
Статистическое наблюдение сплошное: Сплошное статистическое наблюдение малого и среднего бизнеса за 2020 год
2. Виды и способы статистического наблюдения. Общая теория статистики: конспект лекции
2. Виды и способы статистического наблюдения
Статистическое наблюдение представляет собой процесс, который с точки зрения его организации может иметь разнообразные способы, формы и виды проведения. Задачей общей теории статистики является определение сущности способов, форм и видов наблюдения для решения вопроса, где, когда и какие приемы наблюдения будут применяться.
Статистические наблюдения имеют две основные группы:
1) охват единиц совокупности;
2) время регистрации фактов.
По уровню охвата исследуемой совокупности статистическое наблюдение делится на два типа: сплошное и несплошное.
Под сплошным (полным) наблюдением понимается охват всех единиц изучаемой совокупности. Сплошное наблюдение обеспечивает полноту информации об изучаемых явлениях и процессах. Данный тип наблюдения связан с большими затратами трудовых и материальных ресурсов. Для сбора и обработки всего объема необходимой информации требуется значительное время, поэтому потребность в оперативной информации не удовлетворяется.
Под несплошным наблюдением понимается только охват определенной части изучаемой совокупности. Проводя несплошное наблюдение, необходимо заблаговременно определить, какая именно часть исследуемой совокупности будет подвергнута наблюдению и какой критерий будет положен в основу выборки. Преимущество организации несплошного наблюдения состоит в том, что оно проводится в короткие сроки, связано с наименьшими трудовыми и материальными затратами, полученная информация носит оперативный характер.
Существует несколько видов несплошного наблюдения: выборочное; наблюдение основного массива; монографическое.
Под выборочным наблюдением понимается часть единиц исследуемой совокупности, выделенной способом случайного отбора. При правильной организации выборочное наблюдение выдает довольно точные результаты, которые можно распространить с обусловленной вероятностью на всю совокупность. Методом моментных наблюдений называется выборочное наблюдение, которое предполагает отбор не только единиц исследуемой совокупности (выборку в пространстве), но и моментов времени, в которые проводится регистрация признаков (выборка во времени).
Методом моментных наблюдений называется выборочное наблюдение, которое предполагает отбор не только единиц исследуемой совокупности (выборку в пространстве), но и моментов времени, в которые проводится регистрация признаков (выборка во времени).
Наблюдение основного массива представляет собой охват обследования определенных, наиболее значимых признаков единиц совокупности. При таком наблюдении в учет берутся самые большие единицы совокупности, а регистрируются самые существенные для данного исследования признаки. Например, обследуется 15-20% крупных кредитных учреждений, при этом регистрируется содержание их инвестиционных портфелей.
Для монографического наблюдения характерно всестороннее и полное изучение лишь некоторых единиц совокупности, обладающих какими-либо особенными характеристиками или представляющими какое-либо новое явление. Целью такого наблюдения является выявление имеющихся или только появляющихся тенденций в развитии данного процесса или явления. При монографическом обследовании отдельные единицы совокупности подвергаются подробному изучению, которое позволяет отметить очень важные зависимости и пропорции, которые не обнаружи-мы при других, не столь подробных наблюдениях.
По времени регистрации фактов наблюдение может быть непрерывным и прерывным. Прерывное наблюдение, в свою очередь, включает периодическое и единовременное.
Непрерывное (текущее) наблюдение реализовывается путем непрерывной регистрации фактов по мере их поступления. При таком наблюдении прослеживаются все изменения исследуемых процессов и явлений, что позволяет следить за его динамикой.
Прерывное наблюдение проводится либо систематически, через установленные промежутки времени(периодическое наблюдение), либо однократно и нерегулярно по мере необходимости единовременное наблюдение). В основу периодических наблюдений обычно заложены аналогичная программа и инструментарий, с тем чтобы результаты таких исследований могли быть сопоставимы. Примерами периодического наблюдения могут быть перепись населения, проводимая через довольно длительные интервалы времени, и все формы статистических наблюдений, которые носят годовой, полугодовой, квартальный, ежемесячный характер.
Специфика единовременного наблюдения заключается в том, что факты регистрируются не в связи с их возникновением, а по состоянию или наличию их на определенный момент или за период времени. Количественное измерение признаков какого-либо явления или процесса происходит в момент проведения обследования, а повторная регистрация признаков может не производиться вообще или сроки ее проведения заранее не определены. Примером единовременного наблюдения может служить единовременное обследование состояния жилищного строительства, которое проводилось в 2000 г.
Примером единовременного наблюдения может служить единовременное обследование состояния жилищного строительства, которое проводилось в 2000 г.
Наряду с видами статистического наблюдения в общей теории статистики рассматриваются способы получения статистической информации, важнейшими из которых являются документальный способ наблюдения; способ непосредственного наблюдения; опрос.
Документальное наблюдение основано на использовании в качестве источника информации данных различных документов, например регистров бухгалтерского учета. Учитывая, что к заполнению таких документов, как правило, предъявляются высокие требования, данные, отраженные в них, носят наиболее достоверный характер и могут служить качественным исходным материалом для проведения анализа.
Непосредственное наблюдение осуществляется путем регистрации фактов, лично установленных регистраторами в результате осмотра, измерения, подсчета признаков изучаемого явления. Таким способом регистрируются цены на товары и услуги, производятся замеры рабочего времени, инвентаризация остатков на складе и т. д.
д.
Опрос основывается на получении данных от респондентов (участников опроса). Опрос применяют в тех случаях, когда наблюдение другими способами не может быть осуществлено. Такой вид наблюдения характерен для проведения различных социологических обследований и опросов общественного мнения.
Статистическая информация может быть получена разными видами опросов: экспедиционным; корреспондентским; анкетным; явочным.
Экспедиционный (устный) опрос проводится специально подготовленными работниками (регистраторами), которые фиксируют ответы респондентов в формулярах наблюдения. Формуляр представляет собой бланк документа, в котором необходимо заполнить поля для ответов.
Корреспондентский способ предполагает, что на добровольной основе штат респондентов сообщает сведения непосредственно в орган, ведущий наблюдение. Недостатком этого способа является то, что затруднительно проверить правильность полученной информации.
При анкетном способе респонденты заполняют анкеты (вопросники) добровольно и преимущественно анонимно. Поскольку этот способ получения информации не является надежным, его применяют в тех исследованиях, где не требуется высокая точность результатов. В некоторых ситуациях достаточно приближенных результатов, которые улавливают лишь тенденцию и фиксируют появление новых фактов и явлений.
Поскольку этот способ получения информации не является надежным, его применяют в тех исследованиях, где не требуется высокая точность результатов. В некоторых ситуациях достаточно приближенных результатов, которые улавливают лишь тенденцию и фиксируют появление новых фактов и явлений.
Явочный способ предполагает представление сведений в органы, ведущие наблюдение, в явочном порядке. Таким способом регистрируются акты гражданского состояния – браки, разводы, смерти, рождения и т. д.
Кроме видов и способов статистического наблюдения, в теории статистики рассматриваются и формы статистического наблюдения: отчетность; специально организованное статистическое наблюдение; регистры.
Статистическая отчетность – основная форма статистического наблюдения, которая характеризуется тем, что сведения об изучаемых явлениях статистические органы получают в виде особых документов, представляемых предприятиями и организациями в определенные сроки и по установленной форме. Сами формы статистической отчетности, методы сбора и обработки статистических данных, методология статистических показателей, установленные Госкомстатом России, являются официальными статистическими стандартами Российской Федерации и обязательны для всех субъектов общественных отношений.
Сами формы статистической отчетности, методы сбора и обработки статистических данных, методология статистических показателей, установленные Госкомстатом России, являются официальными статистическими стандартами Российской Федерации и обязательны для всех субъектов общественных отношений.
Статистическую отчетность делят на специализированную и типовую. Состав показателей типовой отчетности един для всех предприятий и организаций, в то время как состав показателей специализированной отчетности зависит от специфики отдельных отраслей экономики и сферы деятельности.
По срокам представления статистическая отчетность бывает ежедневная, недельная, декадная, двухнедельная, месячная, квартальная, полугодовая и годовая.
Статистическая отчетность может передаваться по телефону, по каналам связи, на электронных носителях с обязательным последующим представлением на бумажных носителях, скрепленная подписью ответственных лиц.
Специально организованное статистическое наблюдение представляет собой сбор сведений, организуемый статистическими органами, или для изучения явлений, не охватываемых отчетностью, или для более глубокого изучения отчетных данных, их проверки и уточнения. Различного рода переписи, единовременные обследования являются специально организованными наблюдениями.
Различного рода переписи, единовременные обследования являются специально организованными наблюдениями.
Регистры – это такая форма наблюдения, при которой факты состояния отдельных единиц совокупности непрерывно регистрируются. Наблюдая за единицей совокупности, предполагают, что процессы, там происходящие, имеют начало, долговременное продолжение и конец. В регистре каждая единица наблюдения характеризуется совокупностью показателей. Все показатели хранятся до тех пор, пока единица наблюдения находится в регистре и не закончила своего существования. Некоторые показатели остаются неизменными все время, пока единица наблюдения находится в регистре, другие могут меняться время от времени. Примером такого регистра может служить единый государственный регистр предприятий и организаций (ЕГРПО). Все работы по его ведению осуществляет Госкомстат России.
Итак, выбор видов, способов и форм статистического наблюдения зависит от целого ряда факторов, основными из которых являются цели и задачи наблюдения, специфика наблюдаемого объекта, срочность представления результатов, наличие подготовленных кадров, возможность применения технических средств сбора и обработки данных.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесРосстат проведёт сплошное наблюдение малого и среднего бизнеса
Сплошное наблюдение – общенациональный проект, на протяжении которого собирается статистика по представителям малого и среднего бизнеса. Раз в пять лет все индивидуальные предприниматели, а также малый и микробизнес в обязательном порядке сдают отчётность в Росстат.
В последний раз под сплошное наблюдение малый бизнес попадал в 2016 году, подавая документы за 2015 год, а это значит, что следующий срез будет уже в 2021 году.
С помощью таких сплошных срезов служба статистики получает данные об основных показателях малого бизнеса: расходы и выручка, адрес, состав средств, количество работников и другое.
На основании данных сплошного наблюдения правительство разрабатывает меры поддержки малого бизнеса. Поэтому при сплошном наблюдении сдавать отчётность в Росстат нужно всем без исключений.
Росстат гарантирует конфиденциальность предоставленной информации. Все сведения будут использоваться в обезличенном виде.
Субъекты малого предпринимательства обязаны представить:
— № МП-сп «Сведения об основных показателях деятельности малого предприятия
за 2020 год»;
— № 1-предприниматель «Сведения о деятельности индивидуального предпринимателя за 2020 год»
Посмотреть, относится ли ваша компания к субъектам МСП, можно здесь.
Информация Росстата о проведении сплошного статистического наблюдения – здесь.
Сдавать статотчётность в «электронке» придётся всем
В Госдуму внесён законопроект
об обязательной сдаче статистической отчётности в электронном виде всеми юрлицами и индивидуальными предпринимателями.
Есть решение
Клиенты Такскома могут перейти на тариф, в котором есть Росстат. Или просто подключить обмен с Росстатом в своём тарифе. Это можно сделать просто и удалённо –
в личном кабинете
Нормативно-правовые и организационные документы:
— Федеральный закон от 24.07.2007 № 209-ФЗ (ред. от 08.06.2020) «О развитии малого и среднего предпринимательства в Российской Федерации»;
— Приказ Росстата от 28.08.2020 № 496 «Об утверждении Основных методологических и организационных положений по сплошному федеральному статистическому наблюдению за деятельностью субъектов малого и среднего предпринимательства за 2020 год»;
— Приказ Росстата от 17.08.2020 № 469
«Об утверждении форм федерального статистического наблюдения и указаний по их заполнению для организации сплошного федерального статистического наблюдения за деятельностью субъектов малого и среднего предпринимательства в 2021 году по итогам за 2020 год».
Отправить
Запинить
Твитнуть
Поделиться
Поделиться
Сплошное статистическое наблюдение малого и среднего бизнеса — Администрация Курманаевского района
Главная / Информация / Сплошное статистическое наблюдение малого и среднего бизнеса
Территориальный орган Федеральной службы государственной статистики по Оренбургской области напоминает, что в 2021 году Росстат проводит экономическую перепись малого бизнеса. В течении 1 квартала 2021 года респондентам необходимо заполнить анкету в электронном или бумажном виде и отправить в Оренбургстат.экономическую перепись малого бизнеса.
В течении 1 квартала 2021 года респондентам необходимо заполнить анкету в электронном или бумажном виде и отправить в Оренбургстат.
В ознакомительных целях на сайте Оренбургстата размещены примеры по заполнению форм сплошного наблюдения №№ МП-сп, 1-предприниматель и перечень кодов ОКВЭД2, относящихся к платным услугам населению, размещенные на сайте Оренбургстата в разделе Сплошное статистическое наблюдение за деятельностью малого и среднего бизнеса за 2020 год (http://orenstat.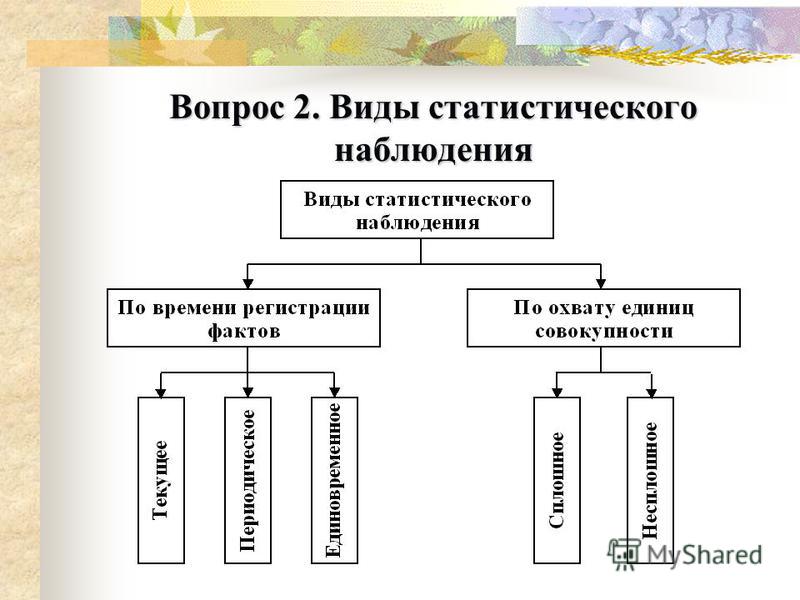 gks.ru/ вкладка Переписи и обследования/Сплошное статистическое наблюдение малого и среднего бизнеса за 2020 год/Формы отчетности и указания по их заполнению). Экономическая перепись малого бизнеса проводится 1 раз в пять лет и в соответствии с законодательством Российской Федерации участие в ней является обязательным.
gks.ru/ вкладка Переписи и обследования/Сплошное статистическое наблюдение малого и среднего бизнеса за 2020 год/Формы отчетности и указания по их заполнению). Экономическая перепись малого бизнеса проводится 1 раз в пять лет и в соответствии с законодательством Российской Федерации участие в ней является обязательным.
03.03.2021 Что: перепись малого бизнеса онлайн. Где: на портале «Госуслуги». Когда: до 1 мая 2021 года.
25.02.2021 Экономическая перепись
22.01.2021 Оренбургстат приступил к сбору данных по сплошному статистическому наблюдению за деятельностью малого и среднего бизнеса за 2020 год
25.12.2020 Оренбургстат актуализирует списки респондентов
25.12.2020 Началась подготовка к сплошному федеральному статистическому наблюдению за деятельностью субъектов малого и среднего предпринимательства
Росстат приглашает малый бизнес принять участие в экономической переписи
Обращение к руководителям
На площадке ТПП Восточной Сибири прошел вебинар Иркутскстата
Территориальный орган Федеральной службы государственной статистики по Иркутской области провел вебинар для членов ТПП Восточной Сибири. В мероприятии приняли более 70 человек. Специалисты Иркутскстата рассказали о проведении сплошного федерального статистического наблюдения за деятельностью субъектов МСП в 2021 году.
Начальник отдела статистики предприятий Наталья Васильева напомнила, что в первом полугодии 2021 года во всех субъектах страны проходит экономическая перепись малого бизнеса. Сплошное статистическое наблюдение за деятельностью субъектов МСП проводится один раз в пять лет. В соответствии с законодательством РФ, участие в нем является обязательным для малого и среднего бизнеса. По словам Натальи Васильевой, цель экономической переписи заключается в формировании объективной картины реального состояния малого бизнеса в России с целью выработки мер дополнительной поддержки субъектам МСП и повышения эффективности функционирования российской экономики в целом. По итогам сплошного наблюдения государство скорректирует положения профильного национального проекта «Малое и среднее предпринимательство и поддержка индивидуальной предпринимательской инициативы», а также обеспечит возможность получения статистической информации о состоянии МСП на местах – в муниципальных образованиях.
Специалист-эксперт отдела статистики предприятий Елена Сороковикова разъяснила предпринимателям процедуру статистического наблюдения. Она рассказала, что представлять отчеты в рамках сплошного наблюдения обязаны организации и ИП, являющиеся средними, малыми и микропредприятиями. Кроме того, обязанность по представлению первичной статистической информации распространяется на потребительские кооперативы, глав крестьянских (фермерских) хозяйств, самозанятых и хозяйственные партнерства. Утвержденные Росстатом формы доступны для заполнения на портале Госуслуг, через систему WEB-СБОРА Росстата и через специальных операторов связи, предоставляющих услуги защищенного электронного документооборота. Формы могут быть заполнены предпринимателями самостоятельно и предоставлены в Иркутскстат на бумажном носителе (для малых и микропредприятий), либо направлены на официальный адрес электронной почты ведомства. Крайний срок представления сведений — 1 апреля 2021 года.
Предварительные итоги сплошного наблюдения опубликуют в декабре 2021 года, а окончательные — в июне 2022 года.
По вопросам участия в обучающих мероприятиях палаты обращайтесь в Учебный центр ТПП ВС по тел. (3952) 20-21-76, эл. почта: [email protected].
Налоговая служба Хабаровского края оказывает содействие в проведении сплошного наблюдения за деятельностью малого и среднего предпринимательства | ФНС России
Дата публикации: 20.01.2021 07:55
Руководитель краевого налогового управления Сергей Ефремов вошел в состав рабочей группы по оказанию содействия в проведении сплошного федерального статистического наблюдения за деятельностью субъектов малого и среднего предпринимательства (МСП) в Хабаровском крае в I квартале 2021 года.
Сплошное статистическое наблюдение проводится Рсстатом в целях комплексной и детализированной характеристики экономической деятельности малого и среднего бизнеса на основе собранных сведений о производстве товаров, работ и услуг, уровне занятости, величине зарплат и финансовых результатов деятельности средних и малых предприятий как в отдельно взятых регионах, так и в целом по всей России.
Сбор статистических данных в рамках сплошного наблюдения проходит путем представления организациями и ИП, отнесенными к субъектам МСП, статистических отчетов об основных показателях и результатах своей деятельности.
Для налоговых органов собранные сведения представляют особую важность, т.к. используются сотрудниками службы в анализе налогового потенциала, выработке стратегических решений для построения эффективного взаимодействия службы с налогоплательщиками по различным направлениям деятельности, а также оказания необходимой поддержки субъектам МСП в крае.
Полученные в результате сплошного наблюдения сведения позволят, в частности, скорректировать краевые проекты, направленные на поддержку малого и среднего бизнеса, и, в конечном итоге, будут способствовать повышению эффективности функционирования экономики в регионе.
В целях получения максимально достоверных сведений в ходе сплошного наблюдения рекомендуем представителям малого и среднего бизнеса Хабаровского края обязательно принять участие в мероприятии.
Более подробная информация о проведении сплошного федерального статистического наблюдения за деятельностью субъектов малого и среднего предпринимательства размещена на сайте Федеральной службы государственной статистики.Сплошное федеральное статистическое наблюдение | Администрация Прокопьевского муниципального округа
ВНИМАНИЕ индивидуальные предприниматели и руководители малых (включая микро) предприятий!
В соответствии с Федеральным законом от 24.07.2007г. 209-ФЗ «О развитии малого и среднего предпринимательства в Российской Федерации» Федеральная служба государственной статистики в 2016 году проводит Сплошное федеральное статистическое наблюдение за деятельностью субъектов малого и среднего предпринимательства по итогам 2015 года.
Сплошному наблюдению подлежат все малые и микропредприятия (коммерческие организации), а также индивидуальные предприниматели.
Кемеровостат напоминает, срок сдачи форм сплошного статистического обследования субъектов малого предпринимательства № 1-предприниматель «Сведения о деятельности индивидуального предпринимателя за 2015г.» и № МП-сп «Сведения об основных показателях деятельности малого предприятия за 2015г».
ИСТЕКАЕТ 1 АПРЕЛЯ 2016 г.
Не получившим статистический инструментарий, необходимо обратиться в органы государственной статистики своего города (района).
В соответствии с Федеральными законами от 24.07.2007 г. № 209-ФЗ «О развитии малого и среднего предпринимательства в Российской Федерации», (статья 5) и от 29.11.2007 № 282-ФЗ «Об официальном статистическом учете и системе государственной статистики в Российской Федерации» (статья 8):
Ваше участие в обследовании является обязательным.
Нарушение порядка представления статистической информации, влечет ответственность, установленную статьей 13.19 Кодекса Российской Федерации «Об административных правонарушениях» от 30.12.2001 №195-ФЗ.
Кемеровостат гарантирует конфиденциальность полученных данных!
www.kemerovostat.gks.ru.
Email:[email protected]
понятие, виды и методы (стр. 1 из 2)
Введение
Успех дела сбора качественных и полных исходных данных с учетом требования экономного расходования материальных, трудовых и финансовых ресурсов во многом определяется решением вопроса о выборе вида, способа и организационной формы статистического наблюдения.
Статистика имеет многовековую историю. Её возникновение и развитие обусловлены общественными потребностями: подсчет населения, скота, учета земельных угодий, имущества и т.д. Наиболее ранние сведения о таких работах в Китае относятся к 13 в. до нашей эры. В Древнем Риме проводились учеты свободных граждан и их имущества.
История развития статистики показывает, что статистическая наука сложилась в результате теоретического обобщения накопленного человечеством передового опыта учетно-статистических работ, обусловленных, прежде всего, потребностями управления жизни общества.
В статистической практике применяются различные виды несплошного наблюдения: выборочное, способ основного массива, анкетное и монографическое. Качество несплошного наблюдения уступает результатам сплошного, однако вполне очевидны и некоторые преимущества первого: выигрыш во времени для принятия оперативного решения, а также соблюдение режима экономии ресурсов. В ряде случаев статистическое наблюдение вообще оказывается возможным только как несплошное. Оно используется для получения представительной характеристики всей совокупности по некоторой части ее единиц применяют выборочное наблюдение. В промышленности выборочное наблюдение применяется при статистическом контроле качества продукции, изучении использования производственного оборудования, рабочего места станочников и т.д.
1. Виды статистического наблюдения
Необходимость выбора того или иного варианта сбора статистических данных, в наибольшей мере соответствующего условиям решаемой задачи, определяется наличием нескольких видов наблюдения, различающихся прежде всего по признаку характера учета фактов во времени.
Систематическое наблюдение, осуществляемое непрерывно и обязательно по мере возникновения признаков явления, называется текущим.
Текущее наблюдение проводится на основе первичных документов, содержащих информацию, необходимую для достаточно полной характеристики изучаемого явления.
Статистическое наблюдение, проводимое через некоторые равные промежутки времени, называется периодическим. Примером может служить перепись населения.
Наблюдение, проводимое время от времени, без соблюдения строгой периодичности либо в разовом порядке, называется единовременным.
Виды статистического наблюдения дифференцируются с учетом различия информации по признаку полноты охвата совокупности. В связи с этим различают сплошное и несплошное наблюдения. Сплошным называют наблюдение, учитывающее все без исключения единицы изучаемой совокупности. Организация сплошного наблюдения не всегда возможна и целесообразна, особенно для контроля за качеством продукции. В этом случае сплошное наблюдение приводит к исключению из сферы практического использования массы продукции предприятий. Поэтому необходимо осуществлять несплошное (частичное) наблюдение учитывать только часть единиц совокупности, по которой составляют представление о характерных особенностях изучаемого явления в целом.
Несплошное наблюдение имеет определенные преимущества по сравнению со сплошным наблюдением:
1) требуется значительно меньше расходов труда и средств связи с уменьшением числа обследуемых единиц;
2) данные могут быть собраны в более короткие сроки и по более широкой программе, чтобы в заданных пределах всесторонне раскрыть особенности изучаемой совокупности, провести более глубокое научное исследование;
3) данные несплошного наблюдения привлекаются для контроля материалов сплошного наблюдения;
4) несплошное наблюдение должно быть репрезентативным (представительным).
Обследуемые единицы отбираются так, чтобы, опираясь на полученные по этим единицам данные, составить правильное представление о явлении в целом.
Поэтому одной из существенных особенностей несплошного наблюдения является организация отбора единиц обследуемой совокупности способами: основного массива, монографическим, анкетным и выборочным наблюдением.
Способ основного массива предусматривает отбор единиц совокупности, преобладающих по изучаемому признаку. Данный способ не обеспечивает отбора единиц, которые представляли бы все части совокупности.
Несплошное наблюдение заведомо ориентируется на учет некоторой, как правило, достаточно массовой части единиц наблюдения, позволяющей тем не менее получить устойчивые обобщающие характеристики все статистической совокупности. В статистической практике применяются различные виды не сплошного наблюдения: выборочное, способ основного массива, анкетное и монографическое. Качество несплошного наблюдения уступает результатам сплошного, однако в ряде случаев статистическое наблюдение вообще оказывается возможным только как несплошное.
Для получения представительной характеристики всей статистической совокупности по некоторой части ее единиц применяют выборочное наблюдение, основанное на научных принципах формирования выборочной совокупности. Случайный характер отбора единиц совокупности гарантирует беспристрастность результатов выборки, предупреждает их тенденциозность.
По способу основного массива производится отбор наиболее крупных, наиболее существенных единиц совокупности, преобладающих в общей их массе по изучаемому признаку.
Специфическим видом статистического наблюдения служит монографическое описание, представляющее собой детальное обследование отдельного, но весьма типичного объекта, обусловливающего интерес и с точки зрения изучения всей совокупности.
2. Применение несплошного наблюдения на практике
статистический наблюдение
Статистическое наблюдение можно организовать сплошное и несплошное. В выборочном методе несплошного наблюдения обобщающие показатели совокупности устанавливаются по некоторой ее части (сравнительно небольшой 510% всей совокупности). Совокупность, из которой производится отбор части единиц, называется генеральной.
Отобранная часть единиц называется выборочной совокупностью, или выборкой. При использовании выборочного метода исследования осуществляется в более короткие сроки и с минимальными затратами труда и средств. Это повышает оперативность и уменьшает ошибки регистрации.
Выборочный метод является единственно возможным при разрушающем контроле качества продукции. Он распространен в государственной и ведомственной статистике (бюджетные обследования семей рабочих, крестьян, служащих; обследование жилищных условий), в торговле (спрос населения на товар; эффективность новых форм торговли) и т.д.
Методы несплошного статистического наблюдения это методы, позволяющие по специально отобранной части обследуемой совокупности произвести расчет обобщенных характеристик всей совокупности и показателей точности этого расчета. Преимущества и недостатки рассматриваемых методов непосредственно следуют из этого определения и обусловлены в основном двумя их свойствами:
возможностью ограничить наблюдение частью совокупности;
наличием дополнительных ошибок, обусловленных неполнотой наблюдения (ошибок репрезентативности).
В настоящее время отсутствует общепринятая классификация методов несплошного статистического наблюдения. По существу, имеется только перечень методов, в котором необходимо отметить:
выборочный метод со всеми его разновидностями;
систематический (механический) отбор;
типический отбор;
многоступенчатый отбор;
многофазный отбор;
моментные наблюдения;
малая выборка;
метод основного массива;
монографический метод;
анкетный метод;
корреспондентский метод;
цензовое наблюдение.
3.Определение и краткая характеристика методов
Выборочный метод реально представляет собой большую группу методов, существенно отличающихся друг от друга, в основе которых лежит, как правило, принцип случайного отбора единиц наблюдения из исследуемой (генеральной) совокупности.
Выборочный метод наиболее теоретически разработан именно потому, что основан на принципе случайного отбора. При случайном отборе каждая единица генеральной совокупности имеет равную возможность попасть в выборочную совокупность, то есть соблюдается так называемый принцип случайного отбора. Например, при проведении тиража какойлибо лотереи применяется этот принцип, так как имеется абсолютно равная возможность выигрыша (попадания в выборку) любого номера билета. Можно сказать то же самое и подругому: выигрыш того или иного билета это дело случая.
Случайный отбор используется и при жеребьевке. Если из 10000 школьников, с целью изучения их успеваемости, в школах одного района необходимо отобрать 1000, то это можно сделать следующим образом: написать на отдельных листочках фамилии всех школьников и вслепую вытащить 1000.
Случайный отбор может быть бесповторный и повторный. Чаще на практике применяется бесповторный отбор, то есть единица, попавшая в выборочную совокупность, обратно в генеральную не возвращается, следовательно численность генеральной совокупности все время уменьшается. По такой схеме проходят тиражи различных лотерей. При повторном отборе отобранная единица наблюдения возвращается в генеральную совокупность обратно. Таким образом, численность генеральной совокупности в процессе проведения выборочного обследования остается все время неизменной. В случае со школьниками это означало бы следующее: при попадании определенного листочка с фамилией в число случайно отобранных, этот листочек снова возвращался бы обратно и опять имел бы равную с другими возможность попасть в выборочную совокупность.
Статистический анализ выводов непрерывных данных на основе доверительных интервалов — Традиционный и новый подходы
Приложение 1: Запись ЭЭГ и предварительная обработка данных
ЭЭГ регистрировалась с использованием 16-канального усилителя переменного / постоянного тока с активными электродами для кожи головы Ag / AgCl (V- Amp, Brain Products). Электроды ЭЭГ помещали с колпачком электрода (actiCap, Brain Products) в соответствии с международной системой 10–20 по F3, Fz, F4, FCz, C3, Cz, C4, P3, Pz и P4. Электроокулограмма (ЭОГ) была записана с помощью электродов на наружном уголке глаза обоих глаз, а также над и под правым глазом.Все электроды были привязаны в режиме онлайн к левому сосцевидному отростку и повторно привязаны после сбора данных к усредненным сосцевидным отросткам. Импеданс электрода поддерживался ниже 20000 Ом, что подходит для активных электродов. Данные оцифровывались с частотой дискретизации 500 Гц. Данные ЭЭГ и ЭОГ были отфильтрованы в режиме онлайн с помощью высокочастотного фильтра с частотой 0,01 Гц. Данные ЭЭГ дополнительно фильтровались в автономном режиме с помощью фильтра Баттерворта без фазового сдвига (полоса пропускания 0,2–30 Гц). Глазные артефакты были удалены из непрерывного сигнала ЭЭГ с использованием независимого компонентного анализа Infomax (Makeig, Bell, Jung, & Sejnowski, 1996; Makeig, Jung, Bell, Ghahremani, & Sejnowski, 1997) и были сегментированы на эпохи вокруг выпуска, начиная с 600 г. мс до выпуска и окончание 1200 мс после выпуска.Сегменты были скорректированы по базовой линии путем вычитания средней амплитуды полного сигнала. Затем отдельные сегменты подвергались визуальному осмотру для удаления эпох, содержащих артефакты.
Приложение 2: Проблема оценки дисперсии на основе коэффициентов функции
Чтобы проиллюстрировать, почему может быть проблематичным найти общий прототип функции для определенных типов непрерывных данных (таких как ЭЭГ), мы подобрали два примера кривых данных из наших данных ЭЭГ. n {a} _i \ cdot \ sin \ left ({b} _i \ cdot x + {c} _i \ right), $$
, где a представляет амплитуду, b частоту и c фазу для каждого члена синусоидальной волны.Мы вычислили сумму восьми членов синусоидальной волны для каждой из двух кривых ЭЭГ, чтобы получить надежное соответствие. Коэффициенты при восьми членах a 1–8 , b 1–8 и c 1–8 показаны в таблице 1. Обоснование для подгонки данных с математическими функциями в FBRT заключается в том, что коэффициенты аппроксимирующих функций используются для оценки дисперсии в данных. Таким образом, следующим шагом в нашем примере будет определение членов синусоидальной волны на кривой 1, которые соответствуют членам синусоидальной волны на кривой 2.Другими словами, термины должны быть отсортированы так, чтобы соответствующие термины представляли один и тот же элемент кривой. Это соответствие между синусоидальными волнами различных кривых важно для оценки дисперсии. Чтобы найти разумный порядок, давайте посмотрим на частотную составляющую ( b ) каждого члена на кривой 1 (C1) и попытаемся найти соответствующий частотный коэффициент на кривой 2 (C2). Сортировка также может быть основана на коэффициентах a i или c i , но для демонстрации проблемы достаточно сосредоточиться на b i .Начиная с C1 (b 1 ) = 0,006, очевидным соответствующим частотным коэффициентом C2 будет C2 (b 1 ). Следовательно, мы сопоставляем первый член синусоидальной волны C1 с первым членом C2. Далее C1 (b 2 ) = 0,095. Наилучшим соответствием будет C2 (b 7 ) = 0,115. Однако частоты, описанные в C1 (b 2 ) и C2 (b 7 ), различаются уже на 18%. Исходя из этого, C1 (b 3 ) = 0,057 лучше всего соответствует C2 (b 5 ), но C2 (b 5 ) также будет единственным подходящим соответствием для C1 (b 4 ).Выбор C2 (b 4 ) в качестве следующего наилучшего соответствия для C1 (b 4 ) подчеркивает проблему поиска соответствующих членов на кривых, поскольку разница в частотах, включенных в C1 (b 4 ) и C2 (b 4 ) уже 47,5%. Обратите внимание, что этот пример построен с использованием двух кривых. Проблема поиска соответствующих членов в других кривых набора данных становится все труднее, чем больше размер выборки.
Вариант этого метода подгонки был использован Lenhoff et al.(1999). Они также использовали сумму синусоидальных членов, чтобы соответствовать своим данным, но они определили фиксированные частоты для членов. При фиксации частотных составляющих ( b i ) членов синусоидальной волны становится ясно, какие члены на нескольких кривых соответствуют. Мы попытались применить эту логику к нашим данным ЭЭГ, но выявили две проблемы, которые не позволили нам создать достоверные совпадения. Во-первых, выбранные фиксированные частоты не полностью отражали частотные составляющие исходных кривых данных.Конкретно, было невозможно выбрать точные частоты, из которых была составлена исходная кривая. Даже преобразование Фурье не может решить эту проблему из-за ограничений разрешения. Такой сдвиг частоты приведет к менее точным подгонкам. Во-вторых, что более важно, пределы функций как представления кривых данных становятся очевидными, когда «единичное» (т. Е. Уникальное и временно ограниченное) событие, такое как эффект (например, компонент ERP в ЭЭГ), проявляется внутри кривая данных.Частотных компонентов, которые могли бы соответствовать общему ходу данных, будет недостаточно для адекватного соответствия эффекту. Как следствие, эффект, вероятно, будет уменьшен, и поэтому построение доверительных интервалов на основе этих соответствий не рекомендуется.
Таблица 1 Коэффициенты членов синусоидальной волны для первых двух кривых ЭЭГ в примерном наборе данныхПриложение 3: Расчет доверительных интервалов с использованием PBRT
Данные, используемые для обработки, должны быть синхронизированы и, при необходимости, нормализованы по времени, чтобы обеспечить временное соответствие между точками данных по кривым. B \) в окне предустановленных эффектов W Eff [1,…, n ] для набора данных, представляющего нулевую гипотезу, был вычислен доверительный интервал.В примере наших данных ЭЭГ разумно предположить, что дисперсия данных в DS A и DS B может существенно различаться (см. Makeig, 1993). Следовательно, в нашем случае расчет доверительного интервала был основан на данных, включенных в DS A , потому что они представляют наше нулевое условие (то есть проверки совпадений). Расчет доверительного интервала с учетом одинаковых отклонений в обоих наборах данных показан в конце этого технического описания.m \), каждая из которых содержала k произвольно выбранных кривых данных.
Чтобы оценить, какое количество BS было бы достаточно, мы рассчитали развитие изменчивости в оценке C для повторных запусков алгоритма начальной загрузки с различным количеством BS ( m ). На Рисунке 3 показано, что вариабельность оценки уменьшается с увеличением количества БС м . На основе этой изменчивости мы решили вычислить м = 400 BS в нашем примере, потому что в этот момент изменчивость оценки упала ниже 5% от величины C .m (n) \ right)} $$
(2)
Для достижения желаемого уровня достоверности (1 — α ), где α — коэффициент ошибок в семье, необходимо определить постоянный коэффициент масштабирования C для вычисления нижнего (L — ) и верхние (L + ) пределы доверительной полосы с использованием уравнения. 3.
$$ {L} _ {\ pm} (n) = {\ mu} _ {\ overline {BS}} (n) \ pm C \ cdot {\ sigma} _ {\ overline {BS}} (n) $$
(3)
Окончательный коэффициент масштабирования C выбран так, чтобы относительная частота p , с которой отдельные кривые псевдодыборки оставались в пределах верхнего и нижнего пределов доверительной полосы на протяжении всего окна полного эффекта, составляла p = 1 — α (4).м \). Процентиль (1 — α ) результирующего распределения d критерий соответствует критерию, сформулированному в уравнении. 4.
Расчет для наборов данных с аналогичными отклонениями
Если аналогичные отклонения можно предположить для обоих наборов данных ( DS A и DS B ) для анализа, целесообразно оценить разброс данных на основе обоих наборов данных, чтобы получить более надежную оценку.В приведенном выше примере коэффициент масштабирования C был рассчитан только с использованием данных из DS A . Чтобы адаптировать PBRT к аналогичным отклонениям в обоих наборах данных, скорректированный коэффициент C можно рассчитать следующим образом:
В дополнение к коэффициенту C , который был рассчитан для DS A (т. Е. C A ), второй C рассчитывается с использованием данных из DS B (т.е.e., C B ), с той же процедурой, которая использовалась для получения C A . Затем C A и C B усредняются для получения \ (\ overline {C} \), как показано в уравнении. 5.
$$ \ overline {C} = \ frac {C_A + {C} _B} {2} $$
(5)
Если размеры выборки в DS A и DS B различаются, следует использовать средневзвешенное значение.Наконец, доверительные интервалы для каждого индекса рассчитываются, как показано в формуле. 6.
$$ {L} _ {\ pm} (n) = {\ mu} _A (n) \ pm \ overline {C} \ cdot {\ sigma} _A (n) $$
(6)
Сравнения внутри субъектов с использованием PBRT
В соответствии с логикой теста зависимых выборок t , сравнения внутри субъектов могут проводиться путем проверки различий между условиями относительно нуля. k \ right \} \), представляющий данные посттеста для тех же участников, альтернативная гипотеза будет формализована как H 1: ( DS A — DS B ) ≠ 0, а нулевая гипотеза как H 0: ¬ H 1.В стиле теста зависимых выборок t доверительный интервал будет сгенерирован на основе данных разности путем применения процедуры PBRT, как мы описали ее выше. Полученный доверительный интервал впоследствии может быть использован для проверки гипотез. Если нулевое значение выходит за пределы доверительного интервала хотя бы для одного индекса, значительная разница между до- и посттестами будет предложена для всех индексов, выходящих за пределы диапазона.
Анализ мощности
Поскольку мощность описывает выразительность статистического теста с помощью ошибки β , необходимо количественно определить β .
Для оценки β требуется известный эффект. Например, при проведении анализа мощности для доверительных интервалов эффект должен быть представлен кривой эффекта (например, кривой, которую можно увидеть на рисунке 4B).
Первым шагом является добавление постулируемого эффекта к каждой из набора кривых данных м , которые представляют нулевую гипотезу. В результате построено м кривых искусственного воздействия (АЭК). Кривые данных, которые представляют нулевую гипотезу, затем используются на этапе 2 для вычисления доверительного интервала (CB), как показано выше.Относительное количество AEC, которые не покидают CB в пределах окна эффекта, можно принять как оценку вероятности ошибки β (Тип II). Затем рассчитывается мощность, как показано в формуле. 7.
Приложение 4: Создание кривых искусственных данных для моделирования
Чтобы проверить влияние различных показателей центральной тенденции при использовании PBRT, мы сгенерировали искусственных кривых данных , которые имели характеристики, аналогичные характеристикам нашего реального кривые данных.Чтобы создать эти искусственные кривые, подобные ЭЭГ, мы использовали синусоидальную функцию с 24 коэффициентами, чтобы воспроизвести основные характеристики исходных кривых совпадений. Подгонка была применена к средней кривой, а также была исключена тенденция, чтобы избежать подгонки какого-либо тренда, присутствующего в исходных данных. Эта аппроксимация была аналогичным образом обозначена как материнская кривая и использовалась в качестве источника для всех наших искусственных кривых. В процессе создания индивидуальных кривых считывались различные тренды, и к материнской кривой применялся шум, чтобы получить реалистичные модели.Шум состоял из изменчивости коэффициентов функции и локального случайного шума, добавляемого к каждой точке данных. На последнем этапе мы добавили эффект, обнаруженный в предварительном исследовании, к половине кривых, чтобы создать искусственные кривые ошибок. Мы подтвердили наши созданные кривые данных двумя способами. Сначала мы визуально изучили искусственные данные и субъективно сравнили их с исходными данными. Во-вторых, мы сравнили профили изменчивости и автокорреляции исходной и искусственной кривых.Результаты как субъективной, так и объективной проверки можно увидеть на рис. 8.
Рис. 8Сравнение исходных кривых данных ЭЭГ и искусственно созданных кривых данных, используемых для моделирования. (A) Исходные кривые данных, записанные во время сбора данных. (B) Кривые искусственных данных. Сравнения основаны на таких объективных параметрах, как профиль автокорреляции (C) и профиль стандартного отклонения (D). На всех диаграммах исходные данные напечатаны черным цветом, а искусственно созданные данные окрашены в серый цвет
| Переменная — это любые характеристики, число или количество, которые можно измерить или подсчитать .Переменная также может называться элементом данных . Возраст, пол, коммерческие доходы и расходы, страна рождения, капитальные затраты, классы, цвет глаз и тип транспортного средства являются примерами переменных. Она называется переменной, потому что значение может варьироваться между единицами данных в генеральной совокупности и может меняться со временем. Например; « доход » — это переменная, которая может варьироваться между единицами данных в совокупности (т. е. изучаемые люди или предприятия могут иметь разные доходы), а также может меняться со временем для каждой единицы данных (т.е. доход может увеличиваться или уменьшаться). Какие типы переменных? Существуют разные способы описания переменных в зависимости от того, как они могут быть изучены, измерены и представлены. Числовые переменные имеют значения, которые описывают измеряемую величину в виде числа, например «сколько» или «сколько». Следовательно, числовые переменные являются количественными переменными. Числовые переменные могут быть далее описаны как непрерывные или дискретные:
Данные, собранные для числовой переменной, являются количественными данными. Категориальные переменные имеют значения, которые описывают «качество» или «характеристику» единицы данных, например «какой тип» или «какая категория». Категориальные переменные делятся на взаимоисключающие (в одной или другой категории) и исчерпывающие (включают все возможные варианты) категории . Следовательно, категориальные переменные являются качественными переменными и, как правило, представлены нечисловыми значениями. Категориальные переменные могут быть далее описаны как порядковые или номинальные:
Данные, собранные для категориальной переменной, являются качественными данными. Блок-схема типов переменных: Вернуться на главную страницу языка статистики |
Выбор правильного статистического теста
Статистические тесты используются для проверки гипотез. Их можно использовать для:
- ,
- , определяют, имеет ли переменная-предиктор статистически значимую связь с переменной результата.
- оценить разницу между двумя или более группами.
Статистические тесты предполагают нулевую гипотезу об отсутствии связи или различий между группами.Затем они определяют, выходят ли наблюдаемые данные за пределы диапазона значений, предсказанных нулевой гипотезой.
Если вы уже знаете, с какими типами переменных вы имеете дело, вы можете использовать блок-схему, чтобы выбрать правильный статистический тест для ваших данных.
Блок-схема статистических испытаний
Что делает статистический тест?
Статистические тесты работают путем вычисления статистики теста — числа, которое описывает, насколько взаимосвязь между переменными в вашем тесте отличается от нулевой гипотезы об отсутствии взаимосвязи.
Затем он вычисляет p -значение (значение вероятности). Значение p оценивает, насколько вероятно, что вы увидите разницу, описываемую статистикой теста, если бы нулевая гипотеза об отсутствии связи была верной.
Если значение тестовой статистики более экстремально, чем статистика, рассчитанная на основе нулевой гипотезы, то вы можете вывести статистически значимую взаимосвязь между предикторами и переменными результата.
Если значение статистики теста менее экстремально, чем значение, вычисленное на основе нулевой гипотезы, то вы можете сделать вывод об отсутствии статистически значимой связи между переменными предиктора и исходом.
Когда проводить статистический тест
Вы можете выполнять статистические тесты данных, которые были собраны статистически достоверным образом — либо посредством эксперимента, либо посредством наблюдений, выполненных с использованием методов вероятностной выборки.
Чтобы статистический тест был действительным, размер вашей выборки должен быть достаточно большим, чтобы приблизительно соответствовать истинному распределению изучаемой совокупности.
Чтобы определить, какой статистический тест использовать, вам необходимо знать:
- соответствуют ли ваши данные определенным предположениям.
- типов переменных, с которыми вы имеете дело.
Статистические допущения
Статистические тесты делают некоторые общие предположения о данных, которые они тестируют:
- Независимость наблюдений (также известная как отсутствие автокорреляции): наблюдения / переменные, которые вы включаете в свой тест, не связаны (например, несколько измерений одного испытуемого не являются независимыми, в то время как измерения нескольких разных испытуемых независимы) .
- Однородность дисперсии : дисперсия в каждой сравниваемой группе одинакова для всех групп. Если в одной группе будет намного больше вариаций, чем в других, это ограничит эффективность теста.
- Нормальность данных : данные подчиняются нормальному распределению (также известному как колоколообразная кривая). Это предположение применимо только к количественным данным.
Если ваши данные не соответствуют предположениям о нормальности или однородности дисперсии, вы можете выполнить непараметрический статистический тест , который позволяет проводить сравнения без каких-либо предположений о распределении данных.
Если ваши данные не соответствуют предположению о независимости наблюдений, вы можете использовать тест, который учитывает структуру ваших данных (тесты с повторными измерениями или тесты, включающие блокирующие переменные).
Типы переменных
Типы переменных, которые у вас есть, обычно определяют, какой тип статистического теста вы можете использовать.
Количественные переменные представляют количество вещей (например, количество деревьев в лесу). Типы количественных переменных включают:
- Непрерывный (a.k.a переменные соотношения): представляют собой меры и обычно могут быть разделены на единицы меньше единицы (например, 0,75 грамма).
- Дискретные (также известные как целочисленные переменные): представляют собой счетчики и обычно не могут быть разделены на единицы меньше единицы (например, 1 дерево).
Категориальные переменные представляют группы вещей (например, различные породы деревьев в лесу). Типы категориальных переменных включают:
- Порядковый номер : представить данные с порядком (например,грамм. рейтинги).
- Номинал : представляют названия групп (например, торговые марки или названия видов).
- Двоичный : представление данных с результатом да / нет или 1/0 (например, победа или поражение).
Выберите тест, который соответствует типам предикторов и переменных результата, которые вы собрали (если вы проводите эксперимент, это независимые и зависимые переменные). Обратитесь к таблицам ниже, чтобы увидеть, какой тест лучше всего соответствует вашим переменным.
Получение отзывов о языке, структуре и макете
Профессиональные редакторы корректируют и редактируют вашу статью, уделяя особое внимание:
- Академический стиль
- Расплывчатые предложения
- Грамматика
- Единообразие стиля
См. Пример
Выбор параметрического теста: регрессия, сравнение или корреляция
Параметрические тесты обычно предъявляют более строгие требования, чем непараметрические тесты, и могут делать более сильные выводы из данных.Их можно проводить только с данными, которые соответствуют общим допущениям статистических тестов.
Наиболее распространенные типы параметрических тестов включают регрессионные тесты, тесты сравнения и тесты корреляции.
Регрессионные тесты
Регрессионные тесты используются для проверки причинно-следственных связей . Они ищут влияние одной или нескольких непрерывных переменных на другую переменную.
| Переменная-предиктор | Переменная результата | Пример вопроса исследования | |
|---|---|---|---|
| Простая линейная регрессия | Как доход влияет на продолжительность жизни? | ||
| Множественная линейная регрессия |
| Как влияет доход и количество тренировок в день на продолжительность жизни? | |
| Логистическая регрессия | Как влияет дозировка препарата на выживаемость испытуемого? |
Сравнительные испытания
Сравнительные тесты ищут различий между средними значениями группы .Их можно использовать для проверки влияния категориальной переменной на среднее значение какой-либо другой характеристики.
T-критерий используется при сравнении средних значений ровно двух групп (например, среднего роста мужчин и женщин). Тесты ANOVA и MANOVA используются при сравнении средних значений более чем двух групп (например, средний рост детей, подростков и взрослых).
| Переменная-предиктор | Переменная результата | Пример вопроса исследования | |
|---|---|---|---|
| Парный t-тест |
| Какое влияние оказывают две разные программы подготовки к экзаменам на средние результаты экзаменов учащихся одного класса? | |
| Независимый t-тест |
| Какая разница в средних экзаменах учащихся двух разных школ? | |
| ANOVA |
| Какова разница в средних уровнях боли у послеоперационных пациентов, получавших три разных обезболивающих? | |
| MANOVA |
|
| Как вид цветка влияет на длину лепестка, ширину лепестка и длину стебля? |
Корреляционные тесты
Корреляционные тесты проверяют, связаны ли две переменные без допущения причинно-следственных связей.
Их можно использовать для проверки автокоррелированности двух переменных, которые вы хотите использовать (например) в тесте множественной регрессии.
| Переменная-предиктор | Переменная результата | Пример вопроса исследования | |
|---|---|---|---|
| Пирсон r | непрерывный | непрерывный | Как связаны широта и температура? |
Выбор непараметрического теста
Непараметрические тесты не делают столько предположений о данных и полезны, когда нарушается одно или несколько общих статистических предположений.Однако выводы, которые они делают, не так сильны, как при параметрических тестах.
| Переменная-предиктор | Переменная результата | Использование вместо… | |
|---|---|---|---|
| Spearman’s r | Пирсона r | ||
| Тест независимости хи-квадрат | Пирсона r | ||
| Знаковая проверка | Одинарная проба т проба | ||
| Краскал – Уоллис H |
| ANOVA | |
| ANOSIM |
|
| MANOVA |
| Тест Wilcoxon Rank-Sum |
| Независимый t-тест | |
| Знаковый тест Вилкоксона |
| Парный t-тест | |
Блок-схема: выбор статистического теста
Эта блок-схема помогает вам выбирать среди параметрических тестов.Для непараметрических альтернатив проверьте таблицу выше.
Часто задаваемые вопросы о статистических тестах
- Что такое тестовая статистика?
Статистика теста — это число, вычисленное с помощью статистического теста. Он описывает, насколько далеко ваши наблюдаемые данные от нулевой гипотезы об отсутствии связи между переменными или различиях между группами выборки.
Статистика теста показывает, насколько две или более группы отличаются от среднего значения генеральной совокупности или насколько отличается линейный наклон от наклона, предсказанного нулевой гипотезой. В разных статистических тестах используются разные статистические данные.
- Что такое статистическая значимость?
Статистическая значимость — это термин, используемый исследователями, чтобы заявить, что маловероятно, что их наблюдения могли иметь место при нулевой гипотезе статистического теста.Значимость обычно обозначается значением p или значением вероятности.
Статистическая значимость произвольна — она зависит от порога или значения альфа, выбранного исследователем. Наиболее распространенный порог — p <0,05, что означает, что данные, вероятно, будут появляться менее чем в 5% случаев при нулевой гипотезе.
Когда значение p падает ниже выбранного альфа-значения, мы говорим, что результат теста статистически значим.
- В чем разница между количественными и категориальными переменными?
Количественные переменные — это любые переменные, в которых данные представляют суммы (например, рост, вес или возраст).
Категориальные переменные — это любые переменные, в которых данные представляют группы.Сюда входят рейтинги (например, места в гонке), классификации (например, марки хлопьев) и бинарные результаты (например, подбрасывание монеты).
Вам необходимо знать, с какими типами переменных вы работаете, чтобы выбрать правильный статистический тест для ваших данных и интерпретировать ваши результаты.
13. Дизайн исследования и выбор статистического теста
Дизайн
Во многих отношениях дизайн исследования более важен, чем анализ.Плохо спланированное исследование никогда не может быть восстановлено, в то время как плохо проанализированное исследование обычно можно проанализировать повторно. (1) Рассмотрение дизайна также важно, потому что дизайн исследования будет определять способ анализа данных.
Большинство медицинских исследований рассматривают вход, который может быть медицинским вмешательством или воздействием потенциально токсичного соединения, и выходом, который является некоторой мерой состояния здоровья, на которое, как предполагается, должно повлиять вмешательство. Самый простой способ категоризации исследований — это привязка к временной последовательности, в которой изучаются входные и выходные данные.
Самыми мощными исследованиями являются проспективные исследования, парадигмой которых является рандомизированное контролируемое исследование. В этом случае пациенты с заболеванием рандомизированы для получения одного из двух (или более) курсов лечения, одно из которых может быть контрольным. Методы рандомизации были описаны в главе 3. Важность рандомизации состоит в том, что мы, как мы полагаем, в группах длительного лечения будут сбалансированы по известным и неизвестным прогностическим факторам. Важно, чтобы лечение проводилось одновременно — активное и контрольное лечение проводились в один и тот же период времени.
План параллельных групп — это план, в котором лечение и контроль распределяются между разными людьми. Чтобы обеспечить терапевтический эффект простого лечения, контроль может состоять из плацебо, инертного вещества, которое физически идентично активному соединению. Если возможно, исследование должно быть двойным слепым: ни исследователь, ни субъект не знают, какое лечение проходит субъект. Иногда невозможно ослепить субъектов, например, когда лечение представляет собой некоторую форму санитарного просвещения, но часто можно гарантировать, что люди, оценивающие результат, не знают о лечении.Пример испытания в параллельных группах приведен в таблице 7.1, в которой различные препараты отрубей были испытаны на разных людях.
Согласованный дизайн возникает, когда рандомизация проводится между подобранными парами, как, например, в упражнении 6.2, в котором рандомизация проводилась между различными частями тела пациента.
Перекрестное исследование — это исследование, в котором два или более лечения последовательно применяются к одному и тому же субъекту. Преимущество состоит в том, что каждый субъект затем действует как свой собственный контроль, и поэтому может потребоваться меньшее количество субъектов.Главный недостаток заключается в том, что может иметь место переносимый эффект, так как действие второго лечения зависит от первого лечения. Пример перекрестного испытания приведен в таблице 7.2, в которой сравниваются разные дозировки отрубей у одного и того же человека. Существует ряд отличных книг о клинических испытаниях. (2, 3)
Одной из основных угроз действительности клинического испытания является соблюдение требований. Пациенты могут выбывать из испытаний, если лечение неприятно, и часто не принимают лекарства в соответствии с предписаниями.Обычно применяют прагматический подход и анализируют по намерению лечить, то есть анализировать исследование по лечению, которое было назначено субъекту, а не по тому, которое он фактически принял. Альтернативой является анализ по протоколу или в ходе исследования. Разумеется, о прекращении занятий следует сообщать по группе лечения. Доступен контрольный список для написания отчетов о клинических испытаниях. (4, 5)
Квазиэкспериментальный план — это план, в котором лечение распределяется не случайно. Пример этого приведен в таблице 9.1, на котором сравниваются травмы в двух зонах падения. Это может быть связано с потенциальными предубеждениями, поскольку причина, по которой человека помещают в определенную зону сброса, может быть связана с его риском растяжения связок лодыжки.
Когортное исследование — это исследование, в котором пациенты, изначально здоровые, наблюдаются в течение определенного периода времени. Некоторые будут подвергаться воздействию какого-либо фактора риска, например, курения сигарет. Результатом может быть смерть, и мы можем быть заинтересованы в том, чтобы связать фактор риска с конкретной причиной смерти.Ясно, что это должны быть большие, долгосрочные исследования, и их проведение, как правило, требует больших затрат. Если в прошлом записи велись в обычном порядке, то может быть проведено историческое когортное исследование, примером которого является исследование аппендицита, описанное в главе 6. Здесь когорта — это все случаи аппендицита, допущенные за определенный период, и выборка записи могут быть проверены ретроспективно. Типичным примером может быть просмотр записей о весе при рождении и соотнесение веса при рождении с заболеванием в более позднем возрасте.
Эти исследования по существу отличаются от ретроспективных исследований, которые начинаются с больных людей, а затем исследуются возможные воздействия. Такие исследования случай-контроль обычно проводятся в качестве предварительного расследования, поскольку они относительно быстрые и недорогие. Сравнение артериального давления у фермеров и типографий, приведенное в главе 3, является примером исследования случай-контроль. Это ретроспективно, потому что мы спорили от артериального давления до профессии и не начинали с субъектов, назначенных на занятие.В исследованиях случай-контроль существует множество сбивающих с толку факторов. Например, вызывает ли профессиональный стресс высокое кровяное давление, или люди, склонные к высокому кровяному давлению, выбирают стрессовые занятия? Особой проблемой является предвзятость воспоминаний, поскольку пациенты с заболеванием более мотивированы вспоминать очевидно тривиальные эпизоды в прошлом, чем контрольная группа, не имеющая заболевания.
Поперечные исследования являются обычными и включают опросы, лабораторные эксперименты и исследования для изучения распространенности заболевания.Исследования, подтверждающие инструменты и анкеты, также являются перекрестными исследованиями. Исследование концентрации свинца в моче у детей, описанное в главе 1, и исследование взаимосвязи между ростом и анатомическим мертвым пространством легких в главе 11 также были перекрестными исследованиями.
Размер выборки
Один из наиболее частых вопросов, которые задают статистику о дизайне, — это количество пациентов, которые нужно включить. Это важный вопрос, потому что, если исследование слишком мало, оно не сможет ответить на поставленный вопрос и будет пустой тратой времени и денег.Это также может считаться неэтичным, поскольку пациенты могут подвергаться риску без видимой пользы. Тем не менее, исследования не должны быть слишком большими, потому что ресурсы были бы потрачены впустую, если бы им хватило меньшего числа пациентов. Размер выборки зависит от четырех критических величин: частоты ошибок типа I и типа II α и β (обсуждаются в главе 5), изменчивости данных σ² и величины эффекта d. В испытании величина эффекта — это величина, на которую мы ожидаем различий между двумя видами лечения, или разница, которая будет иметь клиническую ценность.
Обычно α и β имеют фиксированные значения 5% и 20% (или 10%) соответственно. Простая формула для двухгруппового параллельного исследования с непрерывным результатом состоит в том, что требуемый размер выборки для каждой группы задается для двустороннего α, равного 5%, и β, равного 20%. Например, в испытании по снижению артериального давления, если клинически значимый эффект для диастолического артериального давления составляет 5 мм рт. Ст., А стандартное отклонение между субъектами составляет 10 мм рт. Ст., Нам потребуется n = 16 x 100/25 = 64 пациента на группу в изучение. Размер выборки увеличивается как квадрат стандартного отклонения данных (дисперсия) и уменьшается обратно пропорционально квадрату размера эффекта.Удвоение размера эффекта уменьшает размер выборки на четыре — гораздо проще обнаруживать большие эффекты! На практике размер выборки часто определяется другими критериями, такими как финансы или ресурсы, и формула используется для определения реалистичного размера эффекта. Если он будет слишком большим, то от исследования придется отказаться или увеличить его в размерах. Machin et al. давать советы по расчетам размера выборки для самых разных дизайнов исследований. (6)Выбор теста
С точки зрения выбора статистического теста наиболее важным вопросом является «какова основная гипотеза исследования?» В некоторых случаях гипотеза отсутствует; следователь просто хочет «посмотреть, что там есть».Например, в исследовании распространенности нет гипотезы для проверки, а размер исследования определяется тем, насколько точно исследователь хочет определить распространенность. Если нет гипотезы, значит, нет статистической проверки. Важно решить априори, какие гипотезы являются подтверждающими (т. Е. Проверяют некоторую предполагаемую взаимосвязь), а какие являются исследовательскими (предполагаются данными). Ни одно исследование не может подтвердить целую серию гипотез.
Разумный план — строго ограничить количество подтверждающих гипотез.Хотя можно использовать статистические тесты для гипотез, предложенных данными, значения P следует использовать только в качестве рекомендаций, а результаты рассматривать как очень предварительные, пока не будут подтверждены последующими исследованиями. Полезным руководством является использование поправки Бонферрони, которая просто утверждает, что если проверяется n независимых гипотез, следует использовать уровень значимости 0,05 / n. Таким образом, при наличии двух независимых гипотез результат будет признан значимым только при P <0,025. Обратите внимание, что, поскольку тесты редко бывают независимыми, это очень консервативная процедура - вряд ли она отклонит нулевую гипотезу.
Затем следователь должен спросить: «Независимы ли данные?» Это может быть трудно решить, но, как правило, результаты одного и того же человека или от совпадающих лиц не являются независимыми. Таким образом, результаты перекрестного исследования или исследования случай-контроль, в котором контрольная группа была сопоставлена со случаями по возрасту, полу и социальному классу, не являются независимыми. В целом верно, что анализ должен отражать дизайн, и поэтому согласованный дизайн должен сопровождаться согласованным анализом.Результаты, измеряемые с течением времени, требуют особой осторожности. (7) Одна из наиболее распространенных ошибок в статистическом анализе — рассматривать зависимые переменные как независимые. Например, предположим, что мы изучаем лечение язв на ногах, при котором у некоторых людей были язвы на каждой ноге. У нас может быть 20 субъектов с 30 язвами, но количество независимых единиц информации равно 20, потому что состояние язвы на одной ноге может влиять на состояние язвы на другой ноге, и анализ, который рассматривал язвы как независимые наблюдения, был бы неверным. .Для правильного анализа смешанных парных и непарных данных проконсультируйтесь со статистиком.
Следующий вопрос: «Какие типы данных измеряются?» Используемый тест должен определяться данными. Выбор теста для сопоставленных или парных данных описан в, а для независимых данных — в.
Полезно определить входные и конечные переменные. Например, в клиническом исследовании входной переменной является тип лечения — номинальная переменная — и результатом может быть некоторая клиническая мера, возможно, с нормальным распределением.В таком случае требуется испытание t (таблица 13.2). Однако, если входная переменная является непрерывной, скажем, клинической оценкой, и результат номинальный, скажем, вылечен или не излечен, логистическая регрессия является необходимым анализом. В этом случае t-тест может помочь, но не даст нам того, что нам нужно, а именно вероятности излечения для данного значения клинической оценки. В качестве другого примера предположим, что у нас есть перекрестное исследование, в котором мы спрашиваем случайную выборку людей, считают ли они, что их терапевт хорошо работает, по пятибалльной шкале, и мы хотим выяснить, имеют ли женщины более высокое мнение о себе. врачей общей практики, чем у мужчин.Входная переменная — пол, которая является номинальной. Переменной результата является пятибалльная порядковая шкала. Мнение каждого человека не зависит от мнения других, поэтому у нас есть независимые данные. Из мы должны использовать критерий χ² для тренда или U-критерий Манна-Уитни (с поправкой на связи). Однако обратите внимание, что если у одних людей есть общий врач, а у других нет, то данные не являются независимыми, и требуется более сложный анализ.
Обратите внимание, что эти таблицы следует рассматривать только как руководство, и каждый случай следует рассматривать по существу.
(a) Если данные подвергаются цензуре.
(b) Тест Крускала-Уоллиса используется для сравнения порядковых или ненормальных переменных для более чем двух групп и является обобщением U-критерия Манна-Уитни. Этот метод выходит за рамки этой книги, но описан в более сложных книгах и доступен в обычном программном обеспечении (Epi-Info, Minitab, SPSS).
(c) Дисперсионный анализ — это общий метод, и одна версия (односторонний дисперсионный анализ) используется для сравнения нормально распределенных переменных для более чем двух групп и является параметрическим эквивалентом критерия Краскела-Уоллиса.
(d) Если выходная переменная является зависимой переменной, то при условии, что остатки (см.) Правдоподобно нормальны, тогда распределение независимой переменной не имеет значения.
(e) Существует ряд более продвинутых методов, таких как регрессия Пуассона, для работы с такими ситуациями. Однако они требуют определенных допущений, и часто бывает проще либо разделить переменную результата на дихотомию, либо рассматривать ее как непрерывную.
Источники
- Кэмпбелл М.Дж., Мачин Д.В: Медицинская статистика: здравый смысл, 2-е изд. Чичестер: Wiley, 1993: 2.
- Pocock SJ. Клинические испытания: практический подход. Чичестер: Wiley, 1982.
- Senn SJ. Дизайн и анализ перекрестных испытаний. Чичестер: Wiley, 1992.
- Гарднер М.Дж., Альтман Д.Г. (редакторы) В: Статистические данные с уверенностью. Издательская группа BMJ, 1989: 103-5.
- Гарднер М.Дж., Машин Д., Кэмпбелл М.Дж. Использование чек-листов при оценке статистического содержания медицинских исследований.BMJ 1986; 292: 810-12.
- Макбин Д., Кэмпбелл М.Дж., Пайерс П., Пинол А. Статистические таблицы для дизайна клинических исследований. Oxford: Blackwell Scientific Publications, 1996.
- Мэтьюз Дж. Н. С., Альтман Д. Г., Кэмпбелл М. Дж., Ройстон Дж. П.. Анализ сенальных измерений в медицинских исследованиях. BMJ 1990; 300: 230-5.
- Альтман Д.Г. Практическая статистика для медицинских исследований . Лондон: Chapman & Hall, 1991.
- Армитаж П., Берри Г. В: Статистические методы в медицинских исследованиях.Oxford: Blackwell Scientific Publications, 1994.
Exercises
Укажите тип исследования, описанный в каждом из следующих пунктов.
13.1 Чтобы исследовать взаимосвязь между потреблением яиц и сердечными заболеваниями, группу пациентов, госпитализированных с инфарктом миокарда, опросили об их потреблении яиц. Группу пациентов соответствующего возраста и пола, поступивших в клинику переломов, также опросили об их потреблении яиц с использованием идентичного протокола.
13.2 Чтобы исследовать взаимосвязь между определенными растворителями и раком, всех сотрудников фабрики опрашивали об их воздействии промышленного растворителя, а также измеряли количество и продолжительность воздействия. Эти субъекты регулярно наблюдались, и через 10 лет были получены копии свидетельств о смерти всех умерших.
13.3 Был проведен опрос всех медсестер, работающих в конкретной больнице. Среди прочих вопросов в анкете задавался вопрос об уровне медсестры и о том, удовлетворена ли она своими карьерными перспективами.
13.4 Для оценки новой школы спины пациенты с болью в пояснице были случайным образом распределены либо в новую школу, либо на традиционную трудовую терапию. Через 3 месяца их спросили об их боли в спине, и независимые наблюдатели наблюдали за поднятием тяжестей.
13.5 В местном отделении неотложной помощи создана новая система сортировки. Чтобы оценить это, время ожидания пациентов было измерено в течение 6 месяцев и сравнено с временем ожидания в сопоставимой соседней больнице.
Понимание качественных, количественных, атрибутивных, дискретных и непрерывных типов данных
«Данные! Данные! Данные! Я не могу делать кирпичи без глины».
— Шерлок Холмс, в книге Артура Конан Дойля Приключение медных буков
Независимо от того, являетесь ли вы величайшим детективом в мире, пытающимся раскрыть дело, или человеком, пытающимся решить проблему на работе, вам понадобится информация. Факты. Данные , как говорит Шерлок Холмс.
Но не все данные одинаковы, особенно если вы планируете анализировать в рамках проекта повышения качества.
Если вы используете статистическое программное обеспечение Minitab, вы можете получить доступ к Ассистенту, который проведет вас пошагово через анализ и поможет определить тип имеющихся данных.
Но по-прежнему важно иметь хотя бы базовое представление о различных типах данных и о том, на какие вопросы вы можете с их помощью ответить.
В этом посте я сделаю базовый обзор типов данных, с которыми вы, вероятно, столкнетесь, и мы будем использовать коробку с моими любимыми конфетами — Jujubes — чтобы проиллюстрировать, как мы можем собирать эти различные типы данных. и для каких типов анализа мы можем его использовать.
Два основных вида данных: качественные и количественные
На самом высоком уровне существует два вида данных: количественные и качественные .
Количественные данные имеют дело с числами и объектами, которые можно измерить объективно: такими измерениями, как высота, ширина и длина. Температура и влажность. Цены. Площадь и объем.
Качественные данные имеют дело с характеристиками и дескрипторами, которые нелегко измерить, но которые можно наблюдать субъективно, например запахи, вкусы, текстуры, привлекательность и цвет.
Вообще говоря, когда вы что-то измеряете и присваиваете ему числовое значение, вы создаете количественные данные. Когда вы что-то классифицируете или судите, вы создаете качественные данные. Все идет нормально. Но это только самый высокий уровень данных: есть также разные типы количественных и качественных данных.
Количественные вкусы: непрерывные данные и дискретные данные
Существует два типа количественных данных, которые также называются числовыми данными: непрерывные и дискретные . Как правило, отсчета дискретны, а измерения непрерывны.
Дискретные данные — это счетчик, который невозможно сделать более точным. Обычно это целые числа. Например, количество детей (или взрослых, или домашних животных) в вашей семье — это дискретные данные, потому что вы учитываете целые, неделимые сущности: у вас не может быть 2,5 детей или 1,3 домашних животных.
Непрерывные данные, с другой стороны, могут быть разделены и сокращены до более тонких и более тонких уровней.Например, вы можете измерять рост своих детей в все более точных масштабах — в метрах, сантиметрах, миллиметрах и т. Д. — так что рост является непрерывными данными.
Если я подсчитываю количество отдельных джужубов в коробке, это число является частью дискретных данных.
Если я использую весы для измерения веса каждой мармеладки или веса всей коробки, это непрерывные данные.
Непрерывные данные могут использоваться во многих различных тестах гипотез.Например, чтобы оценить точность веса, напечатанного на коробке Jujubes, мы могли бы измерить 30 коробок и выполнить t-тест для 1 выборки.
В некоторых анализах одновременно используются непрерывные и дискретные количественные данные. Например, мы могли бы выполнить регрессионный анализ, чтобы увидеть, коррелирует ли вес коробок мармеладов (непрерывные данные) с количеством мармеладов внутри (дискретные данные).
Качественные ароматы: биномиальные данные, номинальные данные и порядковые данные
Когда вы классифицируете или классифицируете что-либо, вы создаете Качественные или атрибутные данные .Есть три основных вида качественных данных.
Двоичные данные помещают вещи в одну из двух взаимоисключающих категорий: правильное / неправильное, истинное / ложное или принятие / отклонение.
Иногда я получаю коробку с мармеладом, в которой есть несколько слишком твердых или слишком сухих кусочков. Если бы я просмотрел коробку и классифицировал каждую деталь как «хорошо» или «плохо», это были бы двоичные данные. Я мог бы использовать такие данные для разработки статистической модели, чтобы предсказать, как часто я могу ожидать получать плохой мармелад.
При сборе данных неупорядоченных или номинальных мы относим отдельные элементы к именованным категориям, которые не имеют неявного или естественного значения или ранга. Если бы я просмотрел коробку с мармеладом и записал цвет каждого из них на своем листе, это были бы номинальные данные.
Данные такого типа можно использовать по-разному — например, я мог бы использовать анализ хи-квадрат, чтобы увидеть, есть ли статистически значимые различия в количестве каждого цвета в блоке.
У нас также может быть упорядоченных или порядковых данных , в которых элементы назначаются категориям, которые имеют какой-то неявный или естественный порядок, например «Короткий, Средний или Высокий». Другой пример — вопрос опроса, в котором нам предлагается оценить элемент по шкале от 1 до 10, где 10 — лучший результат. Это означает, что 10 лучше, чем 9, что лучше, чем 8, и так далее.
Использование упорядоченных данных является предметом споров среди статистиков.Все согласны с тем, что это подходит для создания гистограмм, но помимо этого ответ на вопрос «Что мне делать с моими порядковыми данными?» «Это зависит от обстоятельств». Вот сообщение из другого блога, которое предлагает отличное резюме затронутых соображений.
Дополнительные ресурсы о данных и распределениях
Чтобы узнать больше о статистике, которую вы можете сделать с конфетами, ознакомьтесь с этой статьей (в формате PDF): Статистические концепции: чему нас могут научить M&M.
Для более глубокого изучения распределений вероятностей, применимых к различным типам данных, ознакомьтесь с сообщениями моего коллеги Джима Фроста о понимании и использовании дискретных распределений и о том, как определить распределение ваших данных.
Понимание различных типов переменных в статистике
Во всех экспериментах исследуются какие-то переменные. Переменная — это не только то, что мы измеряем, но также то, чем мы можем манипулировать и что мы можем контролировать. Чтобы понять характеристики переменных и то, как мы используем их в исследованиях, это руководство разделено на три основных раздела. Во-первых, мы проиллюстрируем роль зависимых и независимых переменных. Во-вторых, мы обсуждаем разницу между экспериментальным и неэкспериментальным исследованием.Наконец, мы объясняем, как переменные можно охарактеризовать как категориальные или непрерывные.
Зависимые и независимые переменные
Независимая переменная , иногда называемая экспериментальной переменной или предиктором , представляет собой переменную, которой манипулируют в эксперименте, чтобы наблюдать влияние на зависимую переменную , иногда называемую переменной результата .
Представьте, что репетитор просит 100 учеников пройти тест по математике.Репетитор хочет знать, почему одни ученики успевают лучше, чем другие. Хотя репетитор не знает ответа на этот вопрос, она думает, что это может быть по двум причинам: (1) некоторые ученики тратят больше времени на корректировку своего теста; и (2) некоторые студенты от природы более умны, чем другие. Таким образом, наставник решает изучить влияние времени проверки и интеллекта на результаты теста 100 студентов. Зависимые и независимые переменные для исследования:
Зависимая переменная: Тестовая отметка (измеряется от 0 до 100)
независимых переменных: Время пересмотра (измеряется в часах) Интеллект (измеряется с использованием показателя IQ)
Зависимая переменная — это просто переменная, которая зависит от независимых переменных.Например, в нашем случае тестовая отметка, которую получает студент, зависит от времени проверки и интеллекта. Хотя время проверки и интеллект (независимые переменные) могут (или не могут) вызвать изменение тестовой отметки (зависимая переменная), обратное утверждение маловероятно; Другими словами, хотя количество часов, которые студент тратит на повторение, и более высокий показатель IQ студента может (или не может) изменить контрольную отметку, которую получает студент, изменение контрольной отметки студента не влияет на то, исправляет ли студент более или более умный (это просто не имеет смысла).
Таким образом, цель исследования преподавателя состоит в том, чтобы проверить, приводят ли эти независимые переменные — время проверки и IQ — к изменению зависимой переменной, результатов тестов студентов. Тем не менее, стоит также отметить, что, хотя это основная цель эксперимента, преподавателю также может быть интересно узнать, связаны ли каким-либо образом независимые переменные — время проверки и IQ.
В следующем разделе, посвященном экспериментальным и неэкспериментальным исследованиям, мы узнаем немного больше о природе независимых и зависимых переменных.
Парный выборочный T-тест — статистические решения
Уровень измерения
Для парной выборки t -тест требует, чтобы данные выборки были числовыми и непрерывными, поскольку они основаны на нормальном распределении. Непрерывные данные могут принимать любое значение в пределах диапазона (доход, рост, вес и т. Д.). Противоположностью непрерывным данным являются дискретные данные, которые могут принимать только несколько значений (низкие, средние, высокие и т. Д.). Иногда дискретные данные могут использоваться для аппроксимации непрерывной шкалы, например, шкалы Лайкерта.
Независимость
Независимость наблюдений обычно не поддается проверке, но ее можно разумно предположить, если процесс сбора данных был случайным без замены. В нашем примере разумно предположить, что участвующие сотрудники независимы друг от друга.
Нормальность
Для проверки предположения о нормальности доступно множество методов, но самый простой — визуально проверить данные с помощью такого инструмента, как гистограмма (рис. 1). Реальные данные почти никогда не бывают совершенно нормальными, поэтому это предположение можно считать разумно выполненным, если форма выглядит приблизительно симметричной и колоколообразной.Данные на приведенном ниже примере распределены приблизительно нормально.
Рис. 1. Гистограмма приблизительно нормально распределенной переменной.Выбросы
Выбросы — это редкие значения, которые появляются далеко от большинства данных. Выбросы могут исказить результаты и потенциально привести к неверным выводам, если их не обработать должным образом. Один из методов борьбы с выбросами — просто удалить их. Однако удаление точек данных может привести к другим типам смещения результатов и потенциально привести к потере важной информации.Если кажется, что выбросы имеют большое влияние на результаты, вместо этого можно использовать непараметрический критерий, такой как знаковый ранговый критерий Уилкоксона. Выбросы можно определить визуально, используя коробчатую диаграмму (рис. {th} \) в \ (D \)
определить, предоставляют ли результаты достаточно доказательств, чтобы отклонить нулевую гипотезу в пользу альтернативной гипотезы.
При интерпретации результатов парной выборки t -тест следует учитывать два типа значимости: статистическая значимость и практическая значимость.
Статистическая значимость
Статистическая значимость определяется по значению p . Значение p дает вероятность наблюдения результатов теста при нулевой гипотезе. Чем ниже значение p , тем ниже вероятность получения результата, подобного тому, который наблюдался, если бы нулевая гипотеза была верна. Таким образом, низкое значение p указывает на снижение поддержки нулевой гипотезы. Однако возможность того, что нулевая гипотеза верна и что мы просто получили очень редкий результат, никогда не может быть полностью исключена.Значение отсечения для определения статистической значимости в конечном итоге определяется исследователем, но обычно выбирается значение 0,05 или меньше. Это соответствует 5% (или меньше) вероятности получения результата, подобного тому, который наблюдался, если бы нулевая гипотеза была верна.
Практическое значение
Практическое значение зависит от предмета. Нередко, особенно при больших размерах выборки, наблюдается статистически значимый, но не практически значимый результат.В большинстве случаев для того, чтобы сделать значимые выводы, требуются оба типа значимости.
Statistics Solutions может помочь с количественным анализом, помогая разработать методологию и главы с результатами. Услуги, которые мы предлагаем, включают:
План анализа данных
Измените свои исследовательские вопросы и нулевые / альтернативные гипотезы
Напишите план анализа данных; указать конкретную статистику для ответа на вопросы исследования, допущения статистики и обосновать, почему они являются подходящей статистикой; предоставить ссылки
Обоснуйте размер вашей выборки / анализ мощности, предоставьте ссылки
Объясните вам план анализа данных, чтобы вы чувствовали себя комфортно и уверенно.
Два часа дополнительной поддержки у вашего статистика
Раздел количественных результатов (описательная статистика, двумерный и многомерный анализ, моделирование структурных уравнений, анализ траектории, HLM, кластерный анализ)
Чистый и кодовый набор данных
Проведение описательной статистики (т.е., среднее значение, стандартное отклонение, частота и процент, в зависимости от случая)
Проведите анализ для изучения каждого из вопросов вашего исследования
Результаты повторной записи
Предоставьте APA 6 th , таблицы и рисунки
Объяснение выводов по главе 4
Постоянная поддержка всей статистики по главам результатов
Пожалуйста, позвоните по номеру 727-442-4290, чтобы запросить расценки на основе специфики вашего исследования, расписания с использованием календаря на его странице или по электронной почте [электронная почта защищена]
.