить формулу, чтобы получить процент для одной ячейки. Выберите ячейку для хранения первого процента и введите формулу в поле формулы в верхней части листа — e.г. = N1 * 100 / N $ 5 — где N1 — это ячейка с частотой для первой категории, а N5 — это ячейка с суммой частот. Используйте Копировать / Вставить, чтобы получить формулу для оставшихся ячеек первого столбца. Когда у вас есть проценты для одного столбца, вы можете скопировать / вставить их в другие столбцы. Будьте осторожны при использовании относительных и абсолютных адресов! В приведенном выше примере мы использовали N $ 5 в качестве знаменателя, поэтому, когда мы копируем формулу до следующей частоты в том же столбце, она все равно будет искать сумму в строке 5; но когда мы копируем формулу прямо в другой столбец, она переходит к частотам в следующем столбце.
Наконец, вы можете использовать гистограмму в меню анализа данных. Вы можете использовать только одну переменную за раз. Как и в случае с функцией «Частоты», вы должны ввести столбец с границами «корзины». Чтобы подсчитать количество вхождений 1 и 2, вам нужно ввести 0,1,2 в трех соседних ячейках и указать диапазон этих трех ячеек как Бины в диалоговом окне. Вывод не помечен никакими ярлыками, которые могут быть в строке 1, или даже буквой столбца. Если вы делаете частоты для множества переменных, вам будет трудно понять, какая частота принадлежит какому столбцу данных.
Линейная регрессияПоскольку регрессия является одним из наиболее часто используемых статистических анализов, мы попробовали его, хотя мы не проводили регрессионного анализа для этого примера. Процедура регрессии в инструментах анализа данных позволяет выбрать один столбец в качестве зависимой переменной и набор смежных столбцов для независимых. Однако он не допускает пустых ячеек в любом месте входных диапазонов, и вы ограничены 16 независимыми переменными.Следовательно, если у вас есть пустые ячейки, вам нужно будет скопировать все столбцы, участвующие в регрессии, в новые столбцы и удалить все строки, содержащие пустые ячейки. Большие модели с более чем 16 предикторами вообще невозможны.
Дисперсионный анализ
В общем, возможности ANOVA в Excel ограничены несколькими частными случаями, которые редко встречаются за пределами учебников, и требуют большого количества перекомпоновок данных.
Односторонний дисперсионный анализ
Данные должны быть расположены в отдельных и смежных столбцах (или строках) для каждой группы.Ясно, что это не способствует выполнению односторонних действий более чем в одной группе. Если у вас есть метки в строке 1, в выводе будут использоваться метки.
Двухфакторный дисперсионный анализ без репликации
Это относится только к случаю , одно наблюдение на ячейку (то есть без члена ошибки внутри ячейки). Входной диапазон представляет собой прямоугольное расположение ячеек, где строки представляют уровни одного фактора, столбцы — уровни другого фактора, а ячейка содержит одно значение в этой ячейке.
Двухфакторный дисперсионный анализ с репликами
Это двусторонний дисперсионный анализ с равными размерами ячеек . Входные данные должны быть прямоугольной областью со столбцами, представляющими уровни одного фактора, и строками, представляющими реплики в пределах уровней другого фактора. Диапазон ввода ДОЛЖЕН также включать дополнительную строку вверху и столбец слева с метками, указывающими факторы. Однако эти метки не используются для маркировки результирующей таблицы ANOVA.Щелкните Help (Справка) в диалоговом окне ANOVA, чтобы увидеть, как должен выглядеть входной диапазон.
Запросы большого количества анализов
Если бы у вас было множество различных статистических процедур, которые вы хотели бы выполнить с вашими данными, вы почти наверняка обнаружили бы, что выполняете много операций по сортировке, перегруппировке, копированию и вставке ваших данных. Это связано с тем, что каждая процедура требует, чтобы данные были упорядочены определенным образом, часто отличным от того, как другая процедура хочет упорядочить данные.В нашем небольшом тесте нам пришлось отсортировать строки, чтобы выполнить t-тест, и скопировать некоторые ячейки, чтобы получить метки для вывода. Нам пришлось очистить содержимое некоторых ячеек, чтобы получить правильный парный t-тест, но мы не хотели, чтобы эти ячейки очищались для другого теста. А мы выполняли всего пять задач. Не становится лучше, когда ты пытаешься сделать больше. Не существует единого набора данных, который позволил бы вам выполнять множество различных анализов без создания множества различных копий данных.Необходимость манипулировать данными разными способами значительно увеличивает вероятность появления ошибок.
При использовании статистической программы данные обычно упорядочиваются по строкам, представляющим субъектов, и столбцам, представляющим переменные (как в нашем примере данных). С помощью такой схемы вы можете выполнять любой анализ, обсуждаемый здесь, а также многие другие, без необходимости каким-либо образом сортировать или переупорядочивать свои данные. Только гораздо более сложный анализ, выходящий за рамки возможностей Excel и объема данной статьи, потребует переупорядочения данных.
Что, если бы в ваших данных было не 4, а 40 столбцов со смесью категориальных и непрерывных показателей? Насколько легко описанные выше процедуры масштабируются до более серьезной проблемы?
В лучшем случае некоторые статистические процедуры могут принимать на вход несколько смежных столбцов и интерпретировать каждый столбец как отдельную меру. Процедуры описаний и корреляций относятся к этому типу, поэтому вы можете запросить описательную статистику или корреляции для большого количества непрерывных переменных, если они введены в соседние столбцы.Если они не смежные, вам нужно переставить столбцы или использовать копирование и вставку, чтобы сделать их смежными.
Однако многие процедуры могут применяться только к одному столбцу за раз. К этому классу относятся Т-тесты (независимые или парные), простой подсчет частоты, критерий независимости хи-квадрат и многие другие процедуры. Это стало бы серьезным недостатком, если бы у вас было больше, чем несколько столбцов, даже если вы использовали вырезать и вставить или макросы, чтобы уменьшить объем работы. Помимо многократного повторения запроса, вы должны решить, где хранить результаты каждого из них, и убедиться, что он правильно помечен, чтобы вы могли легко найти и идентифицировать каждый вывод.
Наконец, Excel не предоставляет вам журнал или другую запись для отслеживания ваших действий. Это может быть серьезным недостатком, если вы хотите иметь возможность повторить тот же (или аналогичный) анализ в будущем, или даже если вы просто забыли, что вы уже сделали.
Используя статистический пакет, вы можете запросить тест для любого количества переменных одновременно. Каждый из них будет правильно помечен и упорядочен на выходе, поэтому не будет путаницы в том, что к чему. Вы также можете рассчитывать на получение журнала, а часто и набора команд, которые можно использовать для документирования вашей работы или для повторения анализа без повторного прохождения всех этапов.
Хотя Excel представляет собой прекрасную электронную таблицу, это не пакет для статистического анализа данных. Честно говоря, это никогда не было задумано. Имейте в виду, что Data Analysis ToolPak — это «надстройка» — дополнительная функция, которая позволяет вам выполнять несколько быстрых вычислений. Поэтому неудивительно, что это как раз то, для чего он полезен — несколько быстрых вычислений. Если вы попытаетесь использовать его для более обширного анализа, вы столкнетесь с трудностями из-за любого или всех следующих ограничений:
- Возможные проблемы с анализом недостающих данных.Они могут быть коварными, поскольку неосторожный пользователь вряд ли поймет, что что-то не так.
- Отсутствие гибкости в анализе, который может быть выполнен из-за ожиданий относительно организации данных. Это приводит к необходимости вырезать / вставить / отсортировать / или иным образом переупорядочить лист данных различными способами, увеличивая вероятность ошибок.
- Вывод разбросан по множеству разных листов или по одному листу, и вы должны взять на себя ответственность за его разумную организацию.
- Вывод может быть неполным или может быть неправильно маркирован, что увеличивает вероятность неправильной идентификации вывода.
- Необходимо повторять запросы на некоторые анализы несколько раз, чтобы выполнить их для нескольких переменных или запросить несколько вариантов.
- Необходимо что-то делать, определяя свои собственные функции / формулы, с сопутствующим риском ошибок.
- Нет записей о том, что вы сделали для получения результатов, что затрудняет документирование вашего анализа или его повторение в более позднее время, если в этом возникнет необходимость.
Если у вас более 10 или 12 столбцов и / или вы хотите сделать что-либо, кроме описательной статистики и, возможно, корреляций, вам следует использовать статистический пакет. Есть несколько подходящих, доступных по лицензии на месте через OIT, или вы можете использовать их в любой из компьютерных лабораторий OIT. Если у вас есть Excel на вашем ПК и вы не хотите платить за статистическую программу, непременно используйте Excel для ввода данных (со строками, представляющими предметы, и столбцами для переменных).Все упомянутые статистические пакеты могут читать файлы Excel, поэтому вы можете выполнять (отнимающий много времени) ввод данных дома и идти в лабораторию для проведения анализа.
Гораздо более подробное обсуждение подводных камней использования Excel со множеством дополнительных ссылок доступно на http://www.burns-stat.com/. Щелкните «Учебники», затем «Зависимость от электронных таблиц».
Чтобы получить помощь или дополнительную информацию о статистическом программном обеспечении, свяжитесь с Консультационный центр биостатистики .Телефон 545-2949
Экран статистики пользователя> вкладка Задачи (классический)
Показывает сводку задач которые назначены пользователю, команде, отделу или группа в Классическом рабочем центре.
Рис.: Статистика пользователя — вкладка «Задачи»Предварительные требования
Полезно знать
Как начать
- Щелкните Рабочий центр.
- На экране рабочего центра щелкните Статистика пользователя.
- Щелкните вкладку Задача.
Поля
| Имя поля | Определение |
|---|---|
Посмотреть |
|
Быстрый статус задачи |
|
Скорость оборачиваемости |
|
Уровень процесса Производительность задачи |
|
Изменить макет |
|
Добавить вкладку |
|
Добавить отчет |
|
Удалить |
|
Скрыть вкладку |
|
Добавьте |
|
Сохранить |
|
Сброс |
|
| Предварительная программа | |||
| Информационная записка 1 | |||
| Отчет | |||
| Заключительный отчет для CES | |||
| Приветствие и вступительное слово ЕЭК ООН и председатели семинара 2021 года. Тэке Гьялтема (ЕЭК ООН) и дневной председатель семинара | |||
| Сессия 1: Управление и модернизация сбора данных | |||
| Организаторы заседания: Андреа Ашери (Евростат) и Паулу Сараива (Статистическое управление Португалии) | |||
| Интегрированная система сбора (ICS): модернизация сбора данных в Статистическом управлении Индонезии. Munaf, Alfatihah R.M.N.S.P; Budi , Brilian Surya; Ашиддики, Султони (Статистическое управление Индонезии) | Бумага | ||
| Процесс идентификации дома и на работе с использованием данных мобильного позиционирования. Нугрохо, Амин Ройс Синанг; Munaf, Alfatihah Reno M. N. S. P .; Маджида, Ва Оде Зухайени; Путра, Аманда Пратама Путра; Сетьяди, Игнатий Адитья (Статистическое управление Индонезии) | Бумага | ||
| Инструмент для сбора данных для мониторинга и анализа опросов. Мария Хинда и Небойша Толич (Статистическое управление Республики Сербия [СУРС]) | Аннотация | ||
| Оптимизация деятельности по мониторингу сбора данных за счет использования контрольных карт: приложение к обследованию EU-SILC. Мануэла Мурджа, Алессандра Нуччителли и Франческа Россетти (Истат, Италия) | Бумага | ||
| Модернизация сбора данных для социальных обследований и адаптации к пандемическому кризису. Эстонский опыт. Эпп Карус (Статистическое управление Эстонии) | Аннотация | ||
| Активные метаданные для системы сбора данных. Бенуа Веркин и Франк Коттон (INSEE, Франция) | Бумага | ||
| Составление административных отчетов о мексиканской промышленности легких и тяжелых транспортных средств: опыт предоставления подробных и своевременных данных пользователям. Херардо Дюран (INEGI, Мексика) | Бумага | ||
| Инновационные геопространственные инструменты, интегрированные в статистический процесс экономической переписи в Колумбии. Сандра Лилиана Морено (ДЕЙН, Колумбия) | Аннотация | ||
| S Часть 2: Адаптация сбора данных в условиях кризиса | |||
| Организаторы заседания: Ян О’Салливан (УНС, Соединенное Королевство) и Лиз Ривайс (Статистическое управление Канады) | |||
| Влияние корректировок в сборе личных данных в связи с пандемией COVID-19 на результаты опроса. Daniëlle Groffen, Goris, K., van Berkel, K .; ван ден Бракель, Дж. (Статистическое управление Нидерландов) | Бумага | ||
| Переход к национальному исследованию занятости и занятости во время пандемии Covid-19. Эдгар Вьельма Ороско (INEGI, Мексика) | Бумага | ||
| Своевременная официальная статистика во время пандемии COVID-19 в Нидерландах. Ян ван ден Бракель (Статистическое управление Нидерландов и Маастрихтский университет), Сабина Криг и Марк Смитс (Статистическое управление Нидерландов) | Аннотация | ||
| Сбор данных и влияние, проблемы и возможности пандемии COVID-19. Сильви Бономм (Статистическое управление Канады) | Аннотация | ||
| Вызовы экономических переписей 2019 года в Мексике. Сусана Перес Кадена (INEGI, Мексика) | Бумага | ||
| Индикаторы в реальном времени: возможности, проблемы и следующие шаги для национальных статистических институтов. Грант Фитцнер (Управление национальной статистики, Соединенное Королевство) | Аннотация | ||
| Создание быстрого и исключительного исследования предприятий во времена COVID. София Родригес, Альмиро Морейра и Пауло Сараива. (Статистическое управление Португалии) | Аннотация | ||
| Необходимость своевременной официальной статистики: пандемия как движущая сила инноваций. Piet Daas (Статистическое управление Нидерландов), De Broe, S. (Sciensano), ten Bosch, O., Buiten, G. и Laevens, B. (Статистическое управление Нидерландов) | Аннотация | ||
| Сотрудничество во время кризиса — межнациональный взгляд на национальные статистические организации и управление данными во время кризиса. Флориан Хеннинг (Статистическое управление Нидерландов), Кристал Сьюардс (Статистическое управление Канады), Пол Груотен (Статистическое управление Нидерландов), Линн Хубен (Статистическое управление Нидерландов), Матяс Джуг (Статистическое управление Нидерландов), Кортни Кэмерон (Статистическое управление Канады), Дэвид МакНэми (Статистическое управление Канады) , Родитель Доминик (Статистическое управление Канады) | Бумага | ||
| Сессия 3: Забота о респондентах | |||
| Организаторы заседания: Сьюзан Оудсхорн (Статистическое управление Нидерландов), Пауло Сараива (Статистическое управление Португалии) и Ян О’Салливан (УНС, Соединенное Королевство) | |||
| Просто, но эффективно: развитие использования электронной почты в учреждениях для увеличения участия респондентов в опросах предприятий. Спурти Дсоуза, Джоди Клайн и Лэнс Нельсон (Австралийское статистическое бюро) | Бумага | ||
| Отслеживание государственных расходов в сельском хозяйстве: применение ФАО методологии и данных МВФ. Гэри Джонс и Атанг Молетсане (Продовольственная и сельскохозяйственная организация Объединенных Наций) | Бумага | ||
| На пути к порталу будущего для бизнес-респондентов. Бенте Хоул (Статистическое управление Норвегии), Чандра Адольфссон (Статистическое управление Швеции) и Линн Хубен (Статистическое управление Нидерландов) | Бумага | ||
| Объем респондентов в бизнес-опросах — как управлять? София Родригеш, Альмиро Морейра, Паулу Сараива (Статистическое управление Португалии) | Аннотация | ||
| Мониторинг и устранение предвзятости опросов, связанных с неполучением ответов, во время пандемии. Мартина Хельме и Вероник Сиглер (Управление национальной статистики, Соединенное Королевство) | Аннотация | ||
| Познавательное онлайн-интервью с предприятиями и учреждениями. Серена Лиани и Габриэлла Фацци (Истат, Италия) | Бумага | ||
| Модернизация сбора данных — Использование видеоданных в опросах BLS. Тамара Мэдсен и Нишант Менон (Бюро статистики труда США) | Аннотация | ||
| Сессия 4: Многомодовые и интеграция источников данных | |||
| Организаторы заседания: Кес ван Беркель (Статистическое управление Нидерландов) и Андреа Ашери (Евростат) | |||
| Онлайн-перепись населения: индонезийский опыт. Буди, Брилиан Сурья; Мунаф, Альфатиха Р. М. Н. С. П .; Ашиддики, Султони (Статистическое управление Индонезии) | Бумага | ||
| Комбинированные методы в статистике туризма. Путра, Аманда Пратама; Мунаф, Альфатиха Р. М. Н. С. П .; Руслани, Агус (Статистическое управление Индонезии) | Бумага | ||
| Методологические проблемы интеллектуальных опросов — три тематических исследования. Энн Элевельт и Барри Схоутен (Статистическое управление Нидерландов) | Аннотация | ||
| Экспериментальная проверка видео-опосредованного интервьюирования в официальной статистике. Клаудио Чеккарелли, Габриэлла Фацци, Марко Фортини, Серена Лиани (Истат, Италия) | Аннотация | ||
| CENSUS 2021 — Опыт сбора данных в Португалии. Альмиро Морейра, Луиса Перейра, Паулу Сараива (Статистическое управление Португалии) | Аннотация | ||
| Использование данных электронного счета во время COVID. Альмиро Морейра, Антониу Португалия, Бруну Лима, Жоао Посас, Хорхе Магальяйнш, Паула Крус, Сальвадор Хиль, София Родригеш (Статистическое управление Португалии) | Бумага | ||
| Обследования домохозяйств на ближайшее десятилетие. Хаойи Чен (Межсекретариатская рабочая группа по обследованиям домашних хозяйств, Статистический отдел Организации Объединенных Наций) | Аннотация | ||
| Статистическое управление Канады «Опыт планирования, расчета затрат, управления и оценки сбора данных в рамках многомодовых социальных обследований». Франсуа Лафламм (Статистическое управление Канады) | Бумага | ||
Статистические методы для анализа экспериментов с дискретным выбором: отчет рабочей группы ISPOR по совместному анализу по надлежащей исследовательской практике
https://doi.org/10.1016/j.jval.2016.04.004Получить права и содержаниеАннотация
Объединенный анализ — это метод опроса заявленных предпочтений, который можно использовать для получения ответов, раскрывающих предпочтения, приоритеты и относительную важность индивидуальных характеристик, связанных с медицинскими вмешательствами или услугами.Методы совместного анализа, особенно эксперименты с дискретным выбором (DCE), все чаще используются для количественной оценки предпочтений пациентов, лиц, осуществляющих уход, врачей и других заинтересованных сторон. Последние основанные на консенсусе рекомендации по передовой исследовательской практике, включая два недавних отчета рабочих групп Международного общества фармакоэкономики и исследований результатов, помогли повысить качество совместных анализов и DCE в исследованиях результатов. Тем не менее, неопределенность в отношении надлежащей исследовательской практики для статистического анализа данных DCE сохраняется.Есть несколько методов анализа данных DCE. Понимание характеристик и правильное использование различных методов анализа имеет решающее значение для проведения хорошо спланированного исследования АКД. Этот отчет поможет исследователям в оценке и выборе альтернативных подходов к проведению статистического анализа данных DCE. Сначала мы представляем упрощенный пример DCE и простой метод использования полученных данных. Затем мы представляем педагогический пример DCE и один из наиболее распространенных подходов к анализу данных из такого формата вопросов — условный логит.Затем мы описываем некоторые общие альтернативные методы анализа этих данных, а также сильные и слабые стороны каждой альтернативы. Мы представляем контрольный список ESTIMATE, который включает список вопросов, которые следует учитывать при обосновании выбора метода анализа, описании анализа и интерпретации результатов.
Ключевые слова
совместный анализ
эксперимент с дискретным выбором
методы заявленных предпочтений
статистический анализ
Рекомендуемые статьиЦитирующие статьи (0)
© 2016 International Society for Pharmacoeconomics and Outcomes Research (ISPOR).Опубликовано Международным обществом фармакоэкономики и исследований результатов (ISPOR)
Рекомендуемые статьи
Цитирующие статьи
Поиск публикаций NIOSHTIC-2 — 20033490
Отчет статистической группы по респираторной пыли угольных шахт.
Авторы
Smith-RL; Когут-Дж; Attfield-MD; Сискинд-Ф; Стрикленд-К; Parry-R
Источник
Вашингтон, округ Колумбия: Министерство труда США, Управление по безопасности и охране здоровья в шахтах, сентябрь 1993 г .; 1 и 2: 1-489
Абстрактный
В мае 1991 года министр труда поручил Управлению по безопасности и охране здоровья в шахтах (MSHA) провести тщательный анализ программы контроля вдыхаемой угольной пыли и разработать рекомендации о том, как эту программу можно улучшить.Этот запрос последовал за объявлением в предыдущем месяце о повсеместном вмешательстве с образцами вдыхаемой пыли, взятыми операторами шахт. Целевая группа по респирабельной пыли из угольных шахт (Целевая группа) была создана помощником секретаря по безопасности и охране здоровья в шахтах для обзора программы по вдыхаемой угольной пыли и выработки рекомендаций по ее улучшению. Из-за того, что раскрытие информации о вмешательстве оператора в программу защиты от пыли вызвало опасения по поводу достоверности существующей информации о воздействии на майнеров, Task Grup разработала краткосрочную программу точечной проверки вдыхаемой пыли (SIP) и программу контроля и проверки (MIP) в дополнение к ней. существующие данные.SIP был предназначен для измерения концентраций пыли, которым фактически подверглись горняки, для определения степени и эффективности фактически используемых средств контроля пыли, а также для оценки знаний и навыков горняков и операторов в отношении программы пылеудаления. Эта информация была получена во время необъявленных визитов инспекторов MSHA и состояла из отбора проб пыли, измерения производства и контроля пыли, а также интервью с персоналом шахты. MIP был предназначен для оценки программы отбора проб операторами посредством наблюдения MSHA за методами отбора проб операторами и контроля за пылью.Он состоял из специальных посещений шахт инспекторами во время их обязательных циклов отбора проб, проводимых два раза в месяц. Во время этих посещений, которые состояли из одной смены, инспектор действовал как пассивный наблюдатель за процессом отбора проб операторами, но записывал данные о контроле пыли на месте, аналогичные тем, которые были получены в SIP. Как в SIP, так и в MIP, инспекторы MSHA также записали спецификации плана контроля пыли для сравнения с средствами контроля пыли на месте во время отбора проб пыли. Инспекции SIP, использованные в настоящем статистическом анализе, были завершены 31 октября 1991 г. и охватили 723 механизированных горных единицы (MMU) на 565 подземных угольных шахтах.В этот анализ также включены результаты инспекций MIP с участием 717 MMU на 545 подземных угольных шахтах, многие из которых также были включены в SIP. Программа MIP завершилась 30 декабря 1991 года. Статистическая группа была одной из шести целевых групп, созданных Рабочей группой для оказания помощи в ее всестороннем обзоре всех аспектов программы по вдыхаемой угольной пыли. Инструменты сбора данных SIP и MIP, критерии выбора для MMU, которые должны быть включены в две программы, и протокол посещения рудников были разработаны группой, ответственной за аудит шахт, до формирования статистической группы.Общая задача статистической группы заключалась в использовании данных, полученных с помощью программы отбора проб респирабельной пыли операторами угольных шахт, специальных инспекций SIP и MIP, а также регулярных инспекций вдыхаемой пыли MSHA для оценки эффективности программ оператора и MSHA в мониторинге вдыхаемой пыли. воздействия и соблюдение. С этой целью Статистическая группа встречалась и широко общалась с Целевой группой и представителями других групп, чтобы определить проблемы и вопросы, которые следует решить посредством статистического анализа имеющихся данных.В поддержку анализа были созданы три базы данных: база данных SIP, база данных MIP и, для сравнения с предыдущими концентрациями пыли и уровнями производства, полученными посредством обычного отбора проб оператором, база данных проб оператора (POPERAT). Базы данных SIP и MIP были разработаны сотрудниками Денверского центра технологий безопасности и здравоохранения (DSHTC) при MSHA, а POPERAT был разработан на основе спецификаций статистической группы сотрудниками Центра информационных систем (ISC) MSHA. Чтобы обеспечить достаточную историческую базу, с которой можно сравнивать результаты SIP и MIP, POPERAT содержит данные подземного отбора проб угольной пыли, соответствующие данные о сменном производстве, предоставленные оператором, и стандарты пыли с поправкой на кварц с последнего двухмесячного цикла отбора проб с 1989 года по последний двухмесячный цикл 1991 г.(Циклы расположены в шахматном порядке для выборок из определенных областей по сравнению с выборками из определенных профессий.) В частности, POPERAT содержит результаты для образцов, взятых во время инспекций MIP. Четвертая база данных, использованная в анализе, — это существующая база данных MSHA Inspector Sample (PINSPECT), предоставленная непосредственно ISC. PINSPECT содержит данные об образцах пыли, соответствующих сменных производствах, определенных инспектором, и нормативы пыли с поправкой на кварц для подземных респирабельных проб угольной пыли, взятых инспекторами MSHA в период с 1 октября 1989 г. по 31 июля 1992 г.В частности, ПИНСПЕКТ включает результаты всех проверок SIP. Наконец, чтобы учесть влияние размера шахты, сотрудники DSHTC создали базу данных о занятости в подземных угольных шахтах (PMINE_EM) на основе квартальных данных о занятости, предоставленных операторами согласно 30 CFR Part 50. Группа статистиков использовала информацию из этих пяти баз данных, чтобы ответьте на следующие вопросы и проблемы: 1. При каких концентрациях пыли подвержены горняки подземных угольных шахт? С какой частотой превышается стандарт вдыхаемой пыли? Как часто риски других майнеров на этом участке превышают таковые для назначенного майнера с высоким уровнем риска? Концентрации пыли, полученные с помощью образцов SIP, MIP и PINSPECT, представлены в Разделе I «Сводка или данные» вместе с общим описанием и анализом других данных, собранных для этого исследования.Раздел I также содержит статистические данные о несоблюдении стандарта по пыли, основанные как на единичных, так и на средних выборках SIP. Оценка уровней несоблюдения и воздействия пыли, когда пробы не собираются, обсуждается в Частях C и D Раздела IV «Окружающая среда шахты». 2. Как обычные пробы оператора и пробы пыли инспектора сравниваются с пробами, полученными в рамках специальной программы выборочной проверки и мониторинга MSHA. Раздел II «Сравнение программ отбора проб» позволяет проводить эти сравнения и оценивать различия.3. Как образцы с низким приростом веса (LWG) повлияли на оценки воздействия вдыхаемой пыли и определения соответствия требованиям MSHA? Раздел III, Образцы с низким приростом веса, рассматривает этот вопрос, а также сравнивает частоту выборок L WG в данных SIP, MIP, PINSPECT и POPERA T. 4. Как производственные показатели и меры контроля запыленности, действующие во время отбора проб оператором и инспектором, соотносятся с нормальными производственными показателями и утвержденным MSHA планом контроля запыленности? Насколько репрезентативны для нормальных условий эксплуатации концентрации пыли, полученные из проб, взятых оператором или инспектором? Попытка решить эти проблемы сделана в Разделе IV «Шахтная среда».5. Какой уровень знаний, подготовки и квалификации очевиден среди майнеров и сертифицированных пробоотборников, опрошенных в рамках специальной программы MSHA? Результаты собеседований по программе SIP представлены в Разделе V «Знания, обучение и навыки». В разделе VI отчета обобщены результаты, подтвержденные имеющимися данными. Раздел VII, Приложения, включает Приложение A, набор описательных статистических таблиц, обсуждаемых в описательной части, и Приложение B, подробное описание всех пяти баз данных.
Используйте группы и фильтры в Bitable
I. Введение
Функции множественного группирования позволяют упорядочивать данные по желаемым комбинациям для достижения эффективного управления данными. Кроме того, вы можете использовать условия фильтрации, чтобы видеть только те данные, которые вам нужны.
II. Шаги
Группировка
Установка групп и многоуровневых групп
- • Задайте условия группировки для упорядочивания данных по своему усмотрению. : Щелкните Группа на панели инструментов и установите любое поле в качестве условия группировки.Данные будут автоматически распределены по категориям.
- • Добавьте условия группировки для управления данными по своему усмотрению. : После установки условий группировки уровня 1 вы можете продолжить добавление дополнительных условий группировки для уточнения группировки данных.
Настройте уровни группировки и отмените группировку
- • Настройте уровни группировки : Перетащите условие группировки, и данные будут повторно сгруппированы и представлены в порядке, основанном на условиях пост-корректировки.
- • Отменить группировку : Щелкните X справа от условия группировки, и условие будет удалено. Затем таблица сгруппирует и представит данные по порядку в соответствии с условиями после удаления. Если все условия группировки удалены, таблица восстановит свой первоначальный вид.
Сохранить как новый вид
Щелкните Группа > Сохранить как новый вид в нижнем левом углу панели и назовите вид.После этого текущий статус группировки будет сохранен в левой строке меню.
Фильтрация
Задайте условия фильтрации
- • Щелкните Фильтр > Добавить условие на панели инструментов, выберите любое поле и найдите параметр в качестве условия фильтрации. Затем Bitable автоматически отобразит данные, соответствующие условию. Вы можете добавить дополнительные условия фильтрации, чтобы сузить область поиска и точно определить местонахождение целевых данных.
- • Между тем, когда установлены два или более условий фильтрации, вы можете выбрать отображение результатов, которые соответствуют всем условиям или любому из условий.
Сохранить как новое представление
- • После установки условий фильтрации щелкните Сохранить как новое представление , и текущие результаты фильтрации будут автоматически сохранены как новое представление для облегчения повторных посещений пользователями и централизованного управления.
Умелое использование группировки и фильтрации
Узнайте, как использовать один Bitable для целых межведомственных проектов, координируя работу нескольких членов команды, распределяя несколько ролей и обязанностей и эффективно отслеживая прогресс.
- • Начало проекта : Установив условия фильтрации, члены группы могут сосредоточиться на задачах, за которые они несут ответственность. Каждый участник также может сохранять результаты фильтрации в виде нового представления, чтобы адаптировать Bitable под свои нужды.
Примечание : Обновления, сделанные для нового представления Bitable, будут синхронизироваться со всеми другими представлениями в реальном времени.
- • Текущие проекты : Менеджер проекта может создавать группы в представлении Ганта, чтобы отслеживать общий прогресс проекта и отслеживать выполнение элементов с разными приоритетами с помощью многоуровневой группировки для поиска и решения проблемы во времени.
- • Проекты, приближающиеся к завершению : Менеджер проекта может немедленно идентифицировать отложенные задачи и их соответствующих владельцев, одновременно устанавливая условия фильтрации и группировки. Это также может помочь им быстро выявить потенциальные задержки, найти решения и вовремя реализовать проекты.
III. Часто задаваемые вопросы
Будут ли результаты группировки в текущем представлении синхронизироваться с другими представлениями?
№. Состояние группировки отображается только в текущем просмотре.
Будут ли условия группирования очищены после обновления или выхода и повторного ввода битового файла?
Нет. Последнее действие группировки будет сохранено в истории.