
Распределение пуассона формула: Математическое Бюро. Страница 404
Распределения Пуассона. Решение задач
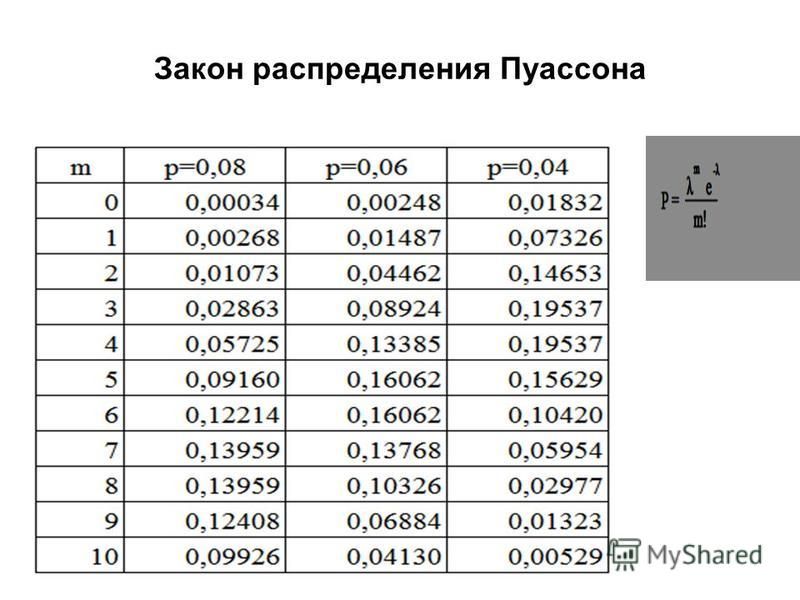
Дискретная случайная величина Х имеет закон распределения Пуассона, если вероятности ее возможных значений
вычисляется по формуле Пуассона, где a=np<10. Как правило, Пуассоновское распределение касается вероятности появления благоприятного события в большом количестве экспериментов, если в одном — вероятность успешного завершения стремится к нулю.
В табличной форме этот закон распределения имеет вид
Условие нормировки для пуассоновского закона распределения запишется следующим образом
Построим образующую функцию вероятностей для приведенного закона
Она принимает достаточно простой компактный вид
Воспользовавшись зависимостями для определения математического ожидания М (Х) и дисперсии D (X) через производные от образующей функции в единице, получим их простые зависимости
1. Математическое ожидание определяется по формуле
2. Имея вторую производную от образующей функции в единице
находят дисперсию
Среднее квадратическое отклонение вычисляем через квадратный корень из дисперсии
Следовательно, для пуассоновского закона распределения вероятностей математическое ожидание и дисперсия равны произведению количества опытов на вероятность благоприятной события
На практике, если математическое ожидание и дисперсия близкие по значению то принимают гипотезу, что исследуемая величина имеет закон распределения Пуассона.
3. Асимметрия и эксцесс для пуассоновский закон также уровни и вычисляются по формулам
Рассмотрим несколько задач.
—————————————-
Задача 1. Микропроцессор имеет 10000 ранзисторов, работающих независимо друг от друга. Вероятность того, что транзистор выйдет из строя во время работы прибора, является величиной маловероятной и составляет 0,0007. Определить математическое ожидание М (Х) и среднее квадратическое отклонение S (Х) случайной величины Х — исла транзисторов, выйдут из строя во время работы процессора.
Решение. Задача удовлетворяет всем законам пуассоновский распределения:
количество испытаний n=10000 велика;
вероятность р=0,0007 близка к нулю;
их произведение a=np=7<10.
На основе данных вычисляем заданные величины
————————————
Задача 2. В рыбацком городке 99,99% мужчин хотя бы раз в жизни были на рыбалке. Проводят социологические исследования среди 10000 наугад выбранных мужчин. Определить дисперсию D (X) и среднее квадратическое отклонени S (Х) случайной величины Х — числа мужчин, которые ни разу не были на рыбалке.
Определить дисперсию D (X) и среднее квадратическое отклонени S (Х) случайной величины Х — числа мужчин, которые ни разу не были на рыбалке.
Решение. егко убедиться, что величина Х имеет пуассоновский закон распределения. С условия задачи находим
По формулам находим дисперсию и среднее квадратическое отклонение
Можно найти в гугле еще много подобных задач, всех их объединяет изменение случайной величины по закону Пуассона. Схема нахождения числовых характеристик приведена выше и является общей для всех задач, кроме того формулы для вычислений достаточно простыми даже для школьников.
Распределение Пуассона
Ранее мы рассмотрели два типа дискретных числовых распределений: биномиальное и гипергеометрическое. Во многих практически важных приложениях большую роль играет распределение Пуассона. Многие из числовых дискретных величин являются реализациями пуассоновского процесса, обладающего следующими свойствами:[1]
- Нас интересует, сколько раз происходит некое событие в заданной области возможных исходов случайного эксперимента.
 Область возможных исходов может представлять собой интервал времени, отрезок, поверхность и т.п.
Область возможных исходов может представлять собой интервал времени, отрезок, поверхность и т.п. - Вероятность данного события одинакова для всех областей возможных исходов.
- Количество событий, происходящих в одной области возможных исходов, не зависит от количества событий, происходящих в других областях.
- Вероятность того, что в одной и той же области возможных исходов данное событие происходит больше одного раза, стремится к нулю по мере уменьшения области возможных исходов.
 Область возможных исходов может представлять собой интервал времени, отрезок, поверхность и т.п.
Область возможных исходов может представлять собой интервал времени, отрезок, поверхность и т.п.Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Чтобы глубже понять смысл пуассоновского процесса, предположим, что мы исследуем количество клиентов, посещающих отделение банка, расположенное в центральном деловом районе, во время ланча, т.е. с 12 до 13 часов. Предположим, требуется определить количество клиентов, приходящих за одну минуту. Обладает ли эта ситуация особенностями, перечисленными выше? Во-первых, событие, которое нас интересует, представляет собой приход клиента, а область возможных исходов — одноминутный интервал.
Распределение Пуассона имеет один параметр, обозначаемый символом λ (греческая буква «лямбда») – среднее количество успешных испытаний в заданной области возможных исходов. Дисперсия распределения Пуассона также равна λ, а его стандартное отклонение равно . Количество успешных испытаний 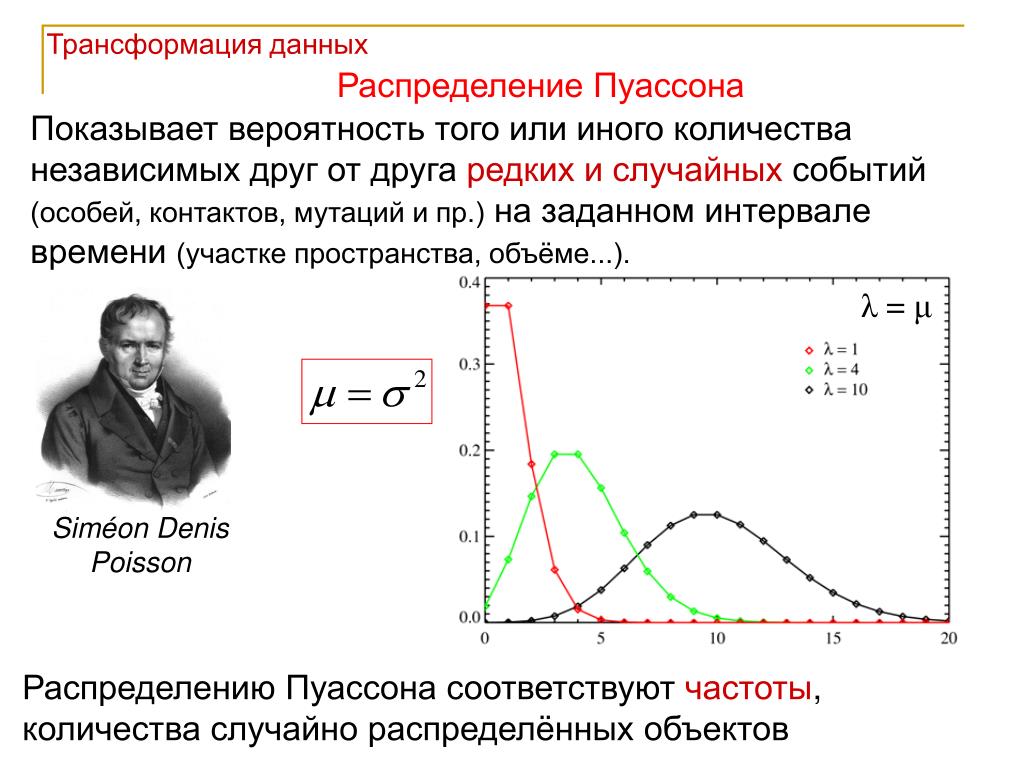 Распределение Пуассона описывается формулой:
Распределение Пуассона описывается формулой:
где Р(Х) — вероятность X успешных испытаний, λ — ожидаемое количество успехов, е— основание натурального логарифма, равное 2,71828, X— количество успехов в единицу времени.
Вернемся к нашему примеру. Допустим, что в течение обеденного перерыва в среднем в банк приходят три клиента в минуту. Какова вероятность того, что в данную минуту в банк придут два клиента? А чему равна вероятность того, что в банк придут более двух клиентов?
Применим формулу (1) с параметром λ = 3. Тогда вероятность того, что в течение данной минуты в банк придут два клиента, равна
Вероятность того, что в банк придут более двух клиентов, равна Р(Х > 2) = Р(Х = 3) + Р(Х = 4) + … + Р(Х = ∞) . Поскольку сумма всех вероятностей должна быть равной 1, члены ряда, стоящего в правой части формулы, представляют собой вероятность дополнения к событию Х≤ 2. Иначе говоря, сумма этого ряда равна 1 – Р(Х ≤ 2).
Таким образом, вероятность того, что в банк в течение минуты придут не больше двух клиентов, равна 0,423 (или 42,3%), а вероятность того, что в банк в течение минуты придут больше двух клиентов, равна 0,577 (или 57,7%).
Такие вычисления могут показаться утомительными, особенно если параметр λ достаточно велик. Чтобы избежать сложных вычислений, многие пуассоновские вероятности можно найти в специальных таблицах (рис. 1). Например, вероятность того, что в заданную минуту в банк придут два клиента, если в среднем в банк приходят три клиента в минуту, находится на пересечении строки
Рис. 1. Пуассоновская вероятность при λ = 3
Сейчас вряд ли кто-то будет пользоваться таблицами, если под рукой есть Excel с его функцией =ПУАССОН.РАСП() (рис. 2). Эта функция имеет три параметра: число успешных испытаний Х, среднее ожидаемое количество успешных испытаний λ, параметр Интегральная, принимающий два значения: ЛОЖЬ – в этом случае вычисляется вероятность числа успешных испытаний Х (только Х), ИСТИНА – в этом случае вычисляется вероятность числа успешных испытаний от 0 до Х.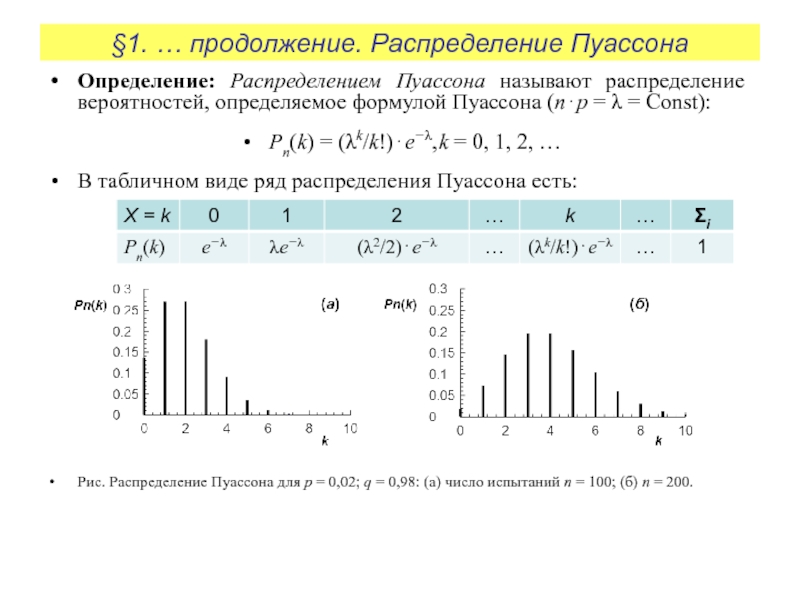
Рис. 2. Расчет в Excel вероятностей распределения Пуассона при λ = 3
Аппроксимация биноминального распределения с помощью распределения Пуассона
Если число n велико, а число р — мало, биномиальное распределение можно аппроксимировать с помощью распределения Пуассона. Чем больше число n и меньше число р, тем выше точность аппроксимации. Для аппроксимации биномиального распределения используется следующая модель Пуассона.
где Р(Х) — вероятность X успехов при заданных параметрах n и р, n — объем выборки,
Теоретически случайная величина, имеющая распределение Пуассона, принимает значения от 0 до ∞. Однако в тех ситуациях, когда распределение Пуассона применяется для приближения биномиального распределения, пуассоновская случайная величина — количество успехов среди n наблюдений — не может превышать число n. Из формулы (2) следует, что с увеличением числа n и уменьшением числа р вероятность обнаружить большое количество успехов уменьшается и стремится к нулю.
Из формулы (2) следует, что с увеличением числа n и уменьшением числа р вероятность обнаружить большое количество успехов уменьшается и стремится к нулю.
Как говорилось выше, математическое ожидание µ и дисперсия σ2 распределения Пуассона равны λ. Следовательно, при аппроксимации биномиального распределения с помощью распределения Пуассона для приближения математического ожидания следует применять формулу (3).
(3) µ = Е(Х) = λ = np
Для аппроксимации стандартного отклонения используется формула (4).
Обратите внимание на то, что стандартное отклонение, вычисленное по формуле (4), стремится к стандартному отклонению в биномиальной модели – , когда вероятность успеха p стремится к нулю, и, соответственно, вероятность неудачи
Предположим, что 8% шин, произведенных на некотором заводе, являются бракованными. Чтобы проиллюстрировать применение распределения Пуассона для аппроксимации биномиального распределения, вычислим вероятность обнаружить одну дефектную шину в выборке, состоящей из 20 шин. Применим формулу (2), получим
Применим формулу (2), получим
Если бы мы вычислили истинное биномиальное распределение, а не его приближение, то получили бы следующий результат:
Однако эти вычисления довольно утомительны. В то же время, если вы используете Excel для вычисления вероятностей, то применение аппроксимации в виде распределения Пуассона становится излишним. На рис. 3 показано, что трудоемкость вычислений в Excel одинакова. Тем не менее, этот раздел, на мой взгляд, полезен понимаем того, что при некоторых условиях биноминальное распределение и распределение Пуассона дают близкие результаты.
Рис. 3. Сравнение трудоемкости расчетов в Excel: (а) распределение Пуассона; (б) биноминальное распределение
Итак, в настоящей и двух предыдущих заметках были рассмотрены три дискретных числовых распределения: биномиальное, гипергеометрическое и Пуассона. Чтобы лучше представлять, как эти распределения соотносятся друг с другом приведем небольшое дерево вопросов (рис.
Рис. 4. Классификация дискретных распределений вероятностей
Предыдущая заметка Гипергеометрическое распределение
Следующая заметка Нормальное распределение
К оглавлению Статистика для менеджеров с использованием Microsoft Excel
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 320–328
Что такое распределение Пуассона? | by Iuliia Averianova | NOP::Nuances of Programming
a) Биномиальная случайная величина бинарна — 0 или 1.
В примере выше у нас было 17 лайков в неделю. Это 17/7 = 2.4 человека в день и 17/(7*24) = 0.1 в час.
Если моделировать вероятность успеха в часах (0.1 человек в час), используя биномиальную случайную величину, получим, что в большем количестве часов лайков будет 0, а в некоторые часы ровно 1 лайк. Также возможно, что в час будет больше 1 лайка (2, 3, 5 и т. д.).
д.).
Проблема с биномиальным распределением в том, что оно не может содержать более одного события в единицу времени (1 час в примере).
Так может разделить 1 час на 60 минут и принять за единицу времени минуту? Тогда в 1 час поместится несколько событий. (Помним, что 1 минута содержит только ноль или одно событие).
Теперь проблема решена?
Вроде бы. Но что если в течение одной минуты мы получим несколько лайков? (например, кто-то поделился постом в Твиттере, и трафик вырос в эту минуту). Что тогда? Можно разделить минуту на секунды. Тогда единицей времени становится секунда, и в минуту помещается несколько событий. Но проблема бинарного контейнера будет существовать для все меньших единиц времени.
Дело в том, что биномиальная случайная величина может содержать несколько событий, если делить единицу времени на все меньшие единицы. В результате изначальная единица времени будет содержать более одного события.
Математически это означает n → ∞. Если предположим, что среднее значение фиксировано, тогда p → 0. В противном случае n*p — количество событий — чрезмерно возрастет.
Единица времени с использованием этого лимита может быть бесконечно мала. Больше не нужно беспокоиться о более чем одном событии в единицу времени. Так получается распределение Пуассона.
b) В биномиальном распределении количество попыток (n) должно быть известно заранее.
Нельзя посчитать вероятность успеха при помощи биномиального распределения, зная только среднее значение (17 человек в неделю). Нужно больше информации (n и p), чтобы использовать формулу.
Распределение Пуассона же не обязывает вас знать ни n ни p. Предположим, что n бесконечно велико, а p бесконечно мала. Единственный параметр распределения — значение λ (ожидаемое значение x). В реальной жизни чаще известно только значение (например, с 2 до 4 часов дня я принял 3 телефонных звонка), а не значения n и p.
В реальной жизни чаще известно только значение (например, с 2 до 4 часов дня я принял 3 телефонных звонка), а не значения n и p.
Функция ПУАССОН — Служба поддержки Office
Возвращает распределение Пуассона. Обычное применение распределения Пуассона состоит в предсказании количества событий, происходящих за определенное время, например количества машин, появляющихся на площади за одну минуту.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция ПУАССОН.РАСП.
в статье Функция ПУАССОН.РАСП.
Синтаксис
ПУАССОН(x;среднее;интегральная)
Аргументы функции ПУАССОН описаны ниже.
-
X Обязательный. Количество событий.
-
Среднее Обязательный. Ожидаемое числовое значение.
-
Интегральная — обязательный аргумент. Логическое значение, определя которое определяет форму возвращаемого распределения вероятности. Если значение «совокупное» имеет значение ИСТИНА, то пуассон возвращает совокупное значение вероятности того, что количество случайных событий будет включительно в период от нуля до x.
Если этот массив ложно, возвращается функция массовой вероятности Пуассона, которая возвращает точное количество произошедших событий x.
 Если этот массив ложно, возвращается функция массовой вероятности Пуассона, которая возвращает точное количество произошедших событий x.
Если этот массив ложно, возвращается функция массовой вероятности Пуассона, которая возвращает точное количество произошедших событий x.Замечания
-
Если x не является целым числом, оно усекается.
-
Если x или простое число не является числом, то пуассон возвращает #VALUE! значение ошибки #ЗНАЧ!.
-
Если x < 0, то пуассон возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если вы < 0, то пуассон возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Функция ПУАССОН вычисляется следующим образом.
Если интегральная = ЛОЖЬ:
Если интегральная = ИСТИНА:
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Данные | Описание | |
|---|---|---|
|
2 |
Число событий |
|
|
5 |
Ожидаемое среднее |
|
|
Формула |
Описание (результат) |
Результат |
|
=ПУАССОН(A2;A3;ИСТИНА) |
Интегральное распределение Пуассона для приведенных выше условий (0,124652) |
0,124652 |
|
=ПУАССОН(A2;A3;ЛОЖЬ) |
Функция плотности распределения Пуассона для приведенных выше условий (0,084224) |
0,084224 |
Распределение Пуассона
Дискретная случайная величина имеет распределение Пуассона с параметром λ, если:
Распределение Пуассона также называется распределением редких событий.
Распределение Пуассона — это дискретное распределение, являющееся одним из важных предельных случаев биномиального распределения.
Это одно из важнейших дискретных вероятностных распределений впервые было исследовано в 1837 г. С.Пуассоном (французский математик, механик и физик, 1781 – 1840 гг.), именем которого оно и называется.
Пуассоновская модель П() обычно описывает схему редких событий: при некоторых предположениях о характере процесса появления случайных событий число событий, происшедших за фиксированный промежуток времени или в фиксированной области пространства, часто подчиняется пуассоновскому распределению.
Примерами могут служить число частиц радиоактивного распада, зарегистрированных счетчиком в течении некоторого времени t, число вызовов, поступивших на телефонную станцию за время t, число дефектов в куске ткани или в ленте фиксированной длины, число изюминок в кексе и т.д.
Наконец, распределение Пуассона дает хорошую аппроксимацию биномиального распределения для больших значений n и малых значений р: Bi(n, p) П(np), если np не велико. Это свойство позволяет значительно упростить вычисления в биномиальной модели при указанных условиях.
Это свойство позволяет значительно упростить вычисления в биномиальной модели при указанных условиях.
Распределение Пуассона моделирует случайную величину, представляющую собой число событий, произошедших за фиксированное время, при условии, что данные события происходят с некоторой фиксированной средней интенсивностью и независимо друг от друга.
Это распределение интенсивно используется в картах контроля качества, теории массового обслуживания, телекоммуникации, медицинской статистике и т. д.
При росте n, малом р и фиксированном значении произведения np=λ > 0 биномиальное распределение сходится к распределению Пуассона.
Связанные определения:
Распределение Пуассона
В начало
Содержание портала
Распределение Пуассона – краткая теория и задачи
Случайная величина , распределённая по этому закону, принимает бесконечное и счётное количество значений , вероятности появления которых определяются формулой:
Или, если расписать подробно:
Вспоминая разложение экспоненты в ряд,
легко убедиться, что:
Математическое ожидание пуассоновской случайной величины равно и дисперсия – тому же самому значению: .
Во всех задачах параграфа Формула Пуассона мы лишь ПОЛЬЗОВАЛИСЬ распределением Пуассона для
приближенного расчёта вероятностей, в то время как ТОЧНЫЕ значения следовало находить по формуле Бернулли, т.е., там имело место биномиальное распределение. И
последующие задачи отличаются принципиально –
– отличие состоит в том, что сейчас речь идёт именно о РАСПРЕДЕЛЕНИИ Пуассона:
Задача 99
Случайная величина подчинена закону Пуассона с математическим ожиданием,
равным . Найти
вероятность того, что данная случайная величина примет значение, меньшее, чем её математическое
ожидание.
Решение: известно, что математическое ожидание распределения Пуассона в точности равно , таким образом, случайная величина принимает значения с вероятностями:
Интересующее нас событие состоит в трёх несовместных исходах: случайная величина примет значение или , или . По теореме сложения вероятностей несовместных событий:
По теореме сложения вероятностей несовместных событий:
– вероятность
того, что случайная величина примет значение, меньшее, чем ее математическое
ожидание.
Ответ:
Аналогичная задача на понимание:
Задача 100
Случайная величина подчинена закону Пуассона с единичным математическим
ожиданием. Найти вероятность того, что данная случайная величина примет положительное значение.
Решение и ответ в конце книги.
Помимо прочего, распределение Пуассона нашло широкое применение в теории массового обслуживания для вероятностной характеристики простейшего потока событий. Постараюсь быть лаконичным:
Пусть в некоторую систему поступают заявки (телефонные звонки, приходящие клиенты и т.д.). Поток заявок называют
простейшим, если он удовлетворяет условиям стационарности, отсутствия последствий и ординарности.
Стационарность подразумевает то, что интенсивность заявок постоянна и не зависит от времени суток, дня недели или других
временнЫх рамок. Иными словами, не бывает «часа пик» и не бывает «мёртвых часов». Отсутствие последствий означает, что
вероятность появления новых заявок не зависит от «предыстории», т.е. нет такого, что «одна бабка рассказала» и другие «набежали» (или
наоборот, разбежались). И, наконец, свойство ординарности характеризуется тем, что за достаточно малый промежуток времени
практически невероятно появление двух или бОльшего количества заявок. «Две старушки в
дверь?» – нет уж, увольте, рубить удобнее по порядку.
Итак, пусть в некоторую систему поступает простейший поток заявок со средней интенсивностью заявок в некоторую единицу времени (минуту,
час, день или в любой другой). Тогда вероятность того, что за данный промежуток времени, в систему поступит ровно заявок, равна:
Поразительно, с какой скоростью устаревают задачи:
Задача 101
Звонки в диспетчерскую такси представляет собой простейший пуассоновский поток со средней интенсивностью 30 вызовов в час. Найти
вероятность того, что: а) за 1 мин. поступит 2-3 вызова, б) в течение пяти минут будет хотя бы один звонок.
Найти
вероятность того, что: а) за 1 мин. поступит 2-3 вызова, б) в течение пяти минут будет хотя бы один звонок.
Решение: используем формулу Пуассона:
а) Учитывая стационарность потока, вычислим среднее количество вызовов за 1 минуту:
вызова – в среднем
за одну минуту.
По теореме сложения вероятностей несовместных событий:
– вероятность
того, что за 1 минуту в диспетчерскую поступит 2-3 вызова.
б) Вычислим среднее количество вызов за пять минут:
По формуле Пуассона:
– вероятность
того, что в течение 5 минут не будет ни одного звонка.
По теореме сложения вероятностей противоположных событий:
–
вероятность того, что в течение 5 минут будет хотя бы один вызов.
Ответ: а) , б)
Обращаю внимание, что в отличие от задач параграфа Формула Пуассона, эту задачу уже нельзя
решить по формуле Бернулли. По той причине, что заранее не известно общее количество исходов (точное количество звонков в тот или иной
час).
По той причине, что заранее не известно общее количество исходов (точное количество звонков в тот или иной
час).
И предсказать это значение, разумеется, невозможно.
Для самостоятельного решения:
Задача 102
Среднее число автомобилей, проходящих таможенный досмотр в течение часа, равно 3. Найти вероятность того, что: а) за 2 часа пройдут
досмотр от 7 до 10 автомобилей; б) за пол часа успеет пройти досмотр только 1 автомобиль.
Таможня пройдена, достаём припрятанное:
2.3.4. Гипергеометрическое распределение вероятностей
2.3.2. Биномиальное распределение вероятностей
| Оглавление |
Полную и свежую версию этой книги в pdf-формате,
а также курсы по другим темам можно найти здесь.
Также вы можете изучить эту тему подробнее – просто, доступно, весело и бесплатно!
С наилучшими пожеланиями, Александр Емелин
Что такое распределение Пуассона?
Прежде чем вводить параметр λ и подставлять его в формулу, давайте задумаемся: почему Пуассону вообще пришлось изобретать такое распределение?
1.
 Почему Пуассон изобрел свое распределение?
Почему Пуассон изобрел свое распределение?Чтобы предсказывать количествобудущихсобытий!
Или более формально: чтобы предсказывать вероятность данного числа событий, происходящих в определенный интервал времени.
В продажах, например, “событие” это покупка (сам момент покупки, не просто выбор). Событием может быть количество посетителей в день на веб-сайте, кликов на рекламном объявлении в следующем месяце, число звонков в рабочее время или число людей, которые умрут от смертельных заболеваний в следующем году, и так далее.
Вот пример, как я использую распределение Пуассона в реальной жизни.
Каждую неделю в среднем 17 человек оставляют лайк под моим постом в блоге.
Я хочу предсказать количество лайков на следующей неделе, потому что мои еженедельные выплаты зависят от этого количества.
Какова вероятность того, что точно 20 человек (или 10, 30, 50 и так далее) поставят лайк под моим постом на следующей неделе? 2.
 Как решить эту задачу?
Как решить эту задачу?Давайте на время сделаем вид, что мы ничего не знаем о распределении Пуассона. Как тогда решить задачу?
Первый путь: начать с количества прочтений. Для каждого читателя блога есть вероятность, что статья ему действительно понравится и он поставит лайк.
Это классическая работа для биномиального распределения, так как мы рассчитываем количество успешных событий (лайков).
Биномиальная случайная величина — это количество успешных x в n повторяющихся попыток. Предполагается, что вероятность успеха p является постоянной в каждой попытке.
Итак, у нас есть только один параметр — 17 человек в неделю, что является “средним значением” (средним значением успешных событий в неделею, или математическим ожиданием x). Нам ничего не известно ни о вероятности получения лайков p, ни о количестве посетителей блога n.
Значит, нам нужно больше информации для решения задачи. Что конкретно нужно, чтобы оформить эту вероятность как биномиальную проблему? Две вещи: вероятность успеха (лайков) p и количество попыток (посетителей) n.
Получим их из прошлых данных.
Это статистика за 1 год. Общее количество читателей блога — 59 тысяч, 888 из них поставили лайк.
Следовательно, количество читателей в неделю (n): 59 000/52 = 1134. Количество поставивших лайк в неделю (x): 888/52 =17.
количество читателей в неделю (n) = 59000/52 = 1134
количество оставивших лайк в неделю (x) = 888/52 = 17
вероятность успеха (p) : 888/59000 = 0.015 = 1.5%Используя биномиальную функцию вероятности, посчитаем вероятность того, что я получу точно 20 успешных событий (20 лайков) на следующей неделе.
<Биномиальная вероятность для различных x>
╔══════╦═══════════════════╗
║ x ║ Binomial P(X=x) ║
╠══════╬═══════════════════╣
║ 10 ║ 0. 02250 ║
║ 17 ║ 0.09701 ║ ? P выше у среднего показателя!
║ 20 ║ 0.06962 ║ ? Неплохо. 20 тоже вполне вероятно!
║ 30 ║ 0.00121 ║
║ 40 ║ < 0.000001 ║ ? Не думаю, что получу 40 лайков...
╚══════╩═══════════════════╝ 02250 ║
║ 17 ║ 0.09701 ║ ? P выше у среднего показателя!
║ 20 ║ 0.06962 ║ ? Неплохо. 20 тоже вполне вероятно!
║ 30 ║ 0.00121 ║
║ 40 ║ < 0.000001 ║ ? Не думаю, что получу 40 лайков...
╚══════╩═══════════════════╝
02250 ║
║ 17 ║ 0.09701 ║ ? P выше у среднего показателя!
║ 20 ║ 0.06962 ║ ? Неплохо. 20 тоже вполне вероятно!
║ 30 ║ 0.00121 ║
║ 40 ║ < 0.000001 ║ ? Не думаю, что получу 40 лайков...
╚══════╩═══════════════════╝Только что мы решили задачу с помощью биномиального распределения.
Тогда зачем нам распределение Пуассона? Что оно может делать такого, что не может биномиальное распределение?
3. Недостатки биномиального распределения
a) Биномиальная случайная величина бинарна — 0 или 1.
В примере выше у нас было 17 лайков в неделю. Это 17/7 = 2.4 человека в день и 17/(7*24) = 0.1 в час.
Если моделировать вероятность успеха в часах (0.1 человек в час), используя биномиальную случайную величину, получим, что в большем количестве часов лайков будет 0, а в некоторые часы ровно 1 лайк. Также возможно, что в час будет больше 1 лайка (2, 3, 5 и т.д.).
Также возможно, что в час будет больше 1 лайка (2, 3, 5 и т.д.).
Проблема с биномиальным распределением в том, что оно не может содержать более одного события в единицу времени (1 час в примере).
Так может разделить 1 час на 60 минут и принять за единицу времени минуту? Тогда в 1 час поместится несколько событий. (Помним, что 1 минута содержит только ноль или одно событие).
Теперь проблема решена?
Вроде бы. Но что если в течение одной минуты мы получим несколько лайков? (например, кто-то поделился постом в Твиттере, и трафик вырос в эту минуту). Что тогда? Можно разделить минуту на секунды. Тогда единицей времени становится секунда, и в минуту помещается несколько событий. Но проблема бинарного контейнера будет существовать для все меньших единиц времени.
Дело в том, что биномиальная случайная величина может содержать несколько событий, если делить единицу времени на все меньшие единицы. В результате изначальная единица времени будет содержать более одного события.
Математически это означает n → ∞. Если предположим, что среднее значение фиксировано, тогда p → 0. В противном случае n*p — количество событий — чрезмерно возрастет.
Единица времени с использованием этого лимита может быть бесконечно мала. Больше не нужно беспокоиться о более чем одном событии в единицу времени. Так получается распределение Пуассона.
b) В биномиальном распределении количество попыток (n) должно быть известно заранее.
Нельзя посчитать вероятность успеха при помощи биномиального распределения, зная только среднее значение (17 человек в неделю). Нужно больше информации (n и p), чтобы использовать формулу.
Распределение Пуассона же не обязывает вас знать ни n ни p. Предположим, что n бесконечно велико, а p бесконечно мала. Единственный параметр распределения — значение λ (ожидаемое значение x). k) дает1, когда n стремится к бесконечности.
k) дает1, когда n стремится к бесконечности.
Это 1.
Мы получили формулу Пуассона!
Теперь понятнее:
Введите ваши данные в формулу и проверьте даст ли P(x) необходимый результат!
Ниже мой:
< Сравнение биномиального распределения и распределения Пуассона > ╔══════╦═══════════════════╦═══════════════════════╗
║ k ║ Binomial P(X=k) ║ Poisson P(X=k;λ=17) ║
╠══════╬═══════════════════╬═══════════════════════╣
║ 10 ║ 0.02250 ║ 0.02300 ║
║ 17 ║ 0.09701 ║ 0.09628 ║
║ 20 ║ 0.06962 ║ 0.07595 ║
║ 30 ║ 0.00121 ║ 0.00340 ║
║ 40 ║ < 0.000001 ║ < 0.000001 ║
╚══════╩═══════════════════╩═══════════════════════╝
* Оба можно легко посчитать здесь:
Биномиальное: https://stattrek.com/online-calculator/binomial.aspx
Пуассона: https://stattrek.com/online-calculator/poisson. aspx aspx
aspxНесколько замечаний:
- Несмотря на то, что распределение Пуассона моделирует редкие события, значение λ может быть любым, оно не обязательно всегда должно быть маленьким.
- Распределение Пуассона асимметрично — оно всегда смещено вправо, потому что слева его ограничивает нулевой барьер (не существует такой вещи как “минус один” лайк), а справа ограничений нет.
- Чем больше становится значение λ, тем ближе график к графику нормального распределения.
4. Ограничения распределения Пуассона:
a. Среднее значение событий в единицу времени постоянно.
Что это значит? Количество людей, посещающих блог в час может не следовать распределению Пуассона, потому что значение посещений в час не является постоянным (‘значение n выше днем, ниже вечером). Использование значения за месяц для потребительских или биологических данных тоже будет лишь приблизительным, потому что сезонный эффект в этой области не предсказуем.
b. События независимы.
Появление посетителей не всегда независимо. Например, посетители могут прийти группой, потому что кто-то популярный упомянул вас в своем блоге, или ваш блог оказался на первой странице сайта. Количество землетрясений в год в стране также может не соответствовать распределению Пуассона, если одно сильное землетрясение увеличивает вероятность последующих толчков.
5. Соотношение между распределением Пуассона и экспоненциальным распределением.
Если количество событий в единицу времени соответствует распределению Пуассона, тогда период времени между событиями соответствует экспоненциальному распределению. Распределение Пуассона дискретно, а экспоненциальное непрерывно, но они тесно связаны.
Читайте также:
Перевод статьи Aerin Kim: What is Poisson Distribution?
Распределение Пуассона / Кривая Пуассона: простое определение
Распределения вероятностей>
Что такое распределение Пуассона?
Распределение Пуассона — это инструмент, который помогает предсказать вероятность возникновения определенных событий, если вы знаете, как часто это событие происходило. Это дает нам вероятность того, что данное количество событий произойдет в фиксированный интервал времени .
Это дает нам вероятность того, что данное количество событий произойдет в фиксированный интервал времени .
Распределение Пуассона, действительно только для целых чисел на горизонтальной оси.λ (также обозначается как μ) — ожидаемое количество наступлений события.
Практическое использование распределения Пуассона
Каждую субботу вечером магазин по продаже учебников сдает в аренду в среднем 200 книг. Используя эти данные, вы можете предсказать вероятность того, что в следующие субботние вечера будет продано еще книг (возможно, 300 или 400). Другой пример — количество посетителей в определенном ресторане каждый день. Если среднее количество посетителей в течение семи дней составляет 500, вы можете предсказать вероятность того, что в определенный день будет больше клиентов.
Благодаря этому приложению, распределения Пуассона используются бизнесменами для составления прогнозов о количестве клиентов или продаж в определенные дни или сезоны года.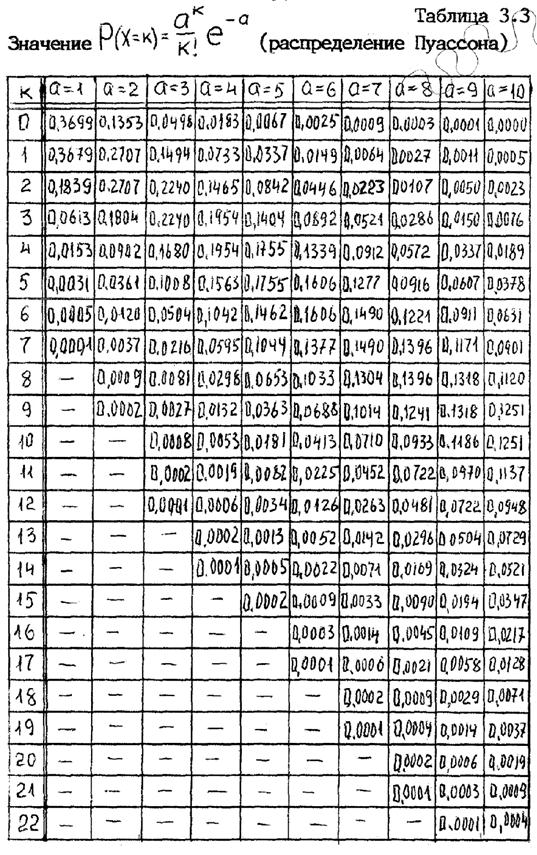 В бизнесе затоваривание запасов иногда будет означать убытки, если товары не будут проданы. Точно так же слишком мало запасов будет означать упущенную возможность для бизнеса, потому что вы не сможете максимизировать свои продажи из-за нехватки запасов. Используя этот инструмент, бизнесмены могут оценить время, когда спрос необычно высок, чтобы они могли закупить больше акций.Отели и рестораны могут подготовиться к наплыву клиентов, они могут заранее нанять дополнительных временных работников, закупить больше товаров или составить план действий на случай непредвиденных обстоятельств на тот случай, если они не смогут разместить своих гостей, прибывающих в этот район.
В бизнесе затоваривание запасов иногда будет означать убытки, если товары не будут проданы. Точно так же слишком мало запасов будет означать упущенную возможность для бизнеса, потому что вы не сможете максимизировать свои продажи из-за нехватки запасов. Используя этот инструмент, бизнесмены могут оценить время, когда спрос необычно высок, чтобы они могли закупить больше акций.Отели и рестораны могут подготовиться к наплыву клиентов, они могут заранее нанять дополнительных временных работников, закупить больше товаров или составить план действий на случай непредвиденных обстоятельств на тот случай, если они не смогут разместить своих гостей, прибывающих в этот район.
Распределение Пуассона позволяет компаниям регулировать спрос и предложение, чтобы их бизнес приносил хорошую прибыль. Кроме того, предотвращается растрата ресурсов.
Расчет распределения Пуассона
ПМС распределения Пуассона: P (x; μ) = (e -μ * μ x ) / x!
Где:
- Символ «!» факториал.
- μ (ожидаемое количество вхождений) иногда записывается как λ. Иногда называется частотой событий или параметром скорости.

Пример вопроса
Среднее количество сильных штормов в вашем городе — 2 в год. Какова вероятность, что в следующем году на ваш город обрушится ровно 3 шторма?
Шаг 1: Определите компоненты, которые необходимо включить в уравнение.
- μ = 2 (среднее количество штормов в год, исторически)
- x = 3 (количество штормов, которые, по нашему мнению, могут поразить в следующем году)
- е = 2.71828 (e — число Эйлера, постоянная)
Шаг 2: подставьте значения из шага 1 в формулу распределения Пуассона:
- P (x; μ) = (e -μ ) (μ x ) / x!
- = (2,71828 -2 ) (2 3 ) / 3!
- = (0,13534) (8) / 6
- = 0,180
Вероятность трех штормов в следующем году составляет 0,180, или 18%
Как вы, наверное, догадались, вы можете вычислить распределение Пуассона вручную, но это займет очень много времени, если у вас нет простого набора данных. Обычный способ вычисления распределения Пуассона в реальных жизненных ситуациях — использование такого программного обеспечения, как IBM SPSS.
Обычный способ вычисления распределения Пуассона в реальных жизненных ситуациях — использование такого программного обеспечения, как IBM SPSS.
Распределение Пуассона против биномиального
Приведенный выше пример был слишком упрощен, чтобы показать вам, как работать с проблемой. Однако может быть сложно понять, следует ли использовать биномиальное распределение или распределение Пуассона. Если инструктор не дал вам конкретных рекомендаций, воспользуйтесь следующими общими рекомендациями.
- Если ваш вопрос имеет среднюю вероятность события на единицу (т.е.е. на единицу времени, цикл, событие) и , вы хотите найти вероятность определенного количества событий, происходящих за период времени (или количество событий), затем используйте распределение Пуассона.
- Если вам дана точная вероятность и вы хотите найти вероятность того, что событие произойдет определенное количество раз из x (т.е. 10 раз из 100 или 99 раз из 1000), используйте формулу биномиального распределения. .
 10 раз из 100 или 99 раз из 1000), используйте формулу биномиального распределения. .
10 раз из 100 или 99 раз из 1000), используйте формулу биномиального распределения. .Простые числа и распределение Пуассона
Существует связь между распределением Пуассона и теоремой о простых числах: короткие интервалы простых чисел соответствуют приблизительной форме распределения Пуассона.
Формула распределения Пуассона: P (x; μ) = (e -μ ) (μ x ) / x!
Предположим, что x (как в функции подсчета простых чисел — это очень большое число, например x = 10 100 . Если вы выберете случайное число, которое меньше или равно x, вероятность того, что это число будет простым, будет примерно 0,43% .Кроме того, если сделать этот интервал очень коротким, с μ x > 0 и j меньше 20, то количество простых чисел в интервале примерно соответствует распределению Пуассона (Croot, 2010).
Список литературы
Бейер, В. Х. Стандартные математические таблицы CRC, 31-е изд. Бока Ратон, Флорида: CRC Press, стр. 536 и 571, 2002.
Бока Ратон, Флорида: CRC Press, стр. 536 и 571, 2002.
Линдстрем, Д. (2010). Краткое изложение статистики Шаума, второе издание (Schaum’s Easy Outlines), 2-е издание. McGraw-Hill Education
Vogt, W.P. (2005). Словарь статистики и методологии: нетехническое руководство для социальных наук. МУДРЕЦ.
Wheelan, C. (2014). Голая статистика. W. W. Norton & Company
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые решения на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Распределение Пуассона
Распределение Пуассона — это распределение вероятностей, которое получается из
эксперимент.
Атрибуты эксперимента Пуассона
Эксперимент Пуассона — это статистический эксперимент, обладающий следующими свойствами:
- Вероятность того, что успех произойдет в очень маленьком регионе, равна практически ноль.
Обратите внимание, что указанный регион может принимать разные формы. Например, это могло быть длина, площадь, объем, период времени и т. д.
Обозначение
Следующие обозначения полезны, когда мы говорим о распределении Пуассона.
- P ( x ; μ): вероятность Пуассона , что точно x успех случается в эксперименте Пуассона, когда среднее число успехов μ.
Распределение Пуассона
Пуассоновская случайная величина — это количество успехов, которые
результат эксперимента Пуассона. В
распределение вероятностей пуассоновской случайной величины называется пуассоновским
Распределение .
В
распределение вероятностей пуассоновской случайной величины называется пуассоновским
Распределение .
Учитывая среднее количество успехов (μ) в заданном регионе, мы можем вычислить вероятность Пуассона по следующей формуле:
Формула Пуассона .Предположим, мы проводим Эксперимент Пуассона, в котором среднее количество успехов в пределах заданного область μ. Тогда вероятность Пуассона равна:
P ( x ; μ) = (e -μ ) (μ x ) / x!
, где x — фактическое количество успехов, полученных в результате эксперимента, а e примерно равно 2,71828.
Распределение Пуассона обладает следующими свойствами:
Пример распределения Пуассона
Среднее количество домов, продаваемых компанией Acme Realty, составляет 2 дома в день.Какова вероятность того, что завтра будет продано ровно 3 дома?
Решение: Это эксперимент Пуассона, в котором мы знаем следующее:
- е = 2,71828; поскольку e — константа, приблизительно равная 2,71828.

Мы подставляем эти значения в формулу Пуассона следующим образом:
P ( x ; μ) = (e -μ ) (μ x ) / x!
P (3; 2) = (2.71828 -2 ) (2 3 ) / 3!
P (3; 2) = (0,13534) (8) / 6
P (3; 2) = 0,180
Таким образом, вероятность продажи 3 дома завтра составляет 0,180.
Калькулятор Пуассона
Ясно, что формула Пуассона требует многих трудоемких вычислений. Стат Калькулятор Пуассона Trek сделает эту работу за вас — быстро, легко и безошибочный. Используйте калькулятор Пуассона для вычисления вероятностей Пуассона и кумулятивные вероятности Пуассона.Его можно найти в Stat Trek. главное меню на вкладке Stat Tools. Или вы можете нажать кнопку ниже.
Калькулятор ПуассонаКумулятивная вероятность Пуассона
Кумулятивная вероятность Пуассона относится к вероятности того, что
случайная величина Пуассона больше некоторого указанного нижнего предела
и меньше некоторого указанного верхнего предела.
Пример кумулятивного Пуассона
Предположим, что среднее количество львов, замеченных на однодневном сафари, равно 5.Что это вероятность того, что туристы увидят менее четырех львов в следующий день сафари?
Решение: Это эксперимент Пуассона, в котором мы знаем следующее:
- х = 0, 1, 2 или 3; поскольку мы хотим выяснить вероятность того, что туристы увидят менее 4 львов; то есть нам нужна вероятность того, что они увидят 0, 1, 2 или 3 льва.
- е = 2,71828; поскольку e — константа, приблизительно равная 2.71828.
Для решения этой задачи нам нужно найти вероятность того, что туристы увидят 0, 1, 2 или 3 льва. Таким образом, нам нужно вычислить сумму четырех вероятностей: P (0; 5) + P (1; 5) + P (2; 5) + P (3; 5). Для вычисления этой суммы мы используем пуассоновский формула:
P (x < 3, 5) = P (0; 5) + P (1; 5) + P (2; 5) + P (3; 5)
P (x < 3, 5) = [(e -5 ) (5 0 ) / 0! ] + [(e -5 ) (5 1 ) / 1! ] + [(e -5 ) (5 2 ) / 2! ] + [(e -5 ) (5 3 ) / 3! ]
P (x < 3, 5) = [(0. 006738) (1) / 1] + [(0.006738) (5) / 1] + [
(0,006738) (25) / 2] + [(0,006738) (125) / 6]
006738) (1) / 1] + [(0.006738) (5) / 1] + [
(0,006738) (25) / 2] + [(0,006738) (125) / 6]
P (x < 3, 5) = [0,0067] + [0,03369] + [0,084224] + [0,140375]
P (x < 3, 5) = 0,2650
Таким образом, вероятность увидеть не более 3 львов составляет 0,2650.
Определение распределения Пуассона
Что такое распределение Пуассона?
В статистике распределение Пуассона — это распределение вероятностей, которое можно использовать, чтобы показать, сколько раз событие может произойти в течение определенного периода времени.Другими словами, это подсчетное распределение. Распределение Пуассона часто используется для понимания независимых событий, которые происходят с постоянной скоростью в течение заданного интервала времени. Он был назван в честь французского математика Симеона Дени Пуассона.
Распределение Пуассона — это дискретная функция, что означает, что переменная может принимать только определенные значения в (потенциально бесконечном) списке. Иными словами, переменная не может принимать все значения в любом непрерывном диапазоне. Для распределения Пуассона (дискретного распределения) переменная может принимать только значения 0, 1, 2, 3 и т. Д., без дробей и десятичных знаков.
Иными словами, переменная не может принимать все значения в любом непрерывном диапазоне. Для распределения Пуассона (дискретного распределения) переменная может принимать только значения 0, 1, 2, 3 и т. Д., без дробей и десятичных знаков.
Ключевые выводы
- Распределение Пуассона, названное в честь математика Симеона Дени Пуассона, может использоваться для измерения того, сколько раз событие может произойти в течение периода «X».
- Распределения Пуассона, следовательно, используются, когда интересующий фактор является дискретной переменной счета.
- Многие экономические и финансовые данные появляются в виде переменных подсчета, например, сколько раз человек становится безработным в данном году, что позволяет анализировать их с помощью распределения Пуассона.
Понимание распределений Пуассона
Распределение Пуассона можно использовать для оценки вероятности того, что что-то произойдет «X» раз. Например, если среднее количество людей, арендующих фильмы в пятницу вечером в одном месте видеомагазина, составляет 400 человек, распределение Пуассона может ответить на такие вопросы, как «Какова вероятность того, что более 600 человек будут брать фильмы напрокат?» Следовательно, применение распределения Пуассона позволяет менеджерам вводить оптимальные системы планирования, которые не будут работать, скажем, с нормальным распределением.
Одним из самых известных исторических и практических применений распределения Пуассона была оценка ежегодного числа прусских кавалерийских солдат, убитых из-за ударов ногами. Другие современные примеры включают оценку количества автомобильных аварий в городе определенного размера; в физиологии это распределение часто используется для расчета вероятностных частот различных типов секреции нейромедиаторов. Или, если в видеомагазин в среднем 400 клиентов каждую пятницу вечером, какова вероятность того, что 600 клиентов придут в каждую пятницу вечером?
Формула распределения Пуассона:
Формула распределения Пуассона.К. К. ТейлорГде:
Учитывая данные, которые соответствуют распределению Пуассона, графически оно выглядит следующим образом:
Пример распределения Пуассона.Инвестопедия
Итак, в примере, изображенном на графике выше, предположим, что некоторый рабочий процесс имеет коэффициент ошибок 3%. Если мы дополнительно предположим 100 случайных испытаний; Распределение Пуассона описывает вероятность получения определенного количества ошибок в течение некоторого периода времени, например, одного дня.
Когда использовать распределение Пуассона в финансах
Распределение Пуассона также обычно используется для моделирования данных финансового подсчета, где результат невелик и часто равен нулю.Например, в финансах его можно использовать для моделирования количества сделок, которые типичный инвестор совершит в данный день, которое может быть 0 (часто), или 1, или 2 и т. Д.
В качестве другого примера, эту модель можно использовать для прогнозирования количества «потрясений» на рынке, которые произойдут в определенный период времени, скажем, за десятилетие.
Функция ПУАССОН.РАСП — служба поддержки Office
Возвращает распределение Пуассона. Распространенное применение распределения Пуассона — это прогнозирование количества событий за определенное время, например количества автомобилей, прибывающих на платную площадку за 1 минуту.
Синтаксис
ПУАССОН.РАСП (x; среднее; кумулятивное)
Аргументы функции ПУАССОН.РАСП следующие:
X Обязательно. Количество событий.
Среднее Обязательно. Ожидаемое числовое значение.
Накопительное Обязательно.Логическое значение, определяющее форму возвращаемого распределения вероятностей. Если кумулятивное значение ИСТИНА, ПУАССОН.РАСП возвращает кумулятивную вероятность Пуассона того, что количество происходящих случайных событий будет между нулем и x включительно; если FALSE, он возвращает функцию массы вероятности Пуассона, что количество происходящих событий будет точно x.
Примечания
Если x не является целым числом, оно усекается.
Если x или среднее не является числом, ПУАССОН.РАСП возвращает # ЗНАЧ! значение ошибки.
Если x <0, ПУАССОН.РАСП возвращает # ЧИСЛО! значение ошибки.
Если среднее значение <0, ПУАССОН.РАСП возвращает # ЧИСЛО! значение ошибки.
ПУАССОН.РАСП рассчитывается следующим образом.
Для совокупного = ЛОЖЬ:
Для совокупного = ИСТИНА:
Пример
Скопируйте пример данных из следующей таблицы и вставьте его в ячейку A1 нового листа Excel.Чтобы формулы отображали результаты, выберите их, нажмите F2, а затем нажмите Enter. При необходимости вы можете настроить ширину столбца, чтобы увидеть все данные.
Данные | Описание | |
|---|---|---|
2 | Количество событий | |
5 | Ожидаемое среднее | |
Формула | Описание | R esult |
= ПУАССОН.РАСП (A2; A3; ИСТИНА) | Кумулятивная вероятность Пуассона с аргументами, указанными в A2 и A3. | 0,124652 |
= ПУАССОН.РАСП (A2; A3; ЛОЖЬ) | Функция массы вероятности Пуассона с аргументами, указанными в A2 и A3. | 0,084224 |
Распределение Пуассона и объяснение процесса Пуассона | by Will Koehrsen
Что касается проблемы, которую мы решим с помощью распределения Пуассона, мы могли бы продолжить работу с ошибками веб-сайтов, но я предлагаю нечто более грандиозное. В детстве отец часто брал меня к себе во двор, чтобы понаблюдать (или попытаться понаблюдать) за метеоритными дождями. Мы не были космическими фанатами, но наблюдения за горящими в небе объектами из космоса было достаточно, чтобы вывести нас на улицу, даже несмотря на то, что метеорные дожди, казалось, всегда случались в самые холодные месяцы.
Количество наблюдаемых метеоров можно смоделировать как распределение Пуассона, потому что метеоры независимы, среднее количество метеоров в час постоянно (в краткосрочной перспективе), и — это приблизительное значение — метеоры не возникают одновременно. Чтобы охарактеризовать распределение Пуассона, все, что нам нужно, это параметр скорости, который представляет собой количество событий / интервал * длина интервала. Насколько я помню, нам сказали ожидать 5 метеоров в час в среднем или 1 каждые 12 минут .Из-за ограниченного терпения маленького ребенка (особенно в холодную ночь) мы никогда не проводили вне дома более 60 минут, поэтому мы будем использовать это как период времени. Соединяя их вместе, получаем:
Параметр скорости для ситуации с метеорным потоком.Что именно означает «ожидается 5 метеоров»? По словам моего пессимистичного отца, это означало, что мы увидим 3 метеора за час, максимум. В то время у меня не было навыков работы с данными и я доверял его мнению. Теперь, когда я старше и испытываю здоровый скептицизм по отношению к авторитетным фигурам, пора проверить его заявление.Мы можем использовать распределение Пуассона, чтобы найти вероятность увидеть ровно 3 метеора за один час наблюдения:
Вероятность наблюдения 3 метеоров за 1 час.14% или примерно 1/7. Если бы мы выходили на улицу каждую ночь в течение одной недели, то можно было бы ожидать, что мой отец окажется прав ровно один раз! Приятно знать, что мы ищем распределение, вероятность увидеть разное количество метеоров. Делать это вручную утомительно, поэтому мы будем использовать Python, который вы можете увидеть в этом блокноте Jupyter, для расчетов и визуализации.
На приведенном ниже графике показана функция вероятности массы для количества метеоров в час со средним временем между метеорами 12 минут (что равносильно тому, что в час ожидается 5 метеоров).
13. Распределение вероятностей Пуассона
Распределение Пуассона было разработано французским математиком Симеоном Дени Пуассоном в 1837 году.
Случайная величина Пуассона удовлетворяет следующим условиям:
Количество успехов в двух непересекающихся временных интервалах не зависит.
Вероятность успеха в течение небольшого временного интервала пропорциональна всей длине временного интервала.
Помимо непересекающихся временных интервалов, случайная величина Пуассона также применяется к непересекающимся областям пространства .
Приложения
- число смертей от удара ногой в прусской армии (первое приложение)
- врожденные дефекты и генетические мутации
- редких заболеваний (например, лейкемии, но не СПИДа, потому что он заразен и т. не независимый) — особенно в судебных делах
- ДТП
- Транспортный поток и идеальная дистанция пропуска
- количество опечаток на странице В гамбургерах McDonald’s найдено
- волосков
- распространение исчезающих видов животных в Африке
- отказ станка за месяц
Обозначение
Мы используем прописных переменных (например, X и Z ) для обозначения случайных величин и строчные буквы (например, x и z ) для обозначения конкретных значений этих переменных.х) / (х!) `
где
`х = 0, 1, 2, 3 …`
`e = 2.71828` (но используйте кнопку калькулятора e )
`μ =` среднее количество успехов в данном временном интервале или области пространства
Среднее и дисперсия распределения Пуассона
Если μ — это среднее количество успехов, происходящих в данном временном интервале или регионе в распределении Пуассона, то среднее и дисперсия распределения Пуассона равны μ.
E ( X ) = мкм
и
В ( X ) = σ 2 = мкм
Примечание. В распределении Пуассона для определения вероятности события требуется только , один параметр , μ.
Пример 1
Продавец по страхованию жизни продает в среднем «3» полиса страхования жизни в неделю. Используйте закон Пуассона, чтобы рассчитать вероятность того, что за данную неделю он продаст
. 0) / (0!) = 4.1) / (1!) = 0,32929`Пример 2
Двадцать листов алюминиевого сплава были исследованы на предмет дефектов поверхности. Частота количества листов с заданным количеством брака на листе составила
.| Количество дефектов | Частота |
|---|---|
| `0` | `4` |
| `1` | `3` |
| `2` | `5` |
| `3` | `2` |
| `4` | `4` |
| `5` | `1` |
| `6` | `1` |
Какова вероятность найти случайно выбранный лист с 3 или более дефектами поверхности?
Ответ
Общее количество дефектов определяется по:
`(0 × 4) + (1 × 3)` + (2 × 5) + (3 × 2) `+ (4 × 4) + (5 × 1)` `+ (6 × 1)` `= 46`
Таким образом, среднее количество дефектов для 20 листов определяется по формуле:
му = 46/20 = 2. 5) / (5!) = 0.10082`
ПРИМЕЧАНИЕ: Эта проблема похожа на проблему биномиального распределения, с которой мы встречались в предыдущем разделе.
Если мы сделаем это с использованием бинома с `n = 300`,` x = 5`, `p = 0,01` и` q = 0,99`, мы получим:
P ( X = 5) = C (300,5) (0,01) 5 (0,99) 295 = 0,10099
Видим, что результат очень похож. Мы можем использовать биномиальное распределение для аппроксимации распределения Пуассона (и наоборот) при определенных обстоятельствах.
Гистограмма вероятностей
Урок 12: Распределение Пуассона
Пусть \ (X \) равно количеству опечаток на печатной странице в среднем 3 опечатки на странице. Какова вероятность того, что на случайно выбранной странице есть хотя бы одна опечатка ?
Мы можем найти запрошенную вероятность прямо из PMF. Вероятность того, что \ (X \) равно хотя бы одному:
\ (P (X \ ge 1) = 1-P (X = 0) \)
Следовательно, используя п.{-3} = 4 (0,0498) = 0,1992 \)
То есть вероятность найти не более одной опечатки на случайно выбранной странице составляет чуть менее 20%, когда среднее количество опечаток на странице равно 3.
Так же, как мы использовали кумулятивную таблицу вероятностей при поиске биномиальных вероятностей, мы могли бы альтернативно использовать кумулятивную таблицу вероятностей Пуассона, такую как Таблица III в конце вашего учебника. Вы должны уметь использовать как формулы, так и таблицы. Если вы посмотрите на таблицу, вы увидите, что она состоит из трех страниц.Давайте просто взглянем на верхнюю часть первой страницы таблицы, чтобы понять, как она работает:
Таким образом, чтобы использовать таблицу в конце учебника, а также таблицу в конце большинства учебников вероятности, чтобы найти кумулятивные вероятности Пуассона, выполните следующие действия:
- Найдите столбец, озаглавленный соответствующим \ (\ lambda \). Обратите внимание, что есть три строки, содержащие \ (\ lambda \) на первой странице таблицы, две строки, содержащие \ (\ lambda \) на второй странице таблицы, и одна строка, содержащая \ (\ lambda \) на последняя страница таблицы.
- Найдите \ (x \) в первом столбце слева, для которого вы хотите найти \ (F (x) = P (X \ le x) \).
Попробуем на примере. Если \ (X \) равно количеству опечаток на печатной странице со средним значением 3 опечатки на страницу, какова вероятность того, что на случайно выбранной странице будет четыре опечатки ?
Решение
Вероятность того, что случайно выбранная страница содержит четыре опечатки, может быть записана как \ (P (X = 4) \). Мы можем вычислить \ (P (X = 4) \), вычитая \ (P (X \ le 3) \) из \ (P (X \ le 4) \).Чтобы найти \ (P (X \ le 3) \) и \ (P (X \ le 4) \) с помощью таблицы Пуассона, мы:
- Найдите столбец, озаглавленный \ (\ lambda = 3 \).
- Найдите 3 в первом столбце слева, так как мы хотим найти \ (F (3) = P (X \ le 3) \). И найдите 4 в первом столбце слева, так как мы хотим найти \ (F (4) = P (X \ le 4) \).
Теперь все, что нам нужно сделать, это, во-первых, прочитать значение вероятности там, где пересекаются столбец \ (\ lambda = 3 \) и строка \ (x = 3 \), и, во-вторых, прочитать значение вероятности там, где \ Столбец (\ lambda = 3 \) и строка \ (x = 4 \) пересекаются.Что вы получаете?
Отвечать
\ (\ lambda = E (X) \) x 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 0 0,905 0,819 0.741 0,670 0.607 0,549 0,497 0,449 0,407 0,368 1 0,995 0,982 0,963 0,938 0,910 0,878 0,844 0,809 0,772 0,736 2 1.000 0.999 0,996 0,992 0,986 0,970 0,966 0,953 0,937 0,920 3 1.000 1.000 1.000 0,999 0,998 0,997 0,994 0,991 0,987 0,981 4 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,996 5 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 6 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 x 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 0 0.333 0,301 0,273 0,247 0,223 0,202 0,183 0,165 0,150 0,135 1 0,699 0,663 0,627 0,592 0,558 0,525 0,493 0,463 0,434 0,403 2 0.900 0,879 0,857 0,833 0,809 0,830 0,757 0,731 0,704 0,677 3 0,974 0,966 0,957 0,946 0,934 0,921 0,907 0,981 0,875 0,857 4 0.995 0,992 0,989 0,986 0,981 0,976 0,970 0,964 0,956 0,947 5 0,999 0,998 0,998 0,997 0,996 0,994 0,992 0,990 0,987 0,983 6 1.000 1.000 1.000 0,999 0,999 0,999 0,998 0,997 0,997 0,995 7 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,999 8 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 x 2,2 2,4 2,6 2,8 3,0 3,2 3,4 3,6 3,8 4,0 0 0.111 0,091 0,074 0,061 0,050 0,051 0,033 0,027 0,022 0,018 1 0,355 0,308 0,267 0,231 0,199 0,171 0,147 0,126 0,107 0,092 2 0.623 0,570 0,518 0,469 0,423 0,380 0,340 0,303 0,269 0,238 3 0,819 0,779 0,736 0,692 0,647 0.603 0,558 0,515 0,473 0,433 4 0.928 0,904 0,887 0,848 0,815 0,781 0,744 0,706 0,668 0,629 5 0,975 0,964 0,951 0,935 0,916 0,895 0,871 0,844 0,816 0,785 6 0.993 0,988 0,983 0,976 0,966 0,955 0,942 0,927 0,909 0,889 7 0,998 0,997 0,995 0,992 0,988 0,983 0,977 0,969 0,960 0,949 8 1.000 0,990 0,999 0,998 0,993 0,994 0,992 0,988 0,984 0,979 9 1.000 1.000 1.000 0,999 0,999 0,998 0,997 0,996 0,994 0,992 10 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,997 11 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 12 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
\ (\ lambda = E (X) \) x 0,1 0,2 0,3 0,4 0.5 0,6 0,7 0,8 0,9 1,0 0 0,905 0,819 0,741 0,670 0.607 0,549 0,497 0,449 0,407 0,368 1 0,995 0,982 0,963 0.938 0,910 0,878 0,844 0,809 0,772 0,736 2 1.000 0,999 0,996 0,992 0,986 0,970 0,966 0,953 0,937 0,920 3 1.000 1.000 1.000 0,999 0,998 0,997 0,994 0,991 0,987 0,981 4 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,996 5 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 6 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 x 1.1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 0 0,333 0,301 0,273 0,247 0,223 0,202 0,183 0,165 0,150 0,135 1 0.699 0,663 0,627 0,592 0,558 0,525 0,493 0,463 0,434 0,403 2 0,900 0,879 0,857 0,833 0,809 0,830 0,757 0,731 0,704 0,677 3 0.974 0,966 0,957 0,946 0,934 0,921 0,907 0,981 0,875 0,857 4 0,995 0,992 0,989 0,986 0,981 0,976 0,970 0,964 0,956 0,947 5 0.999 0,998 0,998 0,997 0,996 0,994 0,992 0,990 0,987 0,983 6 1.000 1.000 1.000 0,999 0,999 0,999 0,998 0,997 0,997 0,995 7 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,999 8 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 x 2.2 2,4 2,6 2,8 3,0 3,2 3,4 3,6 3,8 4,0 0 0,111 0,091 0,074 0,061 0,050 0,051 0,033 0,027 0,022 0,018 1 0.355 0,308 0,267 0,231 0,199 0,171 0,147 0,126 0,107 0,092 2 0,623 0,570 0,518 0,469 0,423 0,380 0,340 0,303 0,269 0,238 3 0.819 0,779 0,736 0,692 0,647 0.603 0,558 0,515 0,473 0,433 4 0,928 0,904 0,887 0,848 0,815 0,781 0,744 0,706 0,668 0,629 5 0.975 0,964 0,951 0,935 0,916 0,895 0,871 0,844 0,816 0,785 6 0,993 0,988 0,983 0,976 0,966 0,955 0,942 0,927 0,909 0,889 7 0.998 0,997 0,995 0,992 0,988 0,983 0,977 0,969 0,960 0,949 8 1.000 0,990 0,999 0,998 0,993 0,994 0,992 0,988 0,984 0,979 9 1.000 1.000 1.000 0,999 0,999 0,998 0,997 0,996 0,994 0,992 10 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,997 11 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 12 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 Кумулятивная таблица вероятностей Пуассона говорит нам, что нахождение \ (P (X \ le 4) = 0.815 \) и \ (P (X \ le 3) = 0,647 \). Следовательно:
\ (P (X = 4) = P (X \ le 4) -P (X \ le 3) = 0,815-0,647 = 0,168 \)
То есть вероятность того, что на случайно выбранной странице будет четыре опечатки, составляет около 17%. Поскольку в этом случае не потребуется много работы, вы можете проверить, что вы получите тот же ответ, с помощью Poisson p.m.f.
Какова вероятность того, что на трех случайно выбранных страницах будет больше восьми опечаток ?
Решение
Для решения этой проблемы нужно сделать еще один шаг.Напомним, что \ (X \) обозначает количество опечаток на одной распечатанной странице . Затем давайте определим новую случайную величину \ (Y \), которая равна количеству опечаток на трех распечатанных страницах. Если среднее значение \ (X \) составляет 3 опечатки на странице, то среднее значение \ (Y \) составляет:
.\ (\ lambda_Y = 3 \ text {опечаток на одной странице} \ times 3 \ text {pages} = 9 \ text {опечаток на трех страницах} \)
Тогда поиск желаемой вероятности включает в себя нахождение:
\ (P (Y> 8) = 1-P (Y \ le 8) \)
, где \ (P (Y \ le 8) \) находится при просмотре таблицы Пуассона в столбце, озаглавленном \ (\ lambda = 9.0 \) и строку, озаглавленную \ (x = 8 \). Что вы получаете?
Отвечать
x 6,5 7,0 7,5 8,0 8,5 9,0 9,5 10,0 10,5 11,0 0 0,002 0,001 0,001 0.000 0,000 0,000 0,000 0,000 0,000 0,000 1 0,011 0,007 0,005 0,003 0,002 0,001 0,001 0,000 0,000 0,000 2 0,043 0,030 0.020 0,014 0,009 0,006 0,004 0,003 0,002 0,001 3 0,112 0,082 0,059 0,042 0,030 0,021 0,015 0,010 0,007 0,005 4 0,224 0.173 0,132 0,100 0,074 0,055 0,040 0,029 0,021 0,015 5 0,369 0,301 0,241 0,191 0,150 0,116 0,089 0,067 0,050 0,015 6 0.527 0,450 0,378 0,313 0,256 0,207 0,165 0,130 0,102 0,079 7 0,673 0,599 0,525 0,453 0,386 0,324 0,269 0,220 0,179 0,143 8 0.792 0,729 0,662 0,593 0,523 0,456 0,392 0,333 0,279 0,232 9 0,877 0,830 0,776 0,717 0,653 0,587 0,522 0,458 0,397 0,341 10 0.933 0,901 0,862 0,816 0,763 0,706 0,645 0,583 0,521 0,460 11 0,966 0,947 0,921 0,888 0,849 0,803 0,752 0,697 0,639 0,579 12 0.984 0,973 0,957 0,936 0,909 0,876 0,836 0,792 0,742 0,689 13 0,993 0,987 0,978 0,966 0,949 0,926 0,898 0,864 0,825 0,781 14 0.997 0,994 0,990 0,983 0,973 0,959 0,940 0,917 0,888 0,854 15 0,999 0,998 0,995 0,992 0,986 0,978 0,967 0,951 0,932 0,907 16 1.000 0,999 0,998 0,996 0,993 0,989 0,982 0,973 0,960 0,944 17 1.000 1.000 0,999 0,998 0,997 0,995 0,991 0,986 0,978 0,968 18 1.000 1.000 1.000 0,999 0,999 0,998 0,096 0,993 0,988 0,982 19 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,997 0,994 0,991 20 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,998 0,997 0,995 21 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 22 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 23 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
x 6.5 7,0 7,5 8,0 8,5 9,0 9,5 10,0 10,5 11,0 0 0,002 0,001 0,001 0,000 0,000 0,000 0,000 0,000 0,000 0,000 1 0.011 0,007 0,005 0,003 0,002 0,001 0,001 0,000 0,000 0,000 2 0,043 0,030 0,020 0,014 0,009 0,006 0,004 0,003 0,002 0,001 3 0.112 0,082 0,059 0,042 0,030 0,021 0,015 0,010 0,007 0,005 4 0,224 0,173 0,132 0,100 0,074 0,055 0,040 0,029 0,021 0,015 5 0.369 0,301 0,241 0,191 0,150 0,116 0,089 0,067 0,050 0,015 6 0,527 0,450 0,378 0,313 0,256 0,207 0,165 0,130 0,102 0,079 7 0.673 0,599 0,525 0,453 0,386 0,324 0,269 0,220 0,179 0,143 8 0,792 0,729 0,662 0,593 0,523 0,456 0,392 0,333 0,279 0,232 9 0.877 0,830 0,776 0,717 0,653 0,587 0,522 0,458 0,397 0,341 10 0,933 0,901 0,862 0,816 0,763 0,706 0,645 0,583 0,521 0,460 11 0.966 0,947 0,921 0,888 0,849 0,803 0,752 0,697 0,639 0,579 12 0,984 0,973 0,957 0,936 0,909 0,876 0,836 0,792 0,742 0,689 13 0.993 0,987 0,978 0,966 0,949 0,926 0,898 0,864 0,825 0,781 14 0,997 0,994 0,990 0,983 0,973 0,959 0,940 0,917 0,888 0,854 15 0.999 0,998 0,995 0,992 0,986 0,978 0,967 0,951 0,932 0,907 16 1.000 0,999 0,998 0,996 0,993 0,989 0,982 0,973 0,960 0,944 17 1.000 1.000 0,999 0,998 0,997 0,995 0,991 0,986 0,978 0,968 18 1.000 1.000 1.000 0,999 0,999 0,998 0,096 0,993 0,988 0,982 19 1.000 1.000 1.000 1.000 0,999 0,999 0,998 0,997 0,994 0,991 20 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,998 0,997 0,995 21 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 0,998 22 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0,999 0,999 23 1.000 1.000 1.000 1.000 1.