
Стьюдента формула: Функция СТЬЮДЕНТ.ТЕСТ
Функция СТЬЮДЕНТ.ТЕСТ
Возвращает вероятность, соответствующую t-тесту Стьюдента. Функция СТЬЮДЕНТ.ТЕСТ позволяет определить вероятность того, что две выборки взяты из генеральных совокупностей, которые имеют одно и то же среднее.
Синтаксис
СТЬЮДЕНТ.ТЕСТ(массив1;массив2;хвосты;тип)
Аргументы функции СТЬЮДЕНТ.ТЕСТ описаны ниже.
-
Массив1 Обязательный. Первый набор данных.
-
Массив2 Обязательный. Второй набор данных.
-
Хвосты Обязательный. Число хвостов распределения. Если значение «хвосты» = 1, функция СТЬЮДЕНТ.ТЕСТ возвращает одностороннее распределение. Если значение «хвосты» = 2, функция СТЬЮДЕНТ.ТЕСТ возвращает двустороннее распределение.

-
Тип Обязательный. Вид выполняемого t-теста.

Параметры
|
Тип |
Выполняемый тест |
|
1 |
Парный |
|
2 |
Двухвыборочный с равными дисперсиями (гомоскедастический) |
|
3 |
Двухвыборочный с неравными дисперсиями (гетероскедастический) |
Замечания
-
Если аргументы «массив1» и «массив2» имеют различное число точек данных, а «тип» = 1 (парный), то функция СТЬЮДЕНТ.
-
Аргументы «хвосты» и «тип» усекаются до целых значений.
-
Если «хвосты» или «тип» не является числом, возвращается #VALUE! значение ошибки #ЗНАЧ!.
-
Если «хвосты» — любое значение, кроме 1 или 2, возвращается значение #NUM! значение ошибки #ЗНАЧ!.
-
Функция СТЬЮДЕНТ.ТЕСТ использует данные аргументов «массив1» и «массив2» для вычисления неотрицательной t-статистики. Если «хвосты» = 1, СТЬЮДЕНТ.ТЕСТ возвращает вероятность более высокого значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими к генеральной совокупности с одним и тем же средним. Значение, возвращаемое функцией СТЬЮДЕНТ.ТЕСТ в случае, когда «хвосты» = 2, вдвое больше значения, возвращаемого, когда «хвосты» = 1, и соответствует вероятности более высокого абсолютного значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими к генеральной совокупности с одним и тем же средним.


Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные 1 |
Данные 2 |
|
|
3 |
6 |
|
|
4 |
19 |
|
|
5 |
3 |
|
|
8 |
|
|
|
9 |
14 |
|
|
1 |
4 |
|
|
2 |
5 |
|
4 |
17 |
|
|
5 |
1 |
|
|
Формула |
Описание |
Результат |
|
=СТЬЮДЕНТ. |
Вероятность, соответствующая парному критерию Стьюдента, с двусторонним распределением |
0,196016 |
 ТЕСТ(A2:A10;B2:B10;2;1)
ТЕСТ(A2:A10;B2:B10;2;1)Т-критерий Стьюдента за 12 минут
Сегодня мы говорим о t-критерии. Т-критерий наиболее популярный статистический тест в биомедицинских исследованиях. Также его называют парный Т-критерий Стьюдента, t-test, two-sample unpaired t-test. Однако, при использовании этого статистического инструмента допускается достаточно много ошибок. Сегодня в этой статье мы постараемся разобраться, как избежать ошибок применения t-критерия Стьюдента, как интерпретировать его результаты и как рассчитывать t-критерий самостоятельно. Об этом обо всем читайте далее.
При описании любого статистического критерия, будь то t-критерий Стьюдента, либо какой-либо еще, нужно вспомнить о том, как же вообще используются статистические критерии.
Этапы статистического вывода (statistic inference)
- Первый из них – это вопрос, который мы хотим изучить с помощью статистических методов. То есть первый этап: что изучаем? И какие у нас есть предположения относительно результата? Этот этап называется этап статистических гипотез.
- Второй этап – нужно определиться с тем, какие у нас есть в реальности данные для того, чтобы ответить на первый вопрос. Этот этап – тип данных.
- Третий этап состоит в том, чтобы выбрать корректный для применения в данной ситуации статистический критерий.
- Четвертый этап это логичный этап применения интерпретации любой формулы, какие результаты мы получили.
- Пятый этап это создание, синтез выводов относительно первого, второго, третьего, четвертого, пятого этапа, то есть что же получили и что же это в реальности значит.

Предлагаю долго не ходить вокруг да около и посмотреть применение t-критерия Стьюдента на реальном примере.
Видео-версия статьи
Пример использования т-критерия Стьюдента
А пример будет достаточно простой: мне интересно, стали ли люди выше за последние 100 лет. Для этого нужно подобрать некоторые данные. Я обнаружил интересную информацию в достаточно известной статье The Guardian (
Там приведены данные практически по всем государствам. Однако, я взял лишь 5 стран для простоты вычислений: это Россия, Германия, Китай, США и ЮАР, соответственно 1914 год и 2014 год.
Общее количество наблюдений – 5 в 1914 году в группе 1914 года и общее значение также 5 в 2014 году. Будем думать опять же для простоты, что эти данные сопоставимы, и с ними можно работать.
Дальше нужно выбрать критерии – критерии, по которым мы будем давать ответ. Равны ли средние по росту в 1914 году x̅1914 и в 2014 году x̅2014. Я считаю, что нет. Поэтому моя гипотеза это то, что они не равны (x̅1914≠x̅2014). Соответственно альтернативная гипотеза моему предположению, так называемая нулевая гипотеза (нулевая гипотеза консервативна, обратная вашей, часто говорит об отсутствии статистически значимых связей/зависимостей) будет говорить о том, что они между собой на самом деле равны (x̅1914=x̅2014), то есть о том, что все эти находки случайны, и я, по сути, не прав.
Теперь нужно дать какой-то аргументированный ответ. Даем его с помощью статистического критерия. Соответственно теперь наступает самое важное: как выбрать статистический критерий? Я думаю, это будет темой отдельной статьи. Для корректности использования t-критерия Стьюдента лишь скажу, что нужно, чтобы:
Условия применения статистического критерия т-теста (критерия Стьюдента)
— данные распределялись по закону нормального распределения;
— данные были количественными;
— и это две независимые между собой выборки (независимые это значит, что в этих группах разные люди, а никак, например, до и после применения препарата у одной группы, люди должны быть разными, тогда группы являются несвязанными, либо независимыми), этот аспект стоит учитывать для выбора вида т-критерия Стьюдента, так как для парных выборок существует свой парный т-критерий (paired t-test).
В итоге Мы определились с тем, что это будет t-критерий Стьюдента.
Формула t-критерия Стьюдента достаточно простая. Она гласит о том, что в числителе у нас разница средних, в знаменателе у нас корень квадратный суммы ошибок репрезентативности по этим группам:
Она гласит о том, что в числителе у нас разница средних, в знаменателе у нас корень квадратный суммы ошибок репрезентативности по этим группам:
Ошибки репрезентативности были подробно объяснены мною в статье по доверительным интервалам. Поэтому я рекомендую вам ознакомиться с ней, чтобы лучше разобраться, что такое ошибки репрезентативности, что такое выборка, как она соотносится с генеральной совокупностью.
Для того, чтобы не тратить время, я в принципе все уже рассчитал по каждой из групп: средняя (x̅) ,стандартное отклонение (SD) и ошибка репрезентативности (mr).
Давайте остановимся на том, что же значат эти значения:
— средняя (x̅) это среднеарифметическое по 5 наблюдениям в каждой группе;
— если совсем упрощать значение стандартного отклонения (SD), то можно сказать, что оно представляет собой обобщенную среднюю отклонения каждого значения от среднего (стандартное отклонение показывает, насколько широко значения рассеяны (разбросаны) относительно средней). И дальше мы находим нечто среднее отклонений каждого варианта в группе от среднего;
И дальше мы находим нечто среднее отклонений каждого варианта в группе от среднего;
— и ошибка репрезентативности она тоже находится достаточно просто: это как раз наше отклонение от средней некоторое стандартизованное, поэтому стандартное отклонение на размер выборки (mr=).
Итак, продолжаем. В ходе подстановки каждого значения в нашу формулу, мы находим, что t-критерий Стьюдента равен 3,78. Однако, я думаю, пока тем, кто не знаком со статистическими критериями, это мало о чем говорит.
Итак, теперь настает четвертый этап вопрос интерпретации. Ранее мы получили значение t-критерия в 3,78. Однако, что же это значит? Стоит отметить, что результаты статистических критериев и вообще их интерпретация не говорит о точном «да», либо «нет» в выводе, то есть рост отличается, либо рост не отличается. Всегда это вопрос определенной доли вероятности – доли вероятности ошибиться при констатации положительного результата (речь об ошибке первого рода (I type error, Alpha)). То есть, например, если мы скажем, что средний рост в начале ХХ и в начале XXI века отличаются с долей ошибкой меньше 5 %. Как раз эта величина в 5 % и фиксируется как достаточная для большинства биомедицинских исследований, помните, р больше, либо меньше 0,05.
То есть, например, если мы скажем, что средний рост в начале ХХ и в начале XXI века отличаются с долей ошибкой меньше 5 %. Как раз эта величина в 5 % и фиксируется как достаточная для большинства биомедицинских исследований, помните, р больше, либо меньше 0,05.
Итак, как нам перейти от нашей t к р вероятности? Это сделать достаточно просто, стоит лишь воспользоваться табличными значениями t для определенных степеней свободы. Теперь вопрос: как найти эти степени свободы? Но это сделать достаточно просто. Для того, чтобы обнаружить степени свободы для наших групп, нужно лишь сложить количество наблюдений 5 и 5 в нашем случае и вычесть 2. В нашем случае степень свободы равна 8.
Итак, t=3,78, степень свободы равна 8. Переходим в табличное значение и получаем р вероятность – вероятность равна 0,005. То есть вероятность того, что мы ошибаемся при констатации факта различия роста ранее и сейчас, крайне мала – это 0,005 %, не 5 %, а 0,005 %. То есть мы можем говорить с высокой долей достоверности того, что наш рост сейчас в XXI веке и 100 лет назад отличаются.
Вот то, что касается расчета t-критерия Стьюдента и его интерпретации.
На этом наш разговор о t-критерии Стьюдента закончен. Спасибо, что ознакомились с этой статьей. Я очень надеюсь на вашу обратную связь. Пожалуйста, подписывайтесь на наш сайте, ставьте лайки, предлагайте свои темы для следующих выпусков. Спасибо большое за поддержку. С вами был Кирилл Мильчаков. Пока, до новых встреч!
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Классические методы статистики: t-критерий Стьюдента
Начать, пожалуй, стоит с математических допущений, на которых основан критерий Стьюдента. Основных таких допущений, как известно, два:
Этот вариант критерия Стьюдента служит для проверки нулевой гипотезы о равенстве среднего значения (\(mu_1\)) генеральной совокупности, из которой была взята выборка, некоторому известному значению (\(mu_0\)):
Эквивалентным подходом к интерпретации результатов теста будет следующий: допустив, что нулевая гипотеза верна, мы можем рассчитать, насколько велика вероятность получить t-критерий, равный или превышающий то реальное значение, которое мы рассчитали по имеющимся выборочным данным. Если эта вероятность оказывается меньше, чем заранее принятый уровень значимости (например, \(P < 0.05\)), мы вправе отклонить проверяемую нулевую гипотезу. Именно такой подход сегодня используется чаще всего: исследователи приводят в своих работах P-значение, которое легко рассчитывается при помощи статистических программ. Рассмотрим, как это можно сделать в системе R.
Если эта вероятность оказывается меньше, чем заранее принятый уровень значимости (например, \(P < 0.05\)), мы вправе отклонить проверяемую нулевую гипотезу. Именно такой подход сегодня используется чаще всего: исследователи приводят в своих работах P-значение, которое легко рассчитывается при помощи статистических программ. Рассмотрим, как это можно сделать в системе R.
Предположим, у нас имеются данные по суточному потреблению энергии, поступающей с пищей (кДж/сутки), для 11 женщин (пример заимствован из книги Altman D. G. (1981) Practical Statistics for Medical Research, Chapman & Hall, London):
d.intake <- c(5260, 5470, 5640, 6180, 6390, 6515, 6805, 7515, 7515, 8230, 8770)
Среднее значение для этих 11 наблюдений составляет:
mean(d.intake) [1] 6753.6
Вопрос: отличается ли это выборочное среднее значение от установленной нормы в 7725 кДж/сутки? Разница между нашим выборочным значением и этим нормативом довольно прилична: 7725 — 6753. 6 = 971.4. Но насколько велика эта разница статистически? Ответить на этот вопрос поможет одновыборочный t-тест. Как и другие варианты t-теста, одновыборочный тест Стьюдента выполняется в R при помощи функции t.test():
6 = 971.4. Но насколько велика эта разница статистически? Ответить на этот вопрос поможет одновыборочный t-тест. Как и другие варианты t-теста, одновыборочный тест Стьюдента выполняется в R при помощи функции t.test():
t.test(d.intake, mu = 7725)
One Sample t-test
data: d.intake
t = -2.8208, df = 10, p-value = 0.01814
alternative hypothesis: true mean is not equal to 7725
95 percent confidence interval:
5986.348 7520.925
sample estimates:
mean of x
6753.636 Видим, что для имеющихся выборочных данных t-критерий составляет -2.821 при 10 степенях свободы (df). Вероятность получить такое (либо большее) значение t при условии, что проверяемая нулевая гипотеза верна, оказалась весьма мала: p-value = 0.01814 (во всяком случае, это меньше 5%). Следовательно (см. выше), мы можем отклонить проверяемую нулевую гипотезу о равенстве выборочного среднего значения нормативу и принять альтернативную гипотезу (alternative hypothesis: true mean is not equal to 7725). Делая это, мы рискуем ошибиться с вероятностью менее 5%.
Делая это, мы рискуем ошибиться с вероятностью менее 5%.
Помимо t-критерия, количества степеней свободы, Р-значения и выборочного среднего (sample estimates: mean of x), программа рассчитала также 95%-ный доверительный интервал (95 percent confidence interval) для истинной разницы между выборочным средним значением суточного потребления энергии и нормативом. Если бы мы повторили аналогичный тест много раз для разных групп из 11 женщин, то в 95% случаев эта разница оказалась бы в диапазоне от 5986.3 до 7520.9 кДж/сутки.
Сравнение двух независимых выборок
При сравнении двух выборок проверяемая нулевая гипотеза состоит в том, что обе эти выборки происходят из нормально распределенных генеральных совокупностей с одинаковыми средними значениями:
\[H_0: \mu_1 = \mu_1 \]
Поскольку эти генеральные средние мы оцениваем при помощи выборочных средних значений, формула t-критерия приобретает вид
\[t = \frac{\bar{x_1} — \bar{x_1}}{S_{\bar{x_1} — \bar{x_2}}}\]
В знаменателе приведенной формулы находится стандартная ошибка разницы между выборочными средними, которая в общем виде рассчитывается как
\[S_{\bar{x}_1-\bar{x}_2} = \sqrt {\frac{s^2_1}{n_1}+\frac{s^2_2}{n_2}},\]
где \(s_{1}^{2}\) и \(s_{2}^{2}\) — выборочные оценки дисперсии.
 При соблюдении условия о равенстве групповых дисперсий приведенная формула приобретает более простой вид (подробнее см. здесь). Интерпретация t-критерия, рассчитанного для двух выборок, выполняется точно так же, как и в случае с одной выборкой (см. выше).
При соблюдении условия о равенстве групповых дисперсий приведенная формула приобретает более простой вид (подробнее см. здесь). Интерпретация t-критерия, рассчитанного для двух выборок, выполняется точно так же, как и в случае с одной выборкой (см. выше). Рассмотрим пример о суточном расходе энергии (expend) у худощавых женщин (lean) и женщин с избыточным весом (obese), приведенный в книге Питера Дальгаарда (Dalgaard P (2008) Introductory statistics with R. Springer). Данные из этого примера (подробнее см. ?energy) входят в состав пакета ISwR, сопровождающего книгу (если он у Вас не установлен, выполните команду install.packages(«ISwR»)):
library(ISwR) data(energy) attach(energy) energy expend stature 1 9.21 obese 2 7.53 lean 3 7.48 lean 4 8.08 lean 5 8.09 lean 6 10.15 lean 7 8.40 lean 8 10.88 lean 9 6.13 lean 10 7.90 lean 11 11.51 obese 12 12.79 obese 13 7.05 lean 14 11.85 obese 15 9.
 97 obese
16 7.48 lean
17 8.79 obese
18 9.69 obese
19 9.68 obese
97 obese
16 7.48 lean
17 8.79 obese
18 9.69 obese
19 9.68 obeseСоответствующие средние значения потребления энергии в рассматриваемых группах пациенток составляют (подробнее о примененной ниже функции tapply() см. здесь):
tapply(expend, stature, mean) lean obese 8.07 10.30
Различаются ли эти средние значения статистически? Проверим гипотезу об отсутствии разницы при помощи t-теста:
t.test(expend ~ stature)
Welch Two Sample t-test
data: expend by stature
t = -3.8555, df = 15.919, p-value = 0.001411
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.459167 -1.004081
sample estimates:
mean in group lean mean in group obese
8.066154 10.297778 Обратите внимание на использование знака ~ в вызове функции t.test(). Это стандартный для R способ записи формул, описывающих связь между переменными. В нашем случае выражение expend ~ stature можно расшифровать как «зависимость суточного потребления энергии (expend) от статуса пациентки (stature)».
Согласно полученному значению P (p-value = 0.001411), средние значения потребления энергии у женщин из рассматриваемых весовых групп статистически значимо различаются. Отвергая нулевую гипотезу о равенстве этих средних значений, мы рискуем ошибиться с вероятностью лишь около 0.1%. При этом истинная разница между средними значениями с вероятностью 95% находится в диапазоне от -3.5 до -1.0 (см. 95 percent confidence interval).
Следует подчеркнуть, что при выполнении двухвыборочного t-теста R по умолчанию принимает, что дисперсии сравниваемых совокупностей не равны, и, как следствие, выполняет t-тест в модификации Уэлча (подробнее см. здесь). Мы можем изменить такое поведение программы, воспользовавшись аргументом var.equal = TRUE: (от variance — дисперсия, и equal — равный):
t.test(expend ~ stature, var.equal = TRUE)
Two Sample t-test
data: expend by stature
t = -3.9456, df = 20, p-value = 0.000799
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3. 411451 -1.051796
sample estimates:
mean in group lean mean in group obese
8.066154 10.297778 411451 -1.051796
sample estimates:
mean in group lean mean in group obese
8.066154 10.297778
411451 -1.051796
sample estimates:
mean in group lean mean in group obese
8.066154 10.297778Р-значение стало еще меньше, и мы так же, как и после теста в модификации Уэлча, можем сделать вывод о наличии существенной разницы между средними. Однако такое совпадение выводов будет иметь место не всегда и, следовательно, на разницу между групповыми дисперсиями (или ее отсутствие) следует обращать серьезное внимание при выборе и интерпретации того или иного варианта t-теста.
Сравнение двух зависимых (= парных) выборок
Зависимыми, или парными, являются две выборки, содержащие результаты измерений какого-либо количественного признака, выполненных на одних и тех же объектах. Во многих исследованиях какой-то определенный отклик измеряется у одних и тех же объектов до и после экспериментального воздействия. При такой схеме эксперимента исследователь более точно оценивает эффект воздействия именно потому, что прослеживает его у одних и тех же объектов.
Но как в таких случаях оценить наличие эффекта от воздействия статистически? В общем виде критерий Стьюдента можно представить как
\[t = \frac{\text{оценка параметра} — \text{истинное значение параметра}}{\text{ст. ошибка оценки параметра}}\]
Нас интересует «истинное значение параметра» — среднее изменение какого-либо количественного признака как результат экспериментального воздействия — обозначим его \(\delta\). Оценкой этого истинного параметра является наблюдаемое (выборочное) среднее изменение признака. Тогда t-критерий примет вид
\[t = \frac{\bar{d} — \delta}{S_{\bar{d}}} \]
Если нулевая гипотеза заключается в равенстве истинного эффекта нулю, формула для парного критерия Стьюдента примет вид\[t = \frac{\bar{d}}{S_{\bar{d}}} \]
В книге П. Дальгаарда (Dalgaard 2008) имеется пример о суточном потреблении энергии, измеренном у одних и тех же 11 женщин до и после периода менструаций:
data(intake) # из пакета ISwR
attach(intake)
intake
pre post
1 5260 3910
2 5470 4220
3 5640 3885
4 6180 5160
5 6390 5645
6 6515 4680
7 6805 5265
8 7515 5975
9 7515 6790
10 8230 6900
11 8770 7335Индивидуальные разницы в потреблении энергии у этих женщин составляют:post - pre [1] -1350 -1250 -1755 -1020 -745 -1835 -1540 -1540 [9] -725 -1330 -1435
Усреднив эти индивидуальные разницы, получим
mean(post - pre) [1] -1320.
 5
5Задача заключается в том, чтобы оценить, насколько статистически значимо эта средняя разница отличается от нуля. Применим парный критерий Стьюдента (обратите внимание на использование аргумента paired = TRUE):
t.test(pre, post, paired = TRUE)
Paired t-test
data: pre and post
t = 11.9414, df = 10, p-value = 3.059e-07
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1074.072 1566.838
sample estimates:
mean of the differences
1320.455Как видим, рассчитанное программой P-значение оказалось намного меньше 0.05, что позволяет нам сделать заключение о наличии существенной разницы в потреблении энергии у исследованных женщин до и после менструации. Истинная величина эффекта (в абсолютном выражении) с вероятностью 95% находится в интервале от 1074.1 до 1566.8 кДж/сутки.
Приведенные выше примеры охватывают наиболее типичные случаи применения критерия Стьюдента. За рамками этого сообщения остаются т. н. односторонние варианты t-теста, когда проверяемая нулевая гипотеза заключается в том, что одно из сравниваемых средних значений больше (или меньше) другого. Однако можно отметить, что односторонний вариант t-теста легко реализуется при помощи функции t.test() в сочетании с аргументом alternative, который может принимать одно из трех значений — «two.sided» («двухсторонний»; выбирается программой по умолчанию), «greater» («больше») или «less» («меньше»).
н. односторонние варианты t-теста, когда проверяемая нулевая гипотеза заключается в том, что одно из сравниваемых средних значений больше (или меньше) другого. Однако можно отметить, что односторонний вариант t-теста легко реализуется при помощи функции t.test() в сочетании с аргументом alternative, который может принимать одно из трех значений — «two.sided» («двухсторонний»; выбирается программой по умолчанию), «greater» («больше») или «less» («меньше»).
Объяснение расчета критерия стьюдента. Основные статистики и t-критерий Стьюдента
Критерий Стьюдента для независимых выборок
Критерий Стьюдента (t -тест Стьюдента или просто «t -тест») применяется, если нужно сравнить только две группы количественных признаков с нормальным распределением (частный случай дисперсионного анализа). Примечание: этим критерием нельзя пользоваться, сравнивая попарно несколько групп, в этом случае необходимо применять дисперсионный анализ. Ошибочное использование критерия Стьюдента увеличивает вероятность «выявить» несуществующие различия. Например, вместо того, чтобы признать несколько методов лечения равно эффективными (или неэффективными), один из них объявляют лучшим.
Ошибочное использование критерия Стьюдента увеличивает вероятность «выявить» несуществующие различия. Например, вместо того, чтобы признать несколько методов лечения равно эффективными (или неэффективными), один из них объявляют лучшим.
Два события называются независимыми, если наступление одного из них никак не влияет на наступление другого. Аналогично, две совокупности можно назвать независимыми, если свойства одной из них никак не связаны со свойствами другой.
Пример выполнения t -теста в программе STATISTICA.
Женщины в среднем ниже мужчин, однако, это не является результатом того, что мужчины оказывают какое-либо влияние на женщин — дело здесь в генетических особенностях пола. С помощью t- теста необходимо проверить, имеется ли статистически значимое различие между средними значениями роста в группах мужчин и женщин. (В учебных целях мы допускаем, что данные о росте подчиняются закону нормального распределения и поэтому t- тест применим).
Рисунок 1. Пример оформления данных для выполнения t-
Обратите внимание на то, как оформлены данные на рисунке 1. Как и при построении графиков типа Whisker plot или Box-whisker plot , в таблице имеются две переменные: одна из них — группирующая (Grouping variable ) («Пол») — содержит коды (муж и жен), позволяющие программе установить, какие из данных о росте принадлежат какой группе; вторая — т.н. зависимая переменная (Dependent variable ) («Рост») — содержит собственно анализируемые данные. Однако при выполнении t- теста для независимых выборок в программе STATISTICA возможен и другой вариант оформления — данные для каждой из групп («Мужчины» и «Женщины») можно ввести в отдельные столбцы (рисунок 2).
Рисунок 2. Еще один вариант оформления данных для выполнения t- теста для независимых выборок
Для выполнения t- теста для независимых выборок необходимо выполнить следующие действия:
1-а. Запустить модуль t- теста из меню Statistics > Basic statistics/Tables > t -test , independent, by groups (если в таблице с данными есть группирующая переменная, см.рисунок 3)
Запустить модуль t- теста из меню Statistics > Basic statistics/Tables > t -test , independent, by groups (если в таблице с данными есть группирующая переменная, см.рисунок 3)
ИЛИ
1-б. Запустить модуль t- теста из меню Statistics > Basic statistics/Tables > t -test, independent, by variables (если данные внесены в самостоятельные столбцы, см. рисунок 4).
Ниже описывается вариант теста, при котором в таблице с данными имеется группирующая переменная.
2. В открывшемся окне нажать кнопку Variables и указать программе, какая из переменных таблицы Sreadsheet является группирующей, а какая — зависимой (рисунки 5-6).
Рисунок 5. Выбор переменных для включения в t -тест
Рисунок 6. Окно с выбранными переменными для проведения t -теста
3. Нажать на кнопку Summary: T-tests .
Рисунок 7. Результы t -теста для независимых выборок
В итоге программа выдаст рабочую книгу Workbook , содержащую таблицу с результатами t -теста (рисунок 7 ). Эта таблица имеет несколько столбцов:
- Mean (муж) — среднее значение роста в группе «Мужчины»;
- Mean (жен) — среднее значение роста в группе «Женщины»;
- t- value : значение рассчитанного программой t -критерия Стьюдента;
- df — число степеней свободы;
- P — вероятность справедливости гипотезы о том, что сравниваемые средние значения не различаются. Фактически, это самый главный результат анализа, поскольку именно значение P говорит, верна ли проверяемая гипотеза. В нашем примере P > 0.05, из чего можно сделать вывод о том, что статистически значимые различия между ростом мужчин и женщин отсутствуют.
- Valid N (муж) — объем выборки «Мужчины»;
- Valid N (жен) — объем выборки «Женщины»;
- Std. dev . (муж) — стандартное отклонение выборки «Мужчины»;
- Std. dev . (жен) — стандартное отклонение выборки «Женщины»;
- F-ratio, Variances — значение F-критерия Фишера, с помощью которого проверяется гипотеза о равенстве дисперсий в сравниваемых выборках;
- P, Variances — вероятность справедливости гипотезы о том, что дисперсии сравниваемых выборок не различаются.
 dev . (муж) — стандартное отклонение выборки «Мужчины»;
dev . (муж) — стандартное отклонение выборки «Мужчины»;Чаще всего в психологическом исследовании наблюдается задачи на выявление различий между двумя или более группами признаков. Выяснение таких различий на уровне средних арифметических рассмотрено в процедуре анализа первичных статистик. Однако возникает вопрос, насколько эти различия достоверны и можно ли их распространить (экстраполировать) на всю популяцию. Для решения этой задачи чаще всего используют (при условии нормального или близкого к нормальному распределению) t — критерий (критерий Стьюдента), который предназначен для выяснения, насколько достоверно отличаются показатели одной выборки испытуемых от другой (например, когда исследуемые получают в результате тестирования одной группы высшие баллы, чем представители другой). Это параметрический критерий, имеет две основные формы:
Это параметрический критерий, имеет две основные формы:
1) несвязанный (нечетная) t — критерий, предназначенный для того, чтобы выяснить, есть ли различия между оценками, полученными при использовании одного и того же теста для тестирования двух групп, сформированных из разных людей. Например, это может быть сравнение уровня интеллекта или нервно-психической устойчивости, тревожности успевающих и неуспевающих учеников или сравнение по этим признакам учеников разных классов, возрастов, социальных уровней и тому подобное. Могут быть и разнополые, разнонациональные выборки, а также подвыборки в исследуемых выборках, выделены по определенному признаку. Критерий называют «несвязанный», потому что сравниваемые группы сформированы из разных людей;
2) связан (парный) t — критерий, применяемый для сравнения показателей двух групп, между элементами которых существует специфическая связь. Это означает, что каждому элементу первой группы соответствует элемент второй группы, похожий на него по определенным параметром интересующей исследователя. Чаще всего сравнивают параметры одних и тех же лиц до и после определенного события или действия (например, в процессе проведения лонгитюдного исследования или формирующего эксперимента). Поэтому этот критерий используют для сравнения показателей одних и тех же лиц до и после обследования, эксперимента или истечении определенного времени.
Чаще всего сравнивают параметры одних и тех же лиц до и после определенного события или действия (например, в процессе проведения лонгитюдного исследования или формирующего эксперимента). Поэтому этот критерий используют для сравнения показателей одних и тех же лиц до и после обследования, эксперимента или истечении определенного времени.
Если данные не подлежат нормальному закону распределения, используют непараметрические критерии, эквивалентные t — критерия: критерий Манна — Уитни, эквивалентный нечетном t — критерия, и Двухвыборочный критерий Вилкоксона, эквивалентный парном t — критерия.
С помощью t — критериев и их непараметрических эквивалентов можно только сравнивать результаты двух групп, полученные с использованием одного и того же теста. Однако в некоторых случаях возникает необходимость сравнения нескольких групп или оценок нескольких видов. Это можно сделать поэтапно, разбив задачу на несколько пар сравнений (например, если надо сравнить группы А, Б и Y по результатам тестов X и Y, то можно с помощью t — критерия сначала сравнить группы А и Б по результатам теста X, затем А и Б по результатам теста В, А и В по результатам теста Х и т. д.). Однако это очень трудоемкий метод, поэтому прибегают к более сложному методу дисперсионного анализа.
д.). Однако это очень трудоемкий метод, поэтому прибегают к более сложному методу дисперсионного анализа.
Метод оценки достоверности различий средних арифметических по достаточно эффективным параметрическим критерием Стьюдента предназначен для решения одной из задач, чаще всего наблюдаются при обработке данных — выявление достоверности различий между двумя или более рядами значений. Такая оценка часто необходимо при сравнительном анализе полярных групп. их выделяют на основе различной выраженности определенной целевой признаки (характеристики) изучаемого явления. Как правило, анализ начинают с подсчета первичных статистик выделенных групп «, затем оценивают достоверность различий. Критерий Стьюдента вычисляют по формуле:
Значение критерия Стьюдента для трех уровней доверительной (статистической) значимости (р) приводят в справочниках по матстатистику. Количество степеней свободы определяют по формуле:
С уменьшением объемов выборок (n
Решение о достоверности различий принимают в том случае, если исчисленная величина t превышает табличное значение для определенного количества степеней свободы (d (v)). В публикациях или научных отчетах указывают высокий уровень значимости из трех: р
В публикациях или научных отчетах указывают высокий уровень значимости из трех: р
При любом числового значения критерия достоверности различия между средними этот показатель оценивает не степень выявленной различия (ее оценивают по самой разницей между средними), а только его статистическую достоверность, то есть право распространять полученный на основе сопоставления выборок вывод о наличии разницы на все явление (весь процесс) в целом. Низкий исчисленный критерий отличия не может служить доказательством отсутствия различия между двумя признаками (явлениями), потому что его значимость (степень достоверности) зависит не только от величины средних, но и от количества сравниваемых выборок. Он указывает не на отсутствие различия, а на то, что при такой величины выборок она статистически недостоверная: очень большой шанс, что разница в этих условиях случайная, очень мала вероятность ее достоверности.
Таблица 2.17. Доверительные границы для критерия Стьюдента (t-критерий) для f степеней свободы
ния среднего времени выполнения задания во второй попытке (по сравнению с первой пробой) не является достоверным.
Это выражение не равносильно утверждению о статистической однородности двух выборок, которые сопоставляют. Кроме того, применение критерия Стьюдента в случае таких неодинаковых выборок не вполне корректное математически и, безусловно, сказывается на конечном итоге о недостоверности различий Хср = 9,1 и Хср = 8,5. Пользуясь этим критерием, оценивают не степень близости двух средних, а рассматривают отнесения или невод несения случайной (при заданном уровне значимости). .
где f – степень свободы, которая определяется как
Пример . Две группы студентов обучались по двум различным методикам. В конце обучения с ними был проведен тест по всему курсу. Необходимо оценить, насколько существенны различия в полученных знаниях. Результаты тестирования представлены в таблице 4.
Таблица 4
Рассчитаем выборочное среднее, дисперсию и стандартное отклонение:
Определим значение t p по формуле t p = 0,45
По таблице 1 (см. приложение) находим критическое значение t k для уровня значимости р = 0,01
Вывод: так как расчетное значение критерия меньше критического 0,45
Алгоритм расчета t-критерия Стьюдента для зависимых выборок измерений
1. Определить расчетное значение t-критерия
по формуле
Определить расчетное значение t-критерия
по формуле
,
где
3. Определить критическое значение t-критерия по таблице 1 приложения.
4. Сравнить расчетное и критическое значение t-критерия. Если расчетное значение больше или равно критическому, то гипотеза равенства средних значений в двух выборках изменений отвергается (Но). Во всех других случаях она принимается на заданном уровне значимости.
U — критерий Манна — Уитни
Назначение критерия
Критерий предназначен для оценки различий между двумя непараметрическими выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявлять различия между малыми выборками, когда n
Описание критерия
Этот
метод определяет, достаточно ли мала
зона пересекающихся значений между
двумя рядами. Чем меньше эта область,
тем более вероятно, что различия
достоверны. Эмпирическое значение
критерия U
отражает то, насколько велика зона
совпадения между рядами. Поэтому чем
меньше U,
тем
более вероятно,
что различия достоверны.
Эмпирическое значение
критерия U
отражает то, насколько велика зона
совпадения между рядами. Поэтому чем
меньше U,
тем
более вероятно,
что различия достоверны.
Гипотезы
НО: Уровень признака в группе 2 не ниже уровня признака в группе 1.
HI: Уровень признака в группе 2 ниже уровня признака в группе 1.
Алгоритм расчета критерия Манна-Уитни (u)
Перенести все данные испытуемых на индивидуальные карточки.
Пометить карточки испытуемых выборки 1 одним цветом, скажем красным, а все карточки из выборки 2 – другим, например, синим.
Разложить все карточки в единый ряд по степени нарастания признака, не считаясь с тем, к какой выборке они относятся, как если бы мы работали с одной большой выборкой.
где n 1 – количество испытуемых в выборке 1;
n 2 – количество испытуемых в выборке 2,
Т х – большая из двух рантовых сумм;
n х
– количество испытуемых в группе с
большей суммой рангов.
9. Определить критические значения U по таблице 2 (см. приложение).
Если U эмп.> U кр0,05 , то гипотеза Но принимается. Если U эмп.≤ U кр, то отвергается. Чем меньше значения U, тем достоверность различий выше.
Пример. Сравнить эффективность двух методов обучения в двух группах. Результаты испытаний представлены в таблице 5.
Таблица 5
Перенесем все данные в другую таблицу, выделив данные второй группы подчеркиванием и сделаем ранжирование общей выборки (см. алгоритм ранжирования в методических указаниях к заданию 3).
Найдем сумму рангов двух выборок и выберем большую из них: Т х = 113
Рассчитаем эмпирическое значение критерия по формуле 2: U p = 30.
Определим по таблице 2 приложения критическое значение критерия при уровне значимости р = 0.05: U k = 19.
Вывод: так
как расчетное значение критерия U больше критического при уровне значимости
р = 0.05 и 30 > 19, то гипотеза о равенстве
средних принимается и различия в
методиках обучения несущественны .
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Общий подход в проверке гипотез описан , поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ 2 (знаю-знаю, что так не бывает, но не нужно меня перебивать!). Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь с математическим ожиданием μ и
Тогда случайная величина
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96s x̅ . Другими словами, являются ли распределения случайных величин
Другими словами, являются ли распределения случайных величин
эквивалентными.
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннеса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Собрав математическое обоснование и рассчитав значения функции обнаруженного им распределения, химик из Дублина Уильям Госсет написал заметку, которая была опубликована в мартовском выпуске 1908 года журнала «Биометрика» (главред – Карл Пирсон). Т.к. Гиннесс строго-настрого запретил выдавать секреты пивоварения, Госсет подписался псевдонимом Стьюдент.
Несмотря на то что, К. Пирсон уже изобрел распределение , все-таки всеобщее представление о нормальности еще доминировало. Никто не собирался думать, что распределение выборочных оценок может быть не нормальным. Поэтому статья У. Госсета осталась практически не замеченной и забытой. И только Рональд Фишер по достоинству оценил открытие Госсета. Фишер использовал новое распределение в своих работах и дал ему название t-распределение Стьюдента . Критерий для проверки гипотез, соответственно, стал t-критерием Стьюдента . Так произошла «революция» в статистике, которая шагнула в эру анализа выборочных данных. Это был краткий экскурс в историю.
Поэтому статья У. Госсета осталась практически не замеченной и забытой. И только Рональд Фишер по достоинству оценил открытие Госсета. Фишер использовал новое распределение в своих работах и дал ему название t-распределение Стьюдента . Критерий для проверки гипотез, соответственно, стал t-критерием Стьюдента . Так произошла «революция» в статистике, которая шагнула в эру анализа выборочных данных. Это был краткий экскурс в историю.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅ ) 50 и среднеквадратичным отклонением (σ ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию :
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.
Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию .
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t .
Видно, что распределения на этот раз не очень-то и совпадают. Близки, да, но не одинаковы. Хвосты стали более «тяжелыми».
У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s 2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ 2 (хи-квадрат) с таким же количеством степеней свободы, т.е.
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
На этом законе основывается множество других результатов в статистике нормальных моделей.
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
на σ X̅ . Получим
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.
Тогда исходное выражение примет вид
Это и есть в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Все равно ей никто не пользуется, т.к. вероятности приведены в специальных таблицах распределения Стьюдента (иногда называют таблицами коэффициентов Стьюдента), либо забиты в формулы ПЭВМ.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ 2 k подчиняется распределению χ 2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
Есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.
При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двухсторонним. Обычно пользуются двухсторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность, т.к. при фиксированном уровне значимости критическое значение немного приближается к нулю.
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.
Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.
Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП – «классическое» левостороннее t-распределение Стьюдента. На вход подается значение t-критерия, количество степеней свободы и опция (0 или 1), определяющая, что нужно рассчитать: плотность или значение функции. На выходе получаем, соответственно, плотность или вероятность того, что случайная величина окажется меньше указанного в аргументе t-критерия.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия, т.е. фактический уровень значимости (p-level).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ. РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-level.
РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-level.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α , а для правого 1 — α .
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α . Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-level.
На выходе получим p-level.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅ ) составила 50,3кг, среднеквадратичное отклонение (s ) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
H 0: μ = 50 кг
H 1: μ ≠ 50 кг
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двухсторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей t-распределения Стьюдента (есть в любом учебнике по статистике).
По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двухсторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975.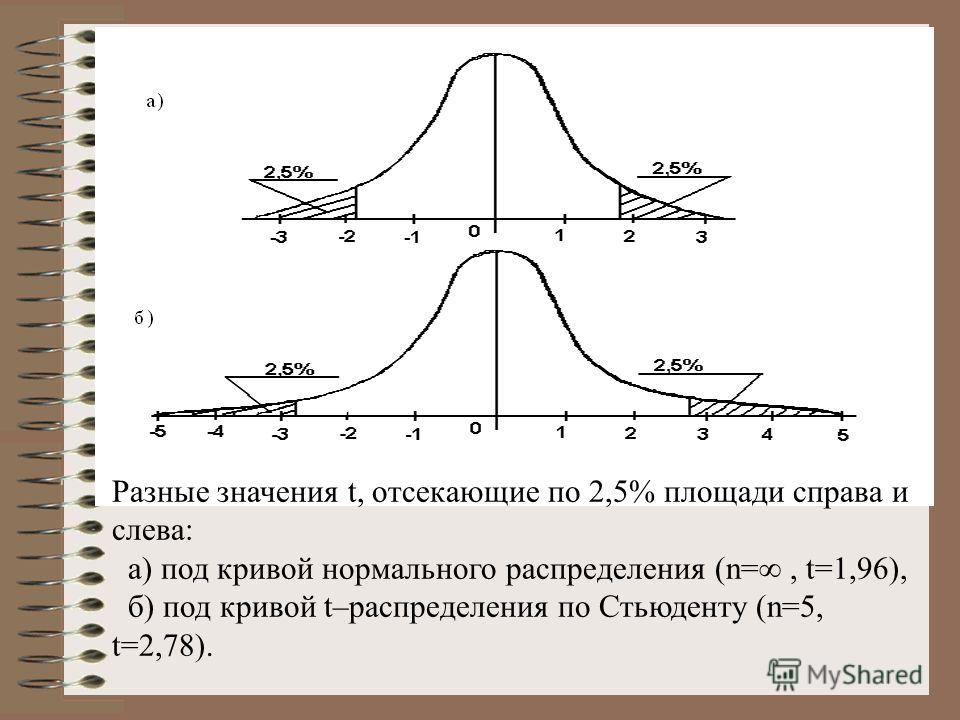 Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H 0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-level попробовать найти, но он будет приближенным. А, как правило, именно p-level используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.
Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двухсторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.
Найдем вначале критическое значение. Альфа берем 0,05, критерий двухсторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.
Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-level, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.
P-level равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-level оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.
Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-level (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала с помощью t-распределения Стьюдента
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов .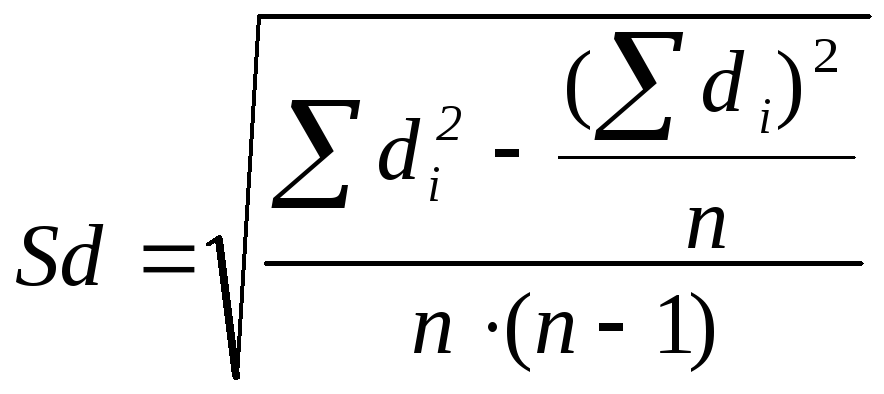 Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α , стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.
Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-level, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю посмотреть видеоролик о том, как проводить расчеты, связанные с t-критерием Стьюдента в Excel.
История
Данный критерий был разработан Уильямом Госсеттом для оценки качества пива в компании Гиннесс . В связи с обязательствами перед компанией по неразглашению коммерческой тайны (руководство Гиннесса считало таковой использование статистического аппарата в своей работе), статья Госсета вышла в 1908 году в журнале «Биометрика» под псевдонимом «Student» (Студент).
В связи с обязательствами перед компанией по неразглашению коммерческой тайны (руководство Гиннесса считало таковой использование статистического аппарата в своей работе), статья Госсета вышла в 1908 году в журнале «Биометрика» под псевдонимом «Student» (Студент).
Требования к данным
Для применения данного критерия необходимо, чтобы исходные данные имели нормальное распределение . В случае применения двухвыборочного критерия для независимых выборок также необходимо соблюдение условия равенства дисперсий . Существуют, однако, альтернативы критерию Стьюдента для ситуации с неравными дисперсиями.
Двухвыборочный t-критерий для независимых выборок
В случае с незначительно отличающимся размером выборки применяется упрощённая формула приближенных расчётов:
В случае, если размер выборки отличается значительно, применяется более сложная и точная формула:
Где M 1 ,M 2
— средние арифметические, σ 1 ,σ 2
— стандартные отклонения, а N 1 ,N 2
— размеры выборок.
Двухвыборочный t-критерий для зависимых выборок
Для вычисления эмпирического значения t-критерия в ситуации проверки гипотезы о различиях между двумя зависимыми выборками (например, двумя пробами одного и того же теста с временным интервалом) применяется следующая формула:
где M d — средняя разность значений, а σ d — стандартное отклонение разностей.
Количество степеней свободы рассчитывается как
Одновыборочный t-критерий
Применяется для проверки гипотезы об отличии среднего значения от некоторого известного значения :
Количество степеней свободы рассчитывается как
Непараметрические аналоги
Аналогом двухвыборочного критерия для независимых выборок является U-критерий Манна-Уитни . Для ситуации с зависимыми выборками аналогами являются критерий знаков и T-критерий Вилкоксона
Автоматический расчет t-критерия Стьюдента
Wikimedia Foundation . 2010 .
Смотреть что такое «T-критерий Стьюдента» в других словарях:
Критерий Стьюдента t-к — Критерий Стьюдента, t к. * крытэрый Ст’юдэнта, t к. * Student’s criterion or t c. or S. t test статистический критерий существенности разности между сравниваемыми средними. Определяется отношением этой разности к ошибке разности: При значениях t… … Генетика. Энциклопедический словарь
* крытэрый Ст’юдэнта, t к. * Student’s criterion or t c. or S. t test статистический критерий существенности разности между сравниваемыми средними. Определяется отношением этой разности к ошибке разности: При значениях t… … Генетика. Энциклопедический словарь
T критерий Стьюдента общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на сравнении с распределением Стьюдента. Наиболее частые случаи применения t критерия связаны с проверкой равенства… … Википедия
критерий Стьюдента — Stjūdento kriterijus statusas T sritis augalininkystė apibrėžtis Skirtumo tarp dviejų vidurkių patikimumo rodiklis, išreiškiamas skirtumo ir jo paklaidos santykiu. atitikmenys: angl. Student’s test rus. критерий Стьюдента … Žemės ūkio augalų selekcijos ir sėklininkystės terminų žodynas
критерий Стьюдента — Статистический критерий, в котором, в предположении нулевой гипотезы, используемая статистика соответствует t распределению (распределению Стьюдента). Примечание. Вот примеры применения этого критерия: 1. проверка равенства среднего из… … Словарь социологической статистики
Примечание. Вот примеры применения этого критерия: 1. проверка равенства среднего из… … Словарь социологической статистики
КРИТЕРИЙ СТЬЮДЕНТА — Биометрический показатель достоверности разницы (td) между средними значениями двух сравниваемых между собой групп животных (M1 и М2) по какому либо признаку. Достоверность разницы определяется по формуле: Полученное значение td сравнивается с… … Термины и определения, используемые в селекции, генетике и воспроизводстве сельскохозяйственных животных
КРИТЕРИЙ СТЬЮДЕНТА — оценивает близость двух средних значений с точки зрения отнесения или не отнесения ее к случайной (при заданном уровне значимости), отвечая на вопрос о том, отличаются ли средние значения статистически достоверно друг от друга }
t-Критерий Стьюдента
Если однажды перед вами оказывались два набора похожих данных, вам, вероятно, приходило в голову задаться вопросом: насколько эти данные различаются между собой? Или, что еще более важно, наблюдаются ли статистически значимые различия между этими выборками?
Поясню, о чем идет речь.
Допустим, вы проанализировали звонки за прошедший год и обратили внимание, что среднее время звонка в первой половине дня — 2 мин 45 сек, а во второй половине дня — 2 мин 57 сек. Следует ли из этого, что звонки после обеда в среднем длятся дольше? Или это простое совпадение, и, возьми вы звонки за год до этого, вы бы увидели другую картину?
Или, например, вы замеряли уровень гемоглобина у контрольной группы до начала исследований нового лекарства, и после. Предположим, средний уровень вырос с 142,5 г/л до 147,1 г/л. Достаточно ли опираться на увеличение среднего, чтобы сделать заключение об эффективности лекарства? Или, возможно, исследование нужно повторить? Увеличив размер контрольной группы, например?
Уже из постановки вопроса очевидно, что одной разницы между средними в двух выборках недостаточно, чтобы научно подтвердить их различие.
Вот почему мы обратимся к формуле расчета и таблице значений t-критериев Стьюдента, чтобы научиться делать математически корректные выводы о статистически значимых различиях между двумя выборками. Или, другими словами, научиться видеть разницу, когда она не заметна, или игнорировать ее, даже если кажется, что она есть.
Или, другими словами, научиться видеть разницу, когда она не заметна, или игнорировать ее, даже если кажется, что она есть.
Рассмотрим вопрос на примере.
Анализ длительности звонков Асланян и Евтушенко
В вашем отделе продаж работают 2 менеджера — Ольга Асланян и Кирилл Евтушенко. Вы получили данные по длительности их разговоров с покупателями и хотите проверить гипотезу, что разговоры Асланян в среднем длятся дольше разговоров Евтушенко.
Посчитаем среднюю длительность звонка, стандартное отклонение и число звонков, которые попали в выборке.
=СРЗНАЧ(B2:B999)=СТАНДОТКЛОН(B2:B999)=СЧЁТ(B2:B999)В среднем, звонки Асланян длятся на 34,5 сек дольше звонков Евтушенко. (Кроме того, разброс длительности ее звонков больше, т. к. больше стандартное отклонение. Грубо говоря, короткие и длинные звонки у Асланян найти проще, чем у Евтушенко).
Достаточно ли полученных данных, чтобы сделать вывод о правильности гипотезы, что Асланян в среднем дольше общается с клиентами, чем Евтушенко? На самом деле, нет. Всегда существует вероятность, что в выборку Асланян случайно попали более длинные звонки, а в выборку Евтушенко — более короткие. Чем больше звонков доступно для анализа (а нам достались 242 и 209 звонков, что не так уж и мало), тем более надежен результат, но он никогда не надежен на 100%.
Всегда существует вероятность, что в выборку Асланян случайно попали более длинные звонки, а в выборку Евтушенко — более короткие. Чем больше звонков доступно для анализа (а нам достались 242 и 209 звонков, что не так уж и мало), тем более надежен результат, но он никогда не надежен на 100%.
Впрочем, надежность 100% нам и не нужна. Не ракету к Марсу запускаем. Даже если нам удастся проверить нашу гипотезу с вероятностью 90-95%, этого будет вполне достаточно для большинства случаев. Пускай мы оставим себе шанс ошибиться в 5-10% случаев, зато нам не нужно будет ждать несколько лет, чтобы накопить достаточно данных для анализа, и управленческие решения (разбор звонков с менеджером, анализ продаж, корректировки скриптов) мы сможем принять уже сейчас.
Рассмотрим два способа, как нам проверить, случайность ли, что звонки Асланян в среднем длиннее звонков Евтушенко.
Проверка гипотезы о равенстве среднего. Простой способ
И в Google Таблицах, и в Microsoft Excel, есть функция ТТЕСТ. Воспользуемся ей для анализа наших выборок.
Воспользуемся ей для анализа наших выборок.
=ТТЕСТ(B2:B999;C2:C999;2;3)У функции 4 атрибута, идущие через точку с запятой.
- Диапазон ячеек, содержащих первую выборку.
- Диапазон ячеек, содержащих вторую выборку.
- Количество хвостов распределения. Выбираем «2», чтобы проверить наличие различий вообще, и «1», чтобы проверить, звонки Асланян длиннее, а не наоборот.
- Тип применения t-критерия. По умолчанию выбираем «3». («2» выбираем если стандартные отклонения очень близки, «1» — если, например, вы сравниваете средний балл одних и тех же учеников на начало и конец года попарно.)
Итак, Т-тест дал вероятность 0,04595, или, округленно, 4,6%.
Что же это за вероятность? В нашем примере это вероятность того, что статистически значимые различия между звонками Асланян и Евтушенко отсутствуют. Технически, это вероятность, что наша «нулевая гипотеза» («нет разницы между выборками») была верна, а «альтернативная» («Асланян общается с покупателями дольше Евтушенко») — неверна.
Оставшиеся 95,4% составляют вероятность того, что между выборками есть статистические различия, и «альтернативная гипотеза» о различиях между выборками верна.
Вывод: с вероятностью 95,4% Асланян, действительно, в среднем общается с клиентами дольше Евтушенко. (С вероятностью 4,6% статистически значих различий между их звонками нет).
Проверка гипотезы о равенстве среднего. Сложный способ
Сложный способ будет состоит из двух этапов: расчет t-критерия Стьюдента и сравнение полученного значения t-критерия с контрольным.
На первом этапе рассчитаем t-критерий Стьюдента по следующей формуле:
X1 и X2 — средняя длина звонков в первой и второй выборке (238,6 сек и 204,1 сек)
s1 и s2 — стандартные отклонения первой и второй выборок в квадрате (их дисперсии, другими словами) (201,22 и 164,72 для наших выборок)
n1 и n2 — число звонков в первой и второй выборках (242 и 209 звонков)
Воспользуемся листочком бумаги и калькулятором, или же посчитаем все прямо в Google Таблицах:
=(F2-G2)/КОРЕНЬ(F3^2/F4+G3^2/G4)t-Критерий равен 2,0014.
Осталось разобраться, что делать с вычисленным значением нашего t-критерия.
Но перед этим посчитаем число степеней свободы по формуле n1+n2-2:
242 + 209 — 2 = 449 степеней свободы
Воспользуемся теперь таблицей коэффициентов Стьюдента из Википедии, найдя строку, соответствующую нашим 449 степеням свободы.
В нашем случае, строки именно для числа 449 нет, зато несложно заметить, что значения для 100 и 1000 — ближайших подходящих строк — отличаются на сотые доли, поэтому для большого числа степеней свободны подойдет любая строка.
Наше значение 2,0014 находится между 1,9623 и 2,3301: 1,9623
В шапке таблицы это соответствует 95%-му и 98%-му квантилю распределения Стьюдента, т. е. мы захватили 95%-й квантиль, но не захватили 98%-й:
Если расчетное значение t-критерия Стьюдента больше контрольного, значит, «альтернативная гипотеза» верна с соответствующей вероятностью (95%), и выборки статистически различаются.
Если бы мы получили значение t-критерия больше, чем 2,3301 (98%), мы бы могли говорить по правильности «альтернативной гипотезы» уже с 98%-й вероятностью. Аналогично, если бы мы получили значение t-критерия меньше, чем 1,9623 (95%), но больше 1,6464 (90%), мы бы говорили о правильности гипотезы на 90%.
Вывод: расчетное значение t-критерия Стьюдента 2,0014 соответствует, по меньшей мере, 95% уверенности в том, что между выборками есть статистически значимые различия, и звонки Асланян, действительно, в среднем длиннее звонков Евтушенко.
Наша «альтернативная гипотеза» получила 95%-ое подтверждение, мы можем быть уверены в результате и принимать решение о дальнейшей работе с полученный информацией.
Полезные ссылки
http://www.evanmiller.org/ab-testing/t-test.html
F-критерии, t-критерий Стьюдента | Эпидемиология
F-критерии — показатель степеней различий и сходств результатов
измерений двух серий опытов или воспроизводимости двух методов. Рассчитыва-
Рассчитыва-
ется по формуле: F = σ2А/σ2B,
где: F — F-критерий; σ2 — степень дисперсии (отклонения) вариант от средней величины опытов А и В, причем σА>σB.
Величину F сопоставляют с табличными критическими значениями, которых обычно достаточно для сравнения степеней сходства и воспроизводимости результатов измерений. При необходимости в большинстве руководств по статистике можно найти более информативные таблицы, отражающие различные уровни достоверности различий для разных степеней свободы.
Минимальная величина f-критерия, определяющая достоверность различий дисперсий вариант при р<0,01 (по В.В. Власову, 1988)
Примечание: Q = n-1; QA — число степеней свободы в опыте A; QB — число степеней свободы в опыте В.
t-критерий Стьюдента — наиболее популярный в медицинских исследованиях тест на достоверность различий средних величин, сравниваемых выборок, полученных напр. , при эпидемиологических исследованиях. Определяется по формуле:
, при эпидемиологических исследованиях. Определяется по формуле:
где x1, х2 — сравниваемые (сопоставляемые) средние величины; m1, m2 — соответствующие средние (стандартные) ошибки.
Абсолютная величина t-критерия сопоставляется с его граничным значением (табл. 2).
Граничные значения t-критерия (по Стьюденту, 1958)
Примечание:
- Q — число степеней свободы; Q = n-l;
- Различие с истинным значением среднего (правильность) также оценивается с помощью t-критерия.
Похожие статьи:
Примите к сведению
Информация на этом сайте представлена в справочных и образовательных целях и не должна быть использована как инструкция по лечению. В любых случаях необходимо консультироваться у врача.
T-тест Стьюдента | Определение, формула и пример
T-критерий Стьюдента в статистике — метод проверки гипотез о среднем значении небольшой выборки, взятой из нормально распределенной совокупности, когда стандартное отклонение генеральной совокупности неизвестно.
В 1908 году Уильям Сили Госсет, англичанин, публикующийся под псевдонимом Стьюдент, разработал t- критерий и t- распределение. (Gosset работал в Guinness пивоварни в Дублине и обнаружили , что существующие статистические методы с использованием больших образцов не были полезны для малых размеров выборки , что он столкнулся в своей работе.) В т Распределение — это семейство кривых, в которых количество степеней свободы (количество независимых наблюдений в выборке минус одна) определяет конкретную кривую. По мере увеличения размера выборки (и, следовательно, степеней свободы) t- распределение приближается к форме колокола стандартного нормального распределения . На практике для тестов, включающих среднее значение выборки размером более 30, обычно применяется нормальное распределение.
Обычно сначала формулируют нулевая гипотеза , которая утверждает, что нет эффективной разницы между наблюдаемым средним по выборке и гипотетическим или заявленным средним значением генеральной совокупности, т. е. что любое измеренное различие обусловлено только случайностью . Например, в сельскохозяйственном исследовании нулевая гипотеза может заключаться в том, что внесение удобрений не повлияло на урожайность, и будет проведен эксперимент, чтобы проверить, увеличило ли оно урожай. В общем, t- критерий может быть либо двусторонним (также называемым двусторонним), просто утверждая, что средства не эквивалентны, либо односторонним, определяя, больше или меньше наблюдаемое среднее, чем предполагаемое среднее. ТестЗатем вычисляется статистика t . Если наблюдаемая t- статистика является более экстремальной, чем критическое значение, определенное соответствующим эталонным распределением, нулевая гипотеза отклоняется. Подходящим эталонным распределением для t- статистики является t- распределение. Критическое значение зависит от уровня значимости теста (вероятность ошибочного отклонения нулевой гипотезы).
е. что любое измеренное различие обусловлено только случайностью . Например, в сельскохозяйственном исследовании нулевая гипотеза может заключаться в том, что внесение удобрений не повлияло на урожайность, и будет проведен эксперимент, чтобы проверить, увеличило ли оно урожай. В общем, t- критерий может быть либо двусторонним (также называемым двусторонним), просто утверждая, что средства не эквивалентны, либо односторонним, определяя, больше или меньше наблюдаемое среднее, чем предполагаемое среднее. ТестЗатем вычисляется статистика t . Если наблюдаемая t- статистика является более экстремальной, чем критическое значение, определенное соответствующим эталонным распределением, нулевая гипотеза отклоняется. Подходящим эталонным распределением для t- статистики является t- распределение. Критическое значение зависит от уровня значимости теста (вероятность ошибочного отклонения нулевой гипотезы).
Например, предположим, что исследователь хочет проверить гипотезу о том, что выборка размером n = 25 со средним значением x = 79 и стандартным отклонением s = 10 была отобрана случайным образом из совокупности со средним значением μ = 75 и неизвестным стандартным отклонением. Используя формулу t- статистики,вычисленное t равно 2. Для двустороннего теста с общим уровнем значимости α = 0,05 критические значения t- распределения по 24 степеням свободы равны -2,064 и 2,064. Расчетное значение t не превышает этих значений, поэтому нулевая гипотеза не может быть отклонена с 95-процентной достоверностью. (Уровень достоверности 1 — α.)
Используя формулу t- статистики,вычисленное t равно 2. Для двустороннего теста с общим уровнем значимости α = 0,05 критические значения t- распределения по 24 степеням свободы равны -2,064 и 2,064. Расчетное значение t не превышает этих значений, поэтому нулевая гипотеза не может быть отклонена с 95-процентной достоверностью. (Уровень достоверности 1 — α.)
Второе применение t- распределения проверяет гипотезу о том, что две независимые случайные выборки имеют одинаковое среднее значение. Распределение t также можно использовать для построения доверительных интервалов для истинного среднего значения генеральной совокупности (первое приложение) или для разницы между двумя выборочными средними значениями (второе приложение). См. Также интервальную оценку .
Гавайи Министерство энергетики | Взвешенная формула студента
Нажмите, чтобы
загрузите информационный бюллетень о финансировании WSF и запросе на операционный бюджет на 2021 финансовый год.
О WSF
Формула взвешенного студента справедливо распределяет средства из текущего бюджета школам в зависимости от количества учащихся, которых они обслуживают, а также потребностей и характеристик этих учащихся. Оценки WSF производятся в течение года с учетом последних данных о зачислении и распределении.Эти отчеты предоставляются школам, чтобы они могли составлять свои финансовые планы на предстоящий учебный год; Финансовый план определяет расходы школы на персонал, программы, ресурсы и многое другое (см. ниже или ознакомьтесь с нашими информационный бюллетень для подробностей). Как работает WSF:
- Базовое финансирование предоставляется каждой школе в зависимости от типа
- Определенная сумма в долларах выделяется на обучение каждого зачисленного учащегося
- Дополнительные деньги выделяются на обучение учащихся с определенными характеристиками, влияющими на их обучение и успеваемость .К ним относятся, среди прочего:
- Одаренные и талантливые
- Экономические недостатки
- Ограниченное владение английским языком (изучающие английский язык)
- Быстротечность
Просмотреть полный список на основе различных весов и расчетов на основе различных весов и расчетов. здесь. Узнать больше о
как устанавливаются весы.
здесь. Узнать больше о
как устанавливаются весы.
ЗАКОНОДАТЕЛЬНЫЕ БЮДЖЕТНЫЕ ЗАПРОСЫ
В течение
бюджетного процесса (до открытия Законодательной сессии), Департамент может подать запрос на увеличение взвешенной формулы студента.Эти запросы могут быть основаны на прогнозируемом увеличении количества учащихся в штате, рекомендациях Совета по образованию или других источниках.
ФИНАНСОВЫЕ ПЛАНЫ
На основе долларов, доступных в рамках WSF, каждый директор школы, работающий в тандеме с Советом школьного сообщества, составляет годовой финансовый план для финансирования академического плана школы и основных операций. В прошлом директорам было трудно принимать образовательные решения, когда они не знали, сколько денег они получат.Благодаря прямому школьному финансированию директора теперь решают, как расходовать значительную часть средств Департамента.
операционный бюджет. Это позволяет директорам планировать и управлять своей школой, чтобы наилучшим образом удовлетворить образовательные потребности своих учеников. Мы призываем родителей и сообщество принять участие в разработке финансового плана школы , присоединившись к
Совет школьного сообщества в их районе. Соответствующие документы на 2022-23 финансовый год:
Мы призываем родителей и сообщество принять участие в разработке финансового плана школы , присоединившись к
Совет школьного сообщества в их районе. Соответствующие документы на 2022-23 финансовый год:
НОВАЯ ФОРМУЛА ФИНАНСИРОВАНИЯ ДЛЯ СПЕЦИАЛЬНОГО ОБРАЗОВАНИЯ
Начиная с 2020-21 финансового года, в соответствии с рекомендацией Целевой группы по специальному образованию
Распределение средств на специальное образование на одного учащегося (SPPA) — аналогично WSF будет использоваться для выплаты средств на специальное образование:
- Базовое финансирование в размере 66 000 долларов США для каждой школы
- Использование выбранных характеристик учащихся как 0.1 веса:
- Другое здоровье Отключено
- Другое здоровье Отключено
- Речь или язык Отключено
- Финансирование для каждого ученика начинается с пятого студента
- баланса:
- 90% выделено в школы в зависимости от численности персонала
- 10% выделено школам по усмотрению начальника комплексного района (CAS)
Особые изучения отключено
Узнайте больше о программе специального образования
здесь.
КОРРЕКТИРОВКИ ЗАЧИСЛЕНИЙ
Корректировки распределения на основе обновленных данных о зачислении производятся три раза в течение года. Первая корректировка производится на основе официального подсчета зачислений (OEC), проведенного вскоре после начала учебного года. Ассигнования WSF для каждой школы пересчитываются на основе их официального зачисления, обновленной демографической информации и окончательных ассигнований WSF, доступных Департаменту. Ассигнования школы могут быть увеличены или уменьшены на основе этого перерасчета.
Вторая и третья корректировки вносятся на основании количества зачисленных в конце первой четверти (в сентябре или октябре) и в начале второго семестра (в январе) соответственно. В отличие от корректировки, сделанной для OEC, школы получат корректировку распределения только в случае увеличения числа учащихся. Соответствующие документы на 2021-22 финансовый год Корректировки зачисления:
Комитет по весам
Эта группа педагогов и членов сообщества собирается весной и летом для разработки рекомендуемых изменений для тонкой настройки WSF, которые представляются Совету по образованию. Во время этих встреч члены Комитета рассматривают характеристики учащихся, влияющие на стоимость обучения, и существующие виды средств, которые в настоящее время используются для поддержки обучения учащихся. Совет определяет состав Комитета по весам на основе рекомендации суперинтенданта и декана педагогического колледжа Гавайского университета. Комитет по весам был создан в соответствии с Законом 51 и Законом 221, принятым на Законодательной сессии 2004 года.
Во время этих встреч члены Комитета рассматривают характеристики учащихся, влияющие на стоимость обучения, и существующие виды средств, которые в настоящее время используются для поддержки обучения учащихся. Совет определяет состав Комитета по весам на основе рекомендации суперинтенданта и декана педагогического колледжа Гавайского университета. Комитет по весам был создан в соответствии с Законом 51 и Законом 221, принятым на Законодательной сессии 2004 года.
Основные функции Комитета по весам заключаются в том, чтобы определить:
- какие операционные средства должны быть размещены в едином распределении на основе характеристик учащихся,
- характеристики учащихся, используемые для выделения средств школам,
- сумма » вес» (или сумма признака по стоимости обучения) по каждому признаку и
- удельных единиц по каждому признаку.
КОМИТЕТ ПО ВЕСАМ XII
COW XII проводит свои заседания — повестка дня, протоколы и материалы заседаний доступны ниже:
Архивный комитет по весам ссылки
20 | корова X: SY2017-18 Корова IX: SY2016-17 Корова VIII: SY2014-15 Корова VII: Sy2012-13 | Корова VI: SY2011-12 Корова V: SY2010-11 Корова IV: SY2009-10 Корова III: SY2008-09 Корова II: SY2007-08 Корова I |
Оценки, исследования
2013 ВНЕШНЯЯ ОЦЕНКА. Аудит взвешенной студенческой формулы Гавайев, проведенный Американскими институтами исследований (AIR).
Аудит взвешенной студенческой формулы Гавайев, проведенный Американскими институтами исследований (AIR).
2005 ИССЛЕДОВАНИЕ АДЕКВАТНОСТИ. Исследование по разработке модели финансирования школ, проведенное Грантом Торнтоном в 2005 г.
- Студенты принимали активное участие в разработке новой системы демпфирования DSSV
- Конфигурации для обычной подвески с четырьмя углами или с передним и задним разъединением крена/вертикальной качки, разработанные специально для соревнований Formula SAE / Formula Student
- Команды из Канады и Великобритании, участвующие в пилотной программе
- Расширение глобальной программы запланировано на 2021 год
MARKHAM, Онтарио (9 марта 2020 г.) — Multimatic представляет новейшую разработку своей технологии золотниковых клапанов динамической подвески (DSSV) в виде изготовленных на заказ амортизаторов, разработанных для удовлетворения потребностей соревнований Formula SAE и Formula Student.
За последние два десятилетия амортизаторы Multimatic DSSV продемонстрировали превосходство на высших уровнях автоспорта и успешно перешли на серийные автомобили OEM. Эта проверенная технология вместе с инструментами разработки, необходимыми для оптимизации ее потенциала, теперь становится доступной для студентов и команд, участвующих в глобальных соревнованиях.
Новые амортизаторы, разработанные в результате сотрудничества между студентами-инженерами и командой Multimatic по динамике транспортных средств, используют архитектуру системы и картриджи золотниковых клапанов Multimatic GT и гоночных амортизаторов уровня прототипа.
В рамках пилотной программы три команды канадских университетов и одна команда из Великобритании сконфигурировали, собрали, отремонтировали и настроили комплект амортизаторов в соответствии со своими спецификациями и требованиями к транспортному средству в рамках подготовки к предстоящим испытаниям и соревнованиям.
Multimatic уже давно участвует в Formula SAE и Formula Student посредством судейства на мероприятиях, спонсорства команд и учреждения награды за динамику автомобиля на канадских соревнованиях Formula SAE North. Компания также осознает важность знакомства талантливых молодых инженеров с инновационными технологиями и оказания им помощи в развитии и обучении на основе практического опыта.
Компания также осознает важность знакомства талантливых молодых инженеров с инновационными технологиями и оказания им помощи в развитии и обучении на основе практического опыта.
Formula SAE и Formula Student, а также аналогичные программы играют решающую роль в подготовке следующего поколения ведущих инженеров и технологов отрасли, и компания Multimatic наняла многочисленных выпускников программ в свои инженерные подразделения по всему миру.
Доступен либо для обычной подвески с четырьмя углами, либо для подвески с передней и задней развязкой по крену/подъему. Группы пилотной программы будут тестировать и разрабатывать амортизаторы в течение 2020 года в рамках подготовки к расширенной программе Multimatic Formula SAE / Formula Student DSSV в 2021.
О Multimatic
Глобальная корпорация, основанная в 1984 году, поставляет инженерные компоненты, системы и услуги для автомобильной промышленности. Основные компетенции Multimatic включают проектирование и производство сложных механизмов, кузовного оборудования, систем подвески и конструкций кузова, а также проектирование и разработку легких композитных автомобильных систем.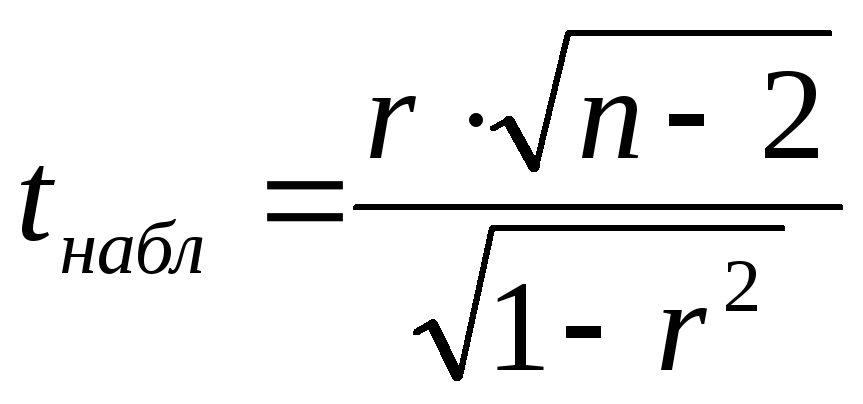 Кроме того, Multimatic занимается проектированием, разработкой и производством нишевых автомобилей для дорожных и гоночных автомобилей.Компания Multimatic со штаб-квартирой в Торонто, Канада, имеет производственные подразделения и инженерные подразделения в Северной Америке, Европе и Азии, а также партнерские отношения с партнерами по всему миру.
Кроме того, Multimatic занимается проектированием, разработкой и производством нишевых автомобилей для дорожных и гоночных автомобилей.Компания Multimatic со штаб-квартирой в Торонто, Канада, имеет производственные подразделения и инженерные подразделения в Северной Америке, Европе и Азии, а также партнерские отношения с партнерами по всему миру.
Контактное лицо:
Питер Гиббонс
Технический директор, Vehicle Dynamics
Если вас интересует программа демпферов, обращайтесь по адресу [email protected]
Формула Студент | Инженерная школа
Formula Student предлагает студентам университетов со всего мира спроектировать и построить одноместный гоночный автомобиль, который затем подвергается испытаниям на знаменитой трассе Сильверстоун.
Formula Student (FS) — самое известное в Европе образовательное соревнование по автоспорту, проводимое Институтом инженеров-механиков. Конкурс, поддерживаемый промышленностью и высококлассными инженерами, такими как Росс Браун ОБЕ, направлен на то, чтобы вдохновлять и развивать предприимчивых и инновационных молодых инженеров. Перед университетами со всего мира стоит задача спроектировать и построить одноместный гоночный автомобиль, чтобы участвовать в статических и динамических соревнованиях, демонстрирующих их понимание и проверяющих характеристики автомобиля.
Перед университетами со всего мира стоит задача спроектировать и построить одноместный гоночный автомобиль, чтобы участвовать в статических и динамических соревнованиях, демонстрирующих их понимание и проверяющих характеристики автомобиля.
В дополнение к техническим навыкам студенты приобретают навыки управления, маркетинга и работы с людьми, что так важно во всех сферах занятости.
Поощряя команды быть инновационными и работать как над техническими, так и над бизнес-аспектами проекта, Formula Student предоставляет студентам со всего мира идеальную возможность освоить новые навыки и продемонстрировать свой талант.
ФОРМУЛА СТУДЕНТ ЭТО:
- Высокоэффективный инженерный проект, который чрезвычайно ценится университетами и обычно является частью их степени
- В индустрии автоспорта считается стандартом для выпускников инженерных специальностей, что позволяет им переходить из университета на работу
- Воздушный змей для реального инженерного опыта
Будучи студентом, участвуя в Formula Student, вы получаете возможность продемонстрировать свои технические, инженерно-конструкторские и производственные навыки. Вы также получите важные уроки по работе в команде, тайм-менеджменту, управлению проектами, составлению бюджета и презентации: всему, что будет искать любой потенциальный работодатель.
Вы также получите важные уроки по работе в команде, тайм-менеджменту, управлению проектами, составлению бюджета и презентации: всему, что будет искать любой потенциальный работодатель.
Formula Student также считают, что профессионализм, который они приобретают в качестве практикующих инженеров, означает, что они хорошо подготовлены к будущей инженерной карьере.
Посетите веб-сайт студенческой гоночной команды Формулы Абердина (TAU Racing) для получения более подробной информации.
Формула Студент | Университет Сандерленда
В основе нашего проекта лежат увлеченные люди, и мы можем похвастаться командой целеустремленных и уникальных людей, которые являются экспертами в своих областях, из разных областей и областей.Среди них студенты из автомобильной и машиностроительной промышленности, бизнеса, СМИ, спорта и журналистики, а предыдущие члены команды изучали курсы фармацевтики и медсестер.
Выйти на трассу — наша главная цель и огромное достижение каждый год, и тот факт, что соревнования проводятся в таком престижном месте, как Сильверстоун, просто невероятен. Для многих из нас это первый шанс принять непосредственное участие в крупном автоспортивном событии такого масштаба.
Для многих из нас это первый шанс принять непосредственное участие в крупном автоспортивном событии такого масштаба.
История гонок SUN
Гоночная команда Университета Сандерленда, SU Racing, была сформирована в 2003 году, но в то время ограничивалась проектированием и разработкой.Только в 2004 году родился первый автомобиль Сандерленда — SU04.
Этот автомобиль был спроектирован с нуля и собран небольшой командой из пяти студентов всего за три месяца. Это был один из самых тяжелых и больших автомобилей на гонках Formula Student 2004 года, он работал на опорных колесах и шинах прямо от Nissan Micra.
Большая часть трансмиссии была взята от той же Micra, и все они располагались внутри собственного шасси коробчатого сечения из газовой сварки, оснащенного очень темпераментным рядным двухцилиндровым двигателем Kawasaki GPZ 500.
Несмотря на то, что этот автомобиль был очень большим и очень тяжелым, он был построен в короткие сроки и попал в Формулу Студент. Это проложило путь к будущему SUN Racing в автоспорте и регулярным выступлениям в Сильверстоуне с началом производства нестандартных компонентов.
Это проложило путь к будущему SUN Racing в автоспорте и регулярным выступлениям в Сильверстоуне с началом производства нестандартных компонентов.
Например, модель 2009 года отличалась драматическим стилем Cooper/Lotus 1950-х годов и оснащалась рядным двигателем Honda CBR 600 FY с четырьмя двойными распредвалами. Это был первый автомобиль SUN Racing с четырехцилиндровым двигателем и системой впрыска топлива.Многие, в том числе большое количество официальных лиц Сильверстоуна, считали автомобиль одним из самых стильных автомобилей на мероприятии 2009 года.
Принять участие
Поскольку наши автомобили развиваются каждый год на основе извлеченных уроков и передовой современной практики, мы всегда стремимся улучшить перспективы и усовершенствовать навыки нашей команды, что, мы надеемся, сделает нас сильнее и успешнее с каждым годом.
При поддержке Университета Сандерленда и Института передовой автомобильной и производственной практики (AMAP) у нас впереди очень светлое будущее.
Если вы хотите присоединиться к нам и действительно изменить ситуацию, или если вы просто заинтересованы в соревнованиях Formula Student и хотели бы получать регулярные обновления о SUN Racing и о том, чем мы занимаемся, пожалуйста, свяжитесь с нами или приходите и встретиться с нами и посмотреть, что мы делаем.
Formula Student with Team e-gnition
Formula Student — ежегодное студенческое инженерное соревнование. Студенческие команды со всего мира проектируют, строят, тестируют и участвуют в гонках на небольших гоночных болидах.Автомобили оцениваются по ряду критериев. Он находится в ведении Института инженеров-механиков. Команда Formula Student Team e-gnition Hamburg спонсировалась компанией Xsens в сезоне 2016/2017. MTi-G-710 устанавливается на автомобиль для получения высокоточных данных датчиков во время гонки. Измеренные данные используются для различных приложений в автомобиле.
Гоночный автомобиль Formula Student имеет мощность более 100 л. с. и весит 200 кг. Чтобы вывести мощность на трассу, необходимо контролировать пробуксовку четырех колес.Поскольку у автомобиля e-gnition Hamburg на каждом колесе по одному двигателю, приложению требуется абсолютная скорость автомобиля. В то время как обычный приемник GNSS должен снижать скорость передачи данных, Xsens IMU обеспечивает хорошую оценку скорости каждые несколько миллисекунд.
с. и весит 200 кг. Чтобы вывести мощность на трассу, необходимо контролировать пробуксовку четырех колес.Поскольку у автомобиля e-gnition Hamburg на каждом колесе по одному двигателю, приложению требуется абсолютная скорость автомобиля. В то время как обычный приемник GNSS должен снижать скорость передачи данных, Xsens IMU обеспечивает хорошую оценку скорости каждые несколько миллисекунд.
Векторизация крутящего момента
Концепция привода на четыре колеса позволяет регулировать крутящий момент каждого отдельного колеса. Хорошая векторизация крутящего момента делает возможной высокую скорость на поворотах, но для этого также требуется хороший контроллер, а также хорошие, точные и высокочастотные данные датчика.Этот контроллер Torque Vectoring использует данные инерциального датчика предоставленного MTi-G-710.
Испытание IMU собственной разработки
Как студенческая команда Формулы, вы хотите иметь как можно больше знаний, чтобы понимать все об автомобиле. Это необходимо для статических дисциплин во время соревнований и для хорошей эволюции от сезона к сезону. Поэтому мы решили разработать и настроить собственный IMU. Но это невозможно без проверки. Xsens MTi-G-710 используется в качестве эталона при разработке IMU собственной разработки.
Это необходимо для статических дисциплин во время соревнований и для хорошей эволюции от сезона к сезону. Поэтому мы решили разработать и настроить собственный IMU. Но это невозможно без проверки. Xsens MTi-G-710 используется в качестве эталона при разработке IMU собственной разработки.
Оценка механических компонентов
При тестировании гоночного автомобиля необходимо найти хорошую настройку всех аэродинамических и подвесочных устройств. Чтобы оценить различные настройки, механики просматривают данные датчика после каждого сеанса тестирования и во время тестирования различных механических компонентов. Нужна хорошая настройка автомобиля, чтобы хорошо выступать в динамических дисциплинах на соревнованиях.
Выбор продукта
Хотите узнать, какая инерциальная единица измерения подходит для вашего приложения? Воспользуйтесь нашим инструментом рекомендаций и узнайте, какой MTi вам нужен, ответив всего на 3 вопроса.
Формула Студент
Формула Студент Этот веб-сайт использует функциональные и отслеживающие файлы cookie. Функциональные файлы cookie необходимы для обеспечения основных функций сайта, таких как запоминание состояния входа в систему, в то время как отслеживающие файлы cookie позволяют нам улучшить ваш опыт, персонализировать контент и рекламу, а также предоставить информацию о том, как используется сайт. Пожалуйста, ознакомьтесь с нашей Политикой использования файлов cookie, чтобы узнать об этих файлах cookie.Также ознакомьтесь с нашим Уведомлением о конфиденциальности и Условиями использования, чтобы лучше понять, как мы поддерживаем наш сайт, а также собираем и используем данные посетителей. Нажимая «Принять», вы соглашаетесь на сохранение на вашем устройстве функциональных файлов cookie и файлов cookie для отслеживания, как описано в нашей Политике использования файлов cookie. В любое время вы можете изменить настройки файлов cookie для отслеживания в настройках вашего браузера и здесь
Функциональные файлы cookie необходимы для обеспечения основных функций сайта, таких как запоминание состояния входа в систему, в то время как отслеживающие файлы cookie позволяют нам улучшить ваш опыт, персонализировать контент и рекламу, а также предоставить информацию о том, как используется сайт. Пожалуйста, ознакомьтесь с нашей Политикой использования файлов cookie, чтобы узнать об этих файлах cookie.Также ознакомьтесь с нашим Уведомлением о конфиденциальности и Условиями использования, чтобы лучше понять, как мы поддерживаем наш сайт, а также собираем и используем данные посетителей. Нажимая «Принять», вы соглашаетесь на сохранение на вашем устройстве функциональных файлов cookie и файлов cookie для отслеживания, как описано в нашей Политике использования файлов cookie. В любое время вы можете изменить настройки файлов cookie для отслеживания в настройках вашего браузера и здесь
Принимать файлы cookie Отклонить файлы cookie
Вы собираетесь покинуть этот сайт
Axalta не несет ответственности за контент, который вы собираетесь просмотреть
Formula Student — международный конкурс инженеров-конструкторов, впервые проводимый Обществом автомобильных инженеров в 1979 году. Цель состоит в том, чтобы разработать и предоставить студентам-инженерам платформу для опыта, создания и обучения. Он предлагает уникальный способ проверить теоретические знания студентов в практическом контексте. Студенты приобретают и развивают такие навыки, как проектирование, управление проектами и работа в команде. Соревнования Formula Student превратились в международные соревнования, в которых участвуют представители более 20 стран и более 600 университетов.*
Цель состоит в том, чтобы разработать и предоставить студентам-инженерам платформу для опыта, создания и обучения. Он предлагает уникальный способ проверить теоретические знания студентов в практическом контексте. Студенты приобретают и развивают такие навыки, как проектирование, управление проектами и работа в команде. Соревнования Formula Student превратились в международные соревнования, в которых участвуют представители более 20 стран и более 600 университетов.*
Axalta стремится поощрять и развивать активное участие в предметах науки, технологий, инженерии и математики (STEM) в рамках программы «Светлое будущее Axalta».В дополнение к поставке красок, Axalta предлагает теоретические и практические консультации по подготовке, техническую поддержку и способствует обучению, чтобы помочь команде получить максимальную отдачу от используемых продуктов.
*Источник: https://www.global-formula-racing.com/en/formula-student
Команда Agoria Solar, Университет Лёвена, Бельгия – Bridgestone World Solar Challenge
Cromax поддерживает команду Agoria Solar Team — действующих чемпионов мира в классе Challenger — из Университета Левена, Бельгия, в этой дисциплине с 2015 года.
Академическая ассоциация автоспорта Цюриха (AMZ), ETH Zurich, Швейцария – Formula Student
Axalta вместе со своим брендом красок премиум-класса Cromax поддерживает студенческую гоночную команду Швейцарской академической ассоциации автоспорта в Цюрихе (AMZ) ETH Zurich с 2018 года. Успешная команда AMZ Racing участвует в серии eRacing Formula Student и фокусируется на разработке прототипы гоночных автомобилей с электроприводом.
Вольфаст Униови, Университет Овьедо, Испания – MotoStudent
Axalta сотрудничает с командой инженеров университета с 2014 года, принимая участие в международном соревновании MotoStudent International Competition — глобальном мотоциклетном состязании между университетскими студенческими командами.
В 2020 году Wolfast Uniovi впервые вошел в категорию MotoStudent Electric. Команда находится в процессе проектирования, разработки и производства прототипа мотоцикла со 100% электрической силовой установкой.
Formula Student Германия — Программное обеспечение для моделирования
Formula Student Германия — Программное обеспечение для моделирования | SimScaleЗаполните форму для скачивания
Formula Student Germany — это ведущее гоночное соревнование, в котором студенческие команды со всего мира соревнуются друг с другом в серии статических и динамических соревнований на самодельных гоночных автомобилях в стиле формулы.Пятидневное соревнование проходит на Хоккенхаймринге, где команды доводят свои машины и себя до предела на знаменитой гоночной трассе. Соревнования Formula Student Germany 2017 проходили на Хоккенхаймринге с 8 по 13 июля 2017 года.
Онлайн-семинар | Применение CFD в Formula Student
Во время этого онлайн-семинара, состоящего из 4 сессий, студенты получат практическое интерактивное введение в основы аэродинамики гоночных автомобилей и CFD от ведущих экспертов по аэродинамике автоспорта.Завершение курса позволит участникам создавать точные CFD-симуляции конструкции своего автомобиля и совершенствовать свою собственную методологию CFD.
Учащиеся, посетившие занятия и выполнившие все четыре домашних задания, получат Сертификат об окончании SimScale, который можно добавить в резюме или профиль курса на Linkedin.
Ведущие и приглашенные докладчики этого курса
- Торбьорн Ларссон, бывший руководитель отдела CFD в Sauber, BMW и Ferrari
- Рене Хилхорст, бывший руководитель отдела аэродинамики Toyota Motorsport
- Никлас Пфайффер, руководитель отдела аэродинамики eMotorsports Cologne Formula Student Team
- Милад Мафи, руководитель академической программы SimScale
Станьте спонсируемой командой SimScale
Поднимите свои проекты на новый уровень с помощью мощного программного обеспечения для инженерного моделирования для CFD, FEA и теплового анализа. SimScale предоставляет облачное программное обеспечение для инженерного моделирования для университетских команд, участвующих в Formula Student UK. Вы можете подать заявку на участие в спонсируемой команде SimScale со следующими преимуществами:
SimScale предоставляет облачное программное обеспечение для инженерного моделирования для университетских команд, участвующих в Formula Student UK. Вы можете подать заявку на участие в спонсируемой команде SimScale со следующими преимуществами:
- Единая командная учетная запись
- Доступ к неограниченному количеству основных часов и частным проектам
- Поддержка Premium SimScale через чат
Дополнительные ресурсы
Логотип SimScale
Получите доступ к активам нашего бренда, включая векторные логотипы SimScale, цвета и инструкции по использованию бренда.
Оптимизация дизайна Formula SAE
В ходе этого вебинара мы покажем вам, как сетевая платформа SimScale для моделирования конечных элементов и CFD может использоваться командами Formula SAE для проектирования своих гоночных автомобилей в стиле Formula.
Лучшее программное обеспечение для студентов
С начала 1980-х годов конкурс Formula SAE (также известный как «Formula Student») стал идеальным дополнением к учебной программе инженерного колледжа, ориентированной на аудиторию.
Политика в отношении файлов cookie
SimScale использует файлы cookie для улучшения вашего пользовательского опыта. Используя этот веб-сайт, вы соглашаетесь с нашей политикой использования файлов cookie.
Закрыть настройки файлов cookie GDPR Обзор конфиденциальностиЭтот веб-сайт использует файлы cookie, чтобы мы могли предоставить вам наилучший пользовательский интерфейс.Информация о файлах cookie хранится в вашем браузере и выполняет такие функции, как распознавание вас, когда вы возвращаетесь на наш веб-сайт, и помогает нашей команде понять, какие разделы веб-сайта вы находите наиболее интересными и полезными.
Строго необходимые файлы cookie Строго необходимые файлы cookie должны быть включены постоянно, чтобы мы могли сохранить ваши предпочтения для настроек файлов cookie.