
Объектом наблюдения в статистике населения является: Национальный исследовательский университет «Высшая школа экономики»
2 Статистическое наблюдение — СтудИзба
2.1. Формирование информационной базы статистического исследования
Статистическое исследование проходит три стадии: статистическое наблюдение, сводку и группировку данных, анализ результатов с помощью обобщающих статистических показателей (абсолютных, относительных и средних величин, показателей вариации, индексов и т.д.).
Статистические наблюдение – это первая стадия всякого статистического исследования, представляющая собой научно-организованный по единой программе учет фактов, о явлениях и процессах общественной жизни и сбор полученных на основе этого учета массовых первичных данных.
Всякое статистическое исследование должно начинаться с получения исходной информации, т.е. с учета фактов и сбора первичного материала. Этот материал в зависимости от цели и содержания статистической работы может быть разнообразен по своему содержанию и способам получения.
Во всех случаях в соответствии с целями и задачами исследования начинают с учета фактов и сбора первичного материала, но организуют учет фактов и сбор первичного материала по разному: факты учитывают либо путем опроса каждого человека, либо путем непосредственной регистрации фактов в момент их возникновения (требования покупателей и степень их удовлетворения), либо путем организации систематического учета на предприятиях. Соответственно получают разного рода первичный статистический материал: анкеты, записи регистраторов, формы отчетности.
Соответственно получают разного рода первичный статистический материал: анкеты, записи регистраторов, формы отчетности.
Статистическое наблюдение – это научно-организованный процесс. Оно включает все подготовительные работы и непосредственный учет массовых первичных данных. От того, насколько правильно будет организованна и проведена эта стадия исследования, зависят все последующие результаты. Это определяется тем, что статистическое наблюдение – всегда наблюдение массовое, имеющее дело со множеством разнообразных условий и факторов. Это очень сложная и ответственная стадия статистической работы, во время которой формируются исходные статистические материалы, которые затем поступят в разработку.
Любое научно организованное статистическое наблюдение должно иметь программу и организованный план своего проведения. При этом должны быть решены вопросы о содержании исходной информации, о том, каким способом, какими средствами и в какие сроки будет проведен учет фактов, как будут организованы сбор и проверка полученного первичного материала.
Задачей статистического наблюдения является получение достоверной исходной информации, объективно освещающей фактическое положение вещей. Достоверность информации обеспечивается компетентностью работников, совершенством инструментария (бланков, инструкций), готовностью объекта и т.д.
Должна быть обеспечена также полнота информации и получение ее в возможно короткий срок. Полнота обеспечивается во-первых, охватом исчерпывающего количества единиц исследуемой совокупности. Во-вторых, полнота информации предполагает и охват наиболее существенных сторон изучаемого явления. Полные данные являются, как правило, массовыми, они обеспечивают потребности комплексного статистического исследования.
Собираемые данные должны быть современными, запоздалая информация может оказаться практически ненужной.
Рекомендуемые файлы
Общее руководство и методическое обеспечение проводимых в стране статистических наблюдений осуществляет Госкомстат РФ. Важнейшие его задачи в области статистического наблюдения следующие:
1. Сбор информации о социально-экономическом положении страны.
Сбор информации о социально-экономическом положении страны.
2. Реализация программ по проведению важнейших общегосударственных наблюдений – переписей населения, основных фондов, скота и др.
3. Методология и организация единой системы статистической отчетности.
4. Сбор данных по программам международных органов – СНГ, ООН.
5. Создание и совершенствование новых технологий сбора, хранения, поиска и выдачи данных или информации потребителям.
Самые важные общегосударственные наблюдения проводятся Госкомстатом РФ. Непосредственный сбор статистических данных ведется региональными статистическими управлениями, отдельными ведомствами, которые представляют информацию в центральные статистические органы. Местные органы осуществляют наблюдения по актуальным проблемам регионального развития. Предприятия и учреждения проводят наблюдения в соответствии с маркетинговой стратегией и учетной политикой.
Научная организация статистического наблюдения необходима для того, чтобы создать наилучшие условия для получения объективно правильных материалов. Первичный статистический материал – это фундамент статистического исследования. Если в результате плохо проведенного статистического наблюдения будет получен дефектный материал, то все статистическое исследование обречено на неудачу, так как дефекты первичного материала, как правило, не могут быть устранены при дальнейшей его обработке.
Первичный статистический материал – это фундамент статистического исследования. Если в результате плохо проведенного статистического наблюдения будет получен дефектный материал, то все статистическое исследование обречено на неудачу, так как дефекты первичного материала, как правило, не могут быть устранены при дальнейшей его обработке.
2.2. Программно-методологические и организационные вопросы статистического наблюдения
Статистическое наблюдение проводят по плану, который включает программно-методологические и организационные вопросы. К программно-методологическим вопросам плана относятся:
а) цель и задачи наблюдения;
б) объект наблюдения;
в) единица наблюдения;
г) единица совокупности;
д) программа наблюдения.
К организационным вопросам относятся:
а) субъекты наблюдения;
б) место наблюдения;
в) время наблюдения;
г) подготовительные работы.
В плане прежде всего должны быть решены вопросы программы наблюдения. Программа – это основной вопрос статистического наблюдения.
Программа – это основной вопрос статистического наблюдения.
Программа наблюдения определяется задачами всего статистического исследования. Поэтому прежде всего необходимо сформулировать цели и задачи всей работы, а затем уже можно решать вопросы программы наблюдения: отграничить его объект, установить единицы наблюдения, определить и сформулировать вопросы программы статистического наблюдения.
С помощью статистического наблюдения решаются строго определенные задачи. Стоящие перед менеджером задачи определяют цель наблюдения. Она может вытекать из постановлений правительственных органов, администрации районов, маркетинговой стратегии фирмы. Общая цель статистического наблюдения состоит в информационном обеспечении управления и конкретизируется в зависимости от многих условий.
Цель определяет и объект статистического наблюдения. Объектом статистического наблюдения называется совокупность единиц изучаемого явления, о которых должны быть собраны статистические сведения.
Для успеха всей работы важно точно определить объект статистического наблюдения, установить границы изучаемой совокупности. Так, например, перед тем как произвести статистическое обследование промышленности, нужно точно определить объект наблюдения, т.е. определить какие предприятия будут отнесены к промышленным, подлежат ли обследованию, например, ремонтные мастерские, предприятия по первичной переработке сельскохозяйственного сырья в хозяйствах и т.д.
Чтобы исследуемая совокупность была однороднее применяют иногда ценз. Цензом в статистике называют ограничительный признак, которому должны удовлетворять все единицы обследуемой совокупности.
Единица наблюдения – это первичный элемент объекта статистического наблюдения, являющийся носителем признаков, подлежащих регистрации, и основной ведущегося при обследовании счета. Численность единиц совокупности характеризует объем и распространенность изучаемого явления, а изменение этой численности – его развитие.
Отчетная единица – это та первичная ячейка от которой должны быть получены необходимые статистические сведения.
Иначе говоря, единица наблюдения – это то, что подвергается обследованию, а отчетная единица – это источник получаемых сведений. Определение единицы наблюдения важно при разработке программы статистического наблюдения, а определение отчетной единицы – при решении вопросов организации сбора сведений.
При переписи оборудования, например, объектом наблюдения будет все промышленное оборудование, единицей наблюдения будет отдельная единица оборудования (станок), а отчетной единицей – промышленное предприятие, т.к. от него получают сведения.
Единицы наблюдения обладают множеством различных признаков. Статистический признак – это конкретное свойство, качество единицы наблюдения. Например, у работника – это возраст, пол, образование и др.
В программу наблюдения следует включать самые необходимые признаки, которые формируются в виде вопросов.
Основные принципы составления программы наблюдения:
1. Программа должна содержать только такие вопросы, которые являются существенными, необходимыми для данного статистического исследования. Не следует загромождать программу излишними деталями;
2. В программу следует включать лишь те вопросы, на которые можно получить точные ответы. Чтобы обеспечить единообразное толкование вопроса дают подстрочный подсказ;
3. Редакция вопросов должна быть краткой, ясной, точной;
4. В программу наблюдения должны включаться только те вопросы, на которые могут быть даны правдивые, достоверные ответы;
5. Программу наблюдения целесообразно строить так, чтобы ответами на одни вопросы можно было контролировать ответы на другие.
Недооценка программы или недостаточная ее обоснованность в дальнейшем приводит к значительным потерям в процессе обработки данных и снижает обоснованность выводов и рекомендаций.
Четкая и ясная формулировка вопросов программы наблюдения имеет исключительное значение для получения точных и доброкачественных статистических сведений.
При всей ясности и точности формулировки вопросов обычно требуются дополнительные пояснения. Такие пояснения, предназначены для лиц, заполняющих отчетность или бланк переписи, дают в специальном статистическом документе – инструкции.
Ответы на вопросы программы наблюдения собирают в документах, обычно называемых статистическими формулярами или носителями информации.
Формуляр статистического наблюдения, содержащий программу наблюдения, носит различные названия: карточка, форма отчетности, бланк, переписной лист, опросный лист и т.д.
В статистической практике применяют два вида формуляра: списочный и индивидуальный.
Списочным формуляром называется такой вид статистического формуляра, в котором приводятся сведения о двух и более единицах совокупности: обо всех членах той или иной семьи, обо всех лицах или части их, работающих в данном учреждении.
Индивидуальным формуляром, или карточкой, называют такой статистический формуляр, в который заносят сведения только об одной единице совокупности.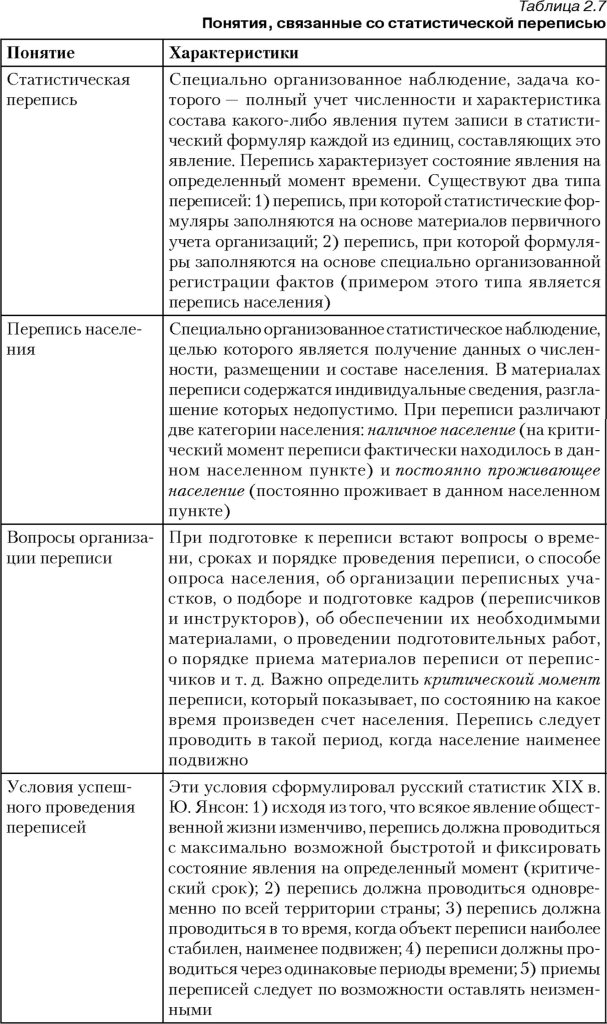
Оба вида статистического формуляра имеют свои достоинства и недостатки. По сравнению со списочной формой карточка может содержать больше вопросов, так как в ней характеризуется только одна единица совокупности.
Недостаток карточной формы состоит в том, что в ней каждый раз нужно писать адресную часть, которая может быть общей для нескольких единиц совокупности, например для членов той или другой семьи и т.д. Это увеличивает трудоемкость работ и требует излишних затрат бумаги. Списочная форма статистического формуляра более экономична, удобна для проверки материала и его машинной разработки.
В организационной части плана наблюдения устанавливается субъект наблюдения – орган, который будет осуществлять наблюдение.
При организации наблюдения решается вопрос о времени наблюдения. Можно выделить объективное и субъективное время наблюдения.
Объективное время наблюдения – время к которому относятся регистрируемые сведения. Это может быть либо определенный момент времени, либо период времени. Момент времени, к которому приурочены регистрируемые сведения, называют критическим моментом наблюдения.
Это может быть либо определенный момент времени, либо период времени. Момент времени, к которому приурочены регистрируемые сведения, называют критическим моментом наблюдения.
Субъективное время наблюдения – это период времени, в течение которого будет производиться наблюдение.
Подготовительные мероприятия включают подготовку кадров для проведения наблюдения, составление предварительных списков единиц наблюдения и отчетных единиц, проведение разъяснительной работы (при переписях населения), составление и печатание статистических формуляров и т.п.
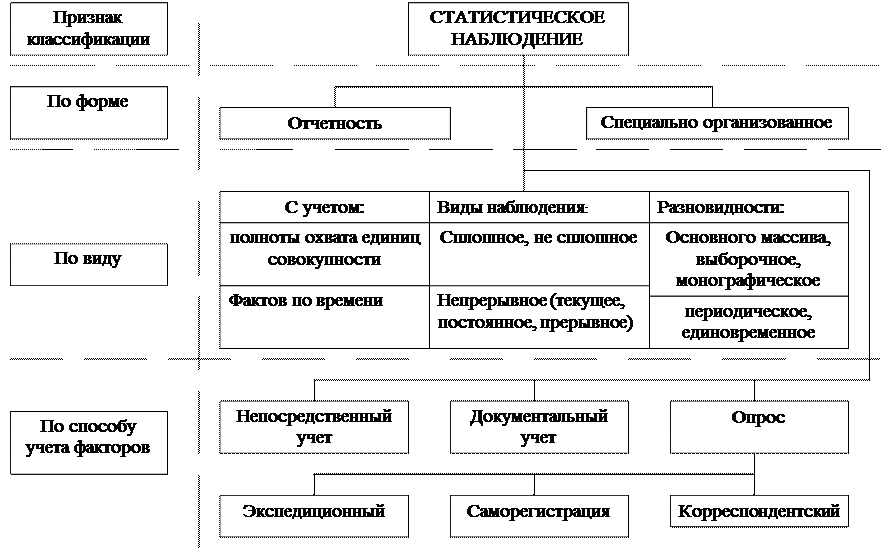
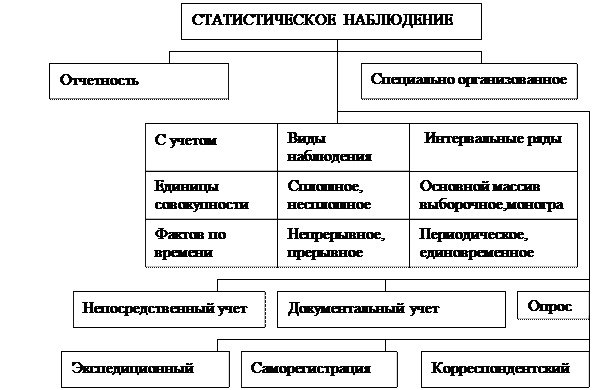
2.3. Организационные формы статистического наблюдения
По форме организации наблюдений различают статистическую отчетность и специальное статистическое обследование.
Статистическая отчетность составляется по строго установленной форме, в определенные сроки и подписывается ответственным лицом.
Специальное статистическое обследование организуется с целью получения данных, которые не содержатся в отчетности, или содержатся в отчетности в очень сокращенном объеме.
Статистическая отчетность – это форма статистического наблюдения, при которой соответствующие органы получают от предприятий, организаций и учреждений необходимые им статистические данные в виде установленных в законном порядке отчетных документов (статистических отчетов) за подписями лиц, ответственных за представление и достоверность сообщаемых сведений.
Статистическая отчетность характеризуется строгой регламентацией. Представление ее в предусмотренные адреса и сроки является обязательным для предприятий и организаций.
Источником сведений для заполнения форм отчетности являются первичные документы, которые ведутся на различных предприятиях. Учетные записи в этих документах непосредственно обусловлены потребностями оперативной работы предприятий, без них невозможно повседневно руководить их деятельностью. Данные первичного учета на предприятиях подытоживаются, и их итоги заносятся в формы статистической отчетности.
Вторая форма наблюдения – специальные статистические обследования.
Наиболее распространенным видом специальных обследований являются переписи. Перепись – это специально организованное статистическое наблюдение, задача которого – полный учет численности и характеристика состава какого-либо явления путем записи в статистический формуляр каждой из единиц, составляющих это явление. Перепись характеризует состояние явления на определенный момент времени.
Проводится два типа статистических переписей. Первый тип – это переписи, в которых статистические формуляры заполняют на основе материалов первичного учета предприятий. Эти переписи, как правило, проводят работники предприятий и учреждений под руководством органов государственной статистики. Второй тип – переписи, при которых формуляры заполняют на основе специально организованной регистрации фактов. Примером первого типа являются переписи остатков различных материалов, переписи промышленного оборудования, учет тракторного парка в сельском хозяйстве, учет специалистов в народном хозяйстве и многие другие. Примером второго типа переписей является перепись населения.
Примером второго типа переписей является перепись населения.
В современных условиях получает распространение специальное организованное наблюдение за состоянием явлений и процессов – мониторинг. Мониторинг применяется для характеристики и систематического слежения за определенными социальными индикаторами. Таким способом изучается качество жизни и окружающая среда. И хотя мониторинг шире рамок традиционного статистического наблюдения, он в определенной степени является источником статистической информации.
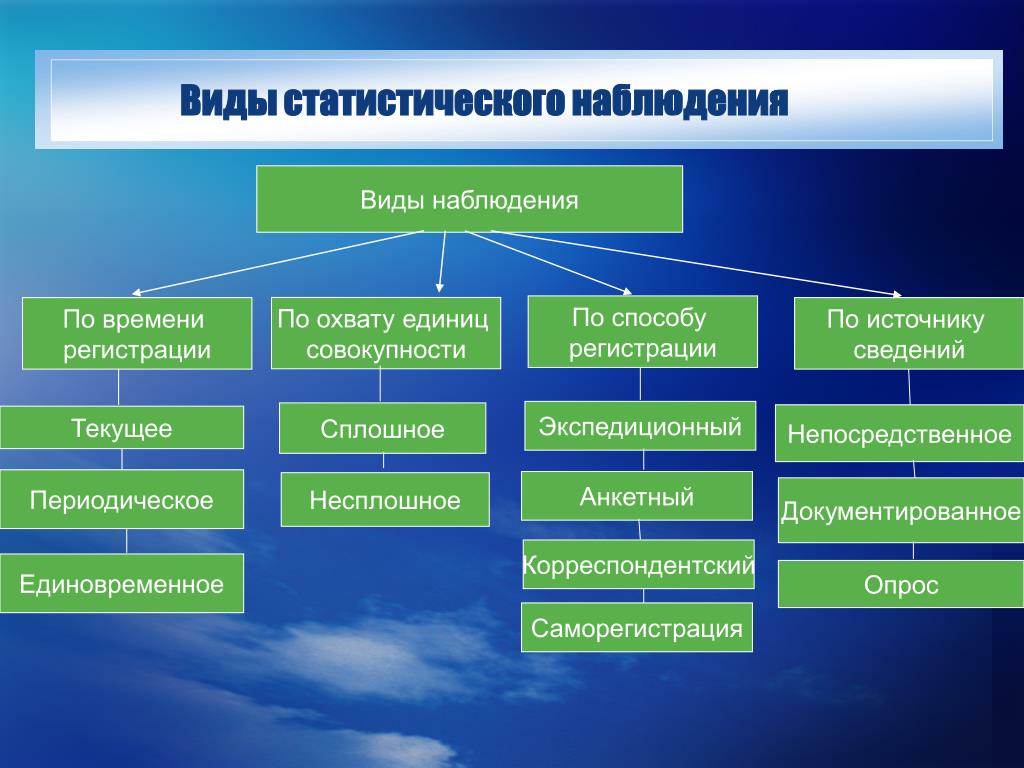
2.4. Виды и способы наблюдения
С точки зрения полноты охвата учетом фактов статистическое наблюдение может быть сплошным и несплошным. Сплошное наблюдение имеет основной задачей полный учет всех единиц совокупности, составляющих изучаемое явление.
Так, в статистике продукции промышленности основная задача – полный учет всей производственной продукции на всех предприятиях, при переписи населения – полный учет всех жителей данной страны.
Несплошное наблюдение охватывает лишь часть единиц изучаемого явления. Эта часть может быть выбрана по разному. Поэтому несплошное наблюдение можно подразделить на способ основного массива, выборочное и монографическое.
Обследование основного массива – это наблюдение за частью наиболее крупных единиц, занимающих преобладающий удельный вес в изучаемой совокупности. Так динамика цен исследуется по наиболее крупным городам или наиболее крупным оптовым и розничным рынкам.
При выборочном наблюдении из всей массы совокупности по принципу случайности отбирают единицы для обследования, а результаты изучения переносят на всю совокупность. Так изучается качество значительного вида выпускаемой продукции (подробно этот метод изложен в соответствующей теме).
Монографическое наблюдение – это подробное описание отдельных единиц наблюдения в статистической совокупности. Эти единицы должны быть типичными. Например, описание семьи безработного, или фермерского хозяйства.
По времени регистрации фактов статистические наблюдения подразделяются на текущие, периодические и единовременные.
Текущие наблюдения осуществляются непрерывно, все факты учитываются по мере их возникновения. Например, в кассе банка ежедневно учитывают торговую выручку предприятий. На основании данных текущего наблюдения составляется статистическая отчетность.
Периодические наблюдения проводятся регулярно, через определенные периоды времени. Вся представляемая статистическая отчетность является строго периодической (месячная, квартальная, годовая).
Единовременное (разовое) наблюдение проводят нерегулярно, по мере необходимости получения сведений. Примером единовременного наблюдения может служить обследование товаров, соответствие лицензиям на мелкооптовых рынках города.
По способам регистрации данных различают непосредственное наблюдение, документированное наблюдение и опрос.
· При непосредственном наблюдении сведения получают путем личного осмотра, подсчета и измерения.
· При документированном наблюдении сведения регистрируются на основе документов. Документированный отчет показателей хозяйственной деятельности предприятий лежит в основе статистической отчетности.
Существует несколько способов опроса:
а) экспедиционный способ, при котором специально выделенное лицо (регистратор) заполняет бланк со слов опрашиваемого. Применяется при проведении переписи населения в нашей стране;
б) способ саморегистрации, при котором бланк заполняет сам опрашиваемый под наблюдением регистратора. Применяется при обследовании бюджетов семьи;
в) корреспондентский способ, при котором статистическая организация высылает в определенный адрес бланк обследования с указаниями порядка его заполнения. Заполненный бланк возвращается статистической организации. Этим способом представляется статистическая отчетность предприятий и организаций.
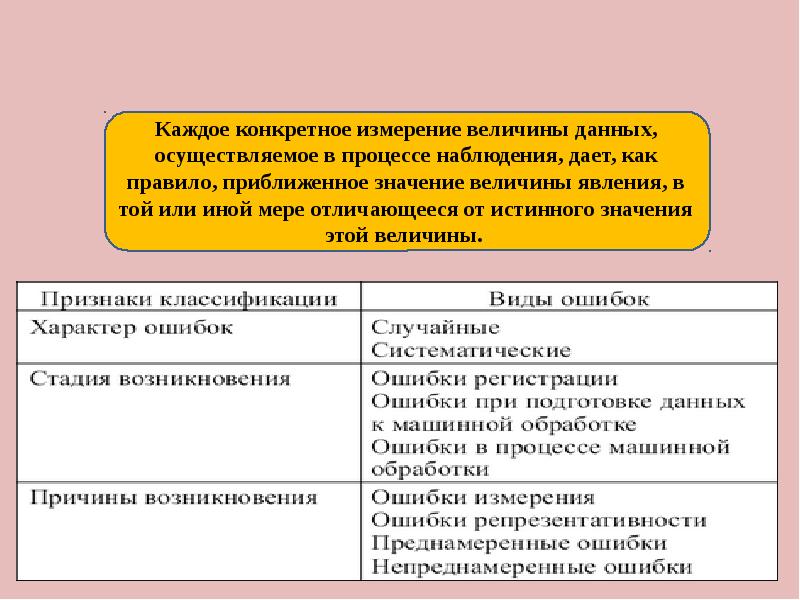
2.5. Ошибки статистического наблюдения
В ходе наблюдения могут возникнуть погрешности, которые называются ошибками наблюдения и количественно определяются разницей между размером показателя, определенного в результате статистического наблюдения, и действительным его размером.
Различают две группы ошибок статистического наблюдения – ошибки регистрации и ошибки репрезентативности (представительности). Первые ошибки возникают вследствие неправильного установления фактов или ошибочной их записи (регистрации) в условиях любого наблюдения, вторые присущи лишь выборочному наблюдению.
Ошибки регистрации по источнику происхождения можно подразделить на следующие:
1) преднамеренные (злостные),
2) непреднамеренные.
Люди также интересуются этой лекцией: 27 Ветеринарно-санитарная экспертиза рыбы при заболеваниях различной этиологии.
1. Преднамеренные ошибки регистрации возникают в результате преднамеренного искажения сведений лицами, дающими их. Преднамеренные ошибки являются систематическими, они могут быть или в сторону завышения или в сторону занижения. Они могут грубо искажать действительное положение. Поэтому преднамеренные ошибки требуют сплошного контроля. Известно, что в РФ наблюдается массовое сокрытие фирмами прибыли от налогообложения. Программа статистического наблюдения предусматривает проверку расчетов прибыли налоговой инспекцией на каждом предприятии. Законом предусматриваются экономические и административные меры, применяемые к предприятиям или лицам, включая уголовную ответственность, за злостные ошибки.
Программа статистического наблюдения предусматривает проверку расчетов прибыли налоговой инспекцией на каждом предприятии. Законом предусматриваются экономические и административные меры, применяемые к предприятиям или лицам, включая уголовную ответственность, за злостные ошибки.
2. Непреднамеренные ошибки в свою очередь подразделяются на следующие:
· Случайные ошибки чаще связаны с невнимательностью регистратора, небрежностью в заполнении документации, неточностью измерительных приборов и т.п. При достаточно большом числе зарегистрированных явлений они могут нейтрализовать друг друга. Одной из важнейших задач статистики является принятие строгих мер для максимального исключения ошибок. К таким мерам относятся тщательный подбор квалифицированных кадров, их обучение и повседневный контроль в ходе работы, проверки измерительных приборов, проведение массово-разъяснительной работы среди населения (при наблюдениях, обращенных к населению).
· Непреднамеренные систематические ошибки возникают в самых различных ситуациях, например, при округлении признака в большую или меньшую сторону. Или при изучении бюджетов семей выясняется, что некоторые виды расходов забываются. Такие ошибки требуют корректировки в соответствии с особенностями явлений и процессов. Систематические – это также ошибки округления возраста.
Или при изучении бюджетов семей выясняется, что некоторые виды расходов забываются. Такие ошибки требуют корректировки в соответствии с особенностями явлений и процессов. Систематические – это также ошибки округления возраста.
Проверка доброкачественности собранного статистического материала, выявление ошибок регистрации (преимущественно случайных) осуществляется посредством
На основе счетного контроля проверяются итоги и расчет показателей, четко устанавливается наличие ошибки. Логический контроль проводится путем сопоставления полученных данных с другими известными признаками, показателями. Возможно сопоставление за прошлый период по одной и той же единице, или за один и тот же период с данными по другой единице наблюдения. В результате выявляются неправдоподобные случаи, т.
Статистическая информация об использовании объектов интеллектуальной собственности
ВАЖНО! Уважаемые респонденты! Для обеспечения требований безопасности доступ к Личному кабинету через браузер Internet Explorer 11 (и его более ранние версии) не поддерживается!
Для работы рекомендуем воспользоваться современными версиями браузеров : Google Chrome, Mozilla Firefox, Opera, Яндекс, Microsoft Edge и др.
| ЛИЧНЫЙ КАБИНЕТ РЕСПОНДЕНТА ПО ФОРМЕ № 4-НТ (ПЕРЕЧЕНЬ) | |||
Перейдите в Личный кабинет для регистрации и дальнейшей работы.
Телефоны для справок и консультаций по Личному кабинету и форме № 4-НТ (перечень):
(499)240-58-11, (499) 240-65-39 (с 9:30 до 18:15 мск)
Обращаем Ваше внимание, что с 20:00 до 00:00 мск на странице Личного кабинета могут проводиться профилактические работы .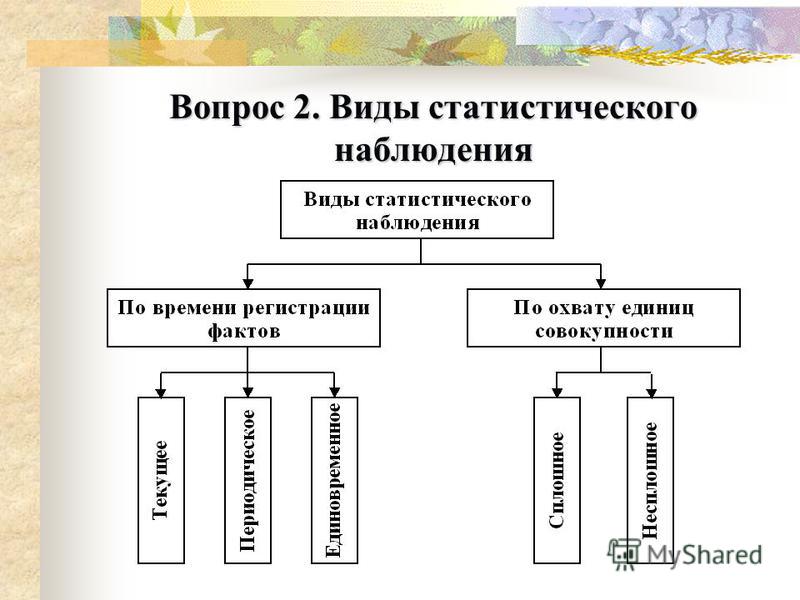
Статистические данные являются ценным источником информации для удовлетворения потребностей органов власти и управления, реального сектора, бизнес-сообщества, научной общественности, средств массовой информации и населения в достоверных сведениях о состоянии и перспективах развития инновационной деятельности в части использования объектов интеллектуальной собственности.
Статистический инструментарий
В соответствии с Федеральным планом статистических работ, утвержденным распоряжением Правительства Российской Федерации от 6 мая 2008 г. № 671-р (с изм.), Федеральная служба по интеллектуальной собственности (Роспатент) входит в число субъектов официального статистического учета. Роспатент уполномочен ежегодно осуществлять федеральное статистическое наблюдение за использованием результатов интеллектуальной деятельности (изобретений, полезных моделей, промышленных образцов, баз данных, программ для ЭВМ, топологий интегральных микросхем), в том числе сбор, обработку, формирование соответствующей автоматизированной базы данных и поддержание ее в актуальном состоянии.
В этих целях применяется форма федерального статистического наблюдения № 4-НТ (перечень) «Сведения об использовании объектов интеллектуальной собственности». Указанная форма является составной частью статистического инструментария, предназначенного для формирования информационных ресурсов о социально-экономическом положении страны. В ней приводятся сведения об использовании интеллектуальной собственности в отчетном году, эффективности ее использования, а также о патентовании за рубежом российских изобретений, полезных моделей и промышленных образцов.
Форма федерального статистического наблюдения №4-НТ (перечень) «Сведения об использовании объектов интеллектуальной собственности» и Указания по её заполнению утверждены по согласованию с Роспатентом приказом Федеральной службы государственной статистики от 14.07.2020 № 382.
Ответственность респондентов
Согласно пункту 6 Положения об условиях предоставления в обязательном порядке первичных статистических данных и административных данных субъектам официального статистического учета (утв.
За нарушение порядка представления статистической информации предусмотрена ответственность респондентов – отчитывающихся предприятий (организаций) на основании статьи 3 Закона РФ от 13 мая 1992 г. №2761-1 «Об ответственности за нарушение порядка представления государственной статистической отчетности» (с изм. от 30 декабря 2001 г.) и статьи 13.19 Кодекса Российской Федерации об административных правонарушениях от 30 декабря 2001 г. №195-ФЗ (действующая редакция).
Конфиденциальность данных
В соответствии с пунктом 7 статьи 2 Федерального закона от 29.11.2007 г. №282-ФЗ «Об официальном статистическом учете и системе государственной статистики в Российской Федерации» получаемые Роспатентом сведения по форме 4-НТ (перечень) «Сведения об использовании интеллектуальной собственности» относятся к первичным статистическим данным.
Роспатент гарантирует конфиденциальность представляемых предприятиями (организациями) данных об использовании конкретной интеллектуальной собственности. В соответствии с установленным порядком данные об использовании результатов интеллектуальной деятельности по охранным документам Российской Федерации могут быть сообщены третьим лицам только с разрешения респондентов — предприятий и организаций, предоставивших отчетные данные.
Справки об использовании изобретений, защищенных авторскими свидетельствами СССР, предоставляются заинтересованным физическим и юридическим лицам без каких-либо ограничений по отчетам, поступившим в Роспатент до 1999 года. Такого рода справки требуются авторам изобретений для решения вопросов о получении невыплаченного своевременно вознаграждения, а также для подтверждения их прав на получение нагрудного знака «Изобретатель СССР» и удостоверения «Ветеран труда».
Контакты
С 2020 года сведения по Форме № 4-НТ (перечень) в электронном виде принимаются только через Личный кабинет респондента Справки и консультации по всем вопросам, связанным с предоставлением формы федерального статистического наблюдения №4-НТ(перечень) «Сведения об использовании объектов интеллектуальной собственности», можно получить в Аналитическом центре Федерального института промышленной собственности по телефонам: +7(499) 240-58-11, +7(499) 240-65-39.
2020 год
2019 год
- Справка об использовании результатов интеллектуальной деятельности по федеральным округам Российской Федерации за 2019 год (по данным формы № 4-НТ (перечень) «Сведения об использовании интеллектуальной собственности») (PDF – 478 Kb)
- Справка об использовании результатов интеллектуальной деятельности по видам экономической деятельности за 2019 год (по данным формы № 4-НТ (перечень) «Сведения об использовании интеллектуальной собственности») (PDF – 401 Kb)
2018 год
2017 год
2016 год
2015 год
2014 год
2013 год
2012 год
2011 год
- Аналитические материалы по состоянию изобретательской активности в регионах РФ за 2011 г.
 (PDF – 455 Kb)
(PDF – 455 Kb) - Справка об использовании результатов интеллектуальной деятельности по федеральным округам РФ за 2011 г. (PDF – 72 Kb)
- Справка об использовании результатов интеллектуальной деятельности по видам экономической деятельности за 2011 г. (PDF – 72 Kb)
 (PDF – 455 Kb)
(PDF – 455 Kb)2010 год
2009 год
2008 год
2007 год
2006 год
2005 год
50. Объекты наблюдения и источники информации о населении. Статистика. Шпаргалка
Объектом наблюдения в статистике населения выступает население в целом. Единицей учета в статистике населения выступают человек, семья, домохозяйство и населенный пункт.
Источниками данных о населении являются следующие источники:
1) перепись населения, которая проводится раз в 10 лет;
2) отчеты предприятий и организаций;
3) текущий учет рождаемости, смертности, миграции населения;
4) выборочные обследования.
Выделяют следующие основные (абсолютные) демографические показатели статистики населения:
1) численность и состав населения;
2) число родившихся и умерших, число браков и разводов;
3) численность прибывших и выбывших из страны. Основные абсолютные показатели получают
при переписи населения — процедуре сбора демографических и социальных данных, которые описывают каждого человека данной страны, территории на определенный момент времени.
Существует четыре блока показателей при переписи населения:
1) демографические признаки: пол, возраст, брачное состояние;
2) экономические признаки: занятие, отрасли экономики, источники средств существования и т.д.;
3) характеристика уровня образования;
4) этнические признаки.
При переписи населения выделяют две следующие категории:
1) наличное население (категория населения) — объединение людей, которые на момент переписи находятся в жилых помещениях конкретного населенного пункта, а также тех людей, которые на данный момент времени находятся вне дома, но на территории того же населенного пункта;
2) постоянное население — категория населения, объединяющая людей, для которых данный населенный пункт (или территория) представляет собой место обычного проживания в настоящее время. К постоянному населению относятся студенты и учащиеся со сроком обучения более 6 месяцев и все другие, не имеющие другого постоянного местожительства. Относительными показателями статистики населения являются следующие показатели:
К постоянному населению относятся студенты и учащиеся со сроком обучения более 6 месяцев и все другие, не имеющие другого постоянного местожительства. Относительными показателями статистики населения являются следующие показатели:
1) демографическая нагрузка — показатель, характеризующий отношение общего числа детей, или лиц пенсионного возраста, или их общей совокупности к численности населения трудоспособного возраста. Эти показатели используются при расчете затрат, необходимых для пенсионного обеспечения и расходов на содержание детей, а также при разработке мероприятий по социальному обеспечению и рациональному использованию трудовых ресурсов;
2) показатели объема миграции:
а) число миграции;
б) число мигрантов;
3) показатели интенсивности миграции характеризуют частоту перемены местожительства в совокупности населения за определенный период.Метод оценки процесса рандомизированного наблюдения за населением (PROP): использование систематических наблюдений за жильем на участках улиц для создания эпидемиологических выборок населения на уровне домохозяйств | International Journal of Health Geographics
Наша цель состояла в том, чтобы построить и уточнить основу выборки в контексте уменьшающейся городской среды, используя систематические наблюдения за сегментами улиц. Мы искали случайную совокупность домохозяйств, и для этого мы намеренно преувеличили выборку Северного Флинта , потому что это район города с наибольшим количеством вакансий, наибольшим количеством временного населения, наиболее серьезным сокращением инвестиций с течением времени (в основном в форме бегства белых). ), негативное клеймо на региональном уровне, и находится в центре внимания стратегии грантов местного фонда [2, 4, 8, 12, 13].
Мы искали случайную совокупность домохозяйств, и для этого мы намеренно преувеличили выборку Северного Флинта , потому что это район города с наибольшим количеством вакансий, наибольшим количеством временного населения, наиболее серьезным сокращением инвестиций с течением времени (в основном в форме бегства белых). ), негативное клеймо на региональном уровне, и находится в центре внимания стратегии грантов местного фонда [2, 4, 8, 12, 13].
Мы разработали четырехэтапный процесс рандомизации населения (PROP), обобщенный на рис. 1. На первом этапе мы использовали самые последние данные переписи населения (2010 г.), чтобы установить необходимый размер выборки для исследования состояния здоровья населения. для каждой области. Чтобы получить 1% выборки от всего населения Флинта, мы определили, что для этого исследования подходит случайная выборка из 350 домохозяйств для всего города вместе с дополнительными 50 домохозяйствами в Северном Флинте. Дополнительные 50 домохозяйств были добавлены в Норт-Флинт, чтобы получить достаточную статистическую мощность для выявления различий между Северным и Южным Флинтом. Мы определили, что из 400 опрошенных домохозяйств во Флинте, в каждом из которых в среднем проживает 2,5 человека, наша выборка даст ~ 1000 жителей. Мы использовали двухуровневый подход, используя оценки численности населения по переписным участкам и группам переписных кварталов (CBG). Во-первых, мы взяли пропорцию населения на переписной участок (население переписного участка/общее население Флинта), умножили его на 350 и округлили до ближайшего целого числа. Сумма по всем переписным участкам должна была равняться 350 и требовала небольшой корректировки в связи с округлением.Мы взяли пропорцию населения блока переписи (население CBG/население CT) и умножили на целое число из предыдущего шага, снова округлив, чтобы общее количество снова равнялось 350. Это привело к желаемому размеру выборки в 350 человек, к которой мы добавили избыточную выборку из 50 домохозяйств в Норт-Флинте.
Мы определили, что из 400 опрошенных домохозяйств во Флинте, в каждом из которых в среднем проживает 2,5 человека, наша выборка даст ~ 1000 жителей. Мы использовали двухуровневый подход, используя оценки численности населения по переписным участкам и группам переписных кварталов (CBG). Во-первых, мы взяли пропорцию населения на переписной участок (население переписного участка/общее население Флинта), умножили его на 350 и округлили до ближайшего целого числа. Сумма по всем переписным участкам должна была равняться 350 и требовала небольшой корректировки в связи с округлением.Мы взяли пропорцию населения блока переписи (население CBG/население CT) и умножили на целое число из предыдущего шага, снова округлив, чтобы общее количество снова равнялось 350. Это привело к желаемому размеру выборки в 350 человек, к которой мы добавили избыточную выборку из 50 домохозяйств в Норт-Флинте.
Краткое изложение четырех этапов метода PROP
Чтобы создать передискретизацию для Норт-Флинта (определяемую как область к северу от Флашинг-Роуд и к западу от реки Флинт, создавая разделительную линию, показанную зеленым цветом на рис. 2) тот же метод использовался для определения того, сколько из 50 дополнительных проб будет отнесено к каждой CBG. Общая численность населения Северного Флинта составляет 37 086 человек [18]. Мы взяли долю населения переписного участка только для Северного Флинта (население CT/37 086), умножили ее на 50, округлили до ближайшего целого числа и убедились, что сумма равна 50. Затем мы взяли долю населения CBG (CBG Pop/CT Pop), умножил его на целое число из предыдущего шага, округлил и убедился, что сумма снова равна 50.Затем 50 домохозяйств в Северном Флинте были добавлены к первоначальным 350 в рамках CBG. На рис. 2 CBG показаны в виде полигонов с соответствующим размером выборки в каждом CBG, отображаемым в виде числа внутри полигона.
2) тот же метод использовался для определения того, сколько из 50 дополнительных проб будет отнесено к каждой CBG. Общая численность населения Северного Флинта составляет 37 086 человек [18]. Мы взяли долю населения переписного участка только для Северного Флинта (население CT/37 086), умножили ее на 50, округлили до ближайшего целого числа и убедились, что сумма равна 50. Затем мы взяли долю населения CBG (CBG Pop/CT Pop), умножил его на целое число из предыдущего шага, округлил и убедился, что сумма снова равна 50.Затем 50 домохозяйств в Северном Флинте были добавлены к первоначальным 350 в рамках CBG. На рис. 2 CBG показаны в виде полигонов с соответствующим размером выборки в каждом CBG, отображаемым в виде числа внутри полигона.
(основная методология FCHES)
Флинт, штат Мичиган, сегментировано по группам блоков переписи, с №. домохозяйства, необходимые для случайной выборки населения
На втором этапе мы экспортировали пространственные данные сегментов улиц в Microsoft Excel и использовали случайную функцию для случайного выбора 400 сегментов улиц во всех CBG (на основе алгоритма на первом этапе).
На третьем этапе мы направили оценщиков для проведения личных наблюдений за признаками жилья во всех жилищах на случайно выбранных 400 сегментах улиц. Ко всем типам жилья, включая дома на одну семью, жилые комплексы, трейлерные парки и поселки престарелых, относились одинаково: если жилье находилось на выбранном участке улицы и было видно с обочины, оценщики искали признаки жилья. Поскольку оценщикам не разрешалось входить в частную собственность, они не могли пытаться оценить жилье в отдельных квартирах.(Восемь) оценщиков-резидентов Флинта были выбраны из-за их комфорта и знакомства с городом. Оценщики использовали форму в EpiCollect v5 [1], запрограммированную для документирования жилья на случайно выбранных сегментах улицы. Форма содержала начальные и конечные вопросы, предназначенные для управления логистикой. Например, первый вопрос в оценке был «Кто сегодня водил?» — вопрос, заданный только для управления отправкой возмещения расходов на пробег. Точно так же последний вопрос оценки «Чувствовали ли вы себя в безопасности на этом отрезке улицы» использовался для определения того, какие оценщики чувствовали себя комфортно во всех районах города. Помимо этих вопросов, ориентированных на логистику, форма содержала два вопроса, представляющих интерес для настоящего исследования. Первый: «Есть ли обитаемые жилища?» определяли, получили ли оценщики второй вопрос «Есть ли на этом квартале хотя бы 2 жилых дома?»
Помимо этих вопросов, ориентированных на логистику, форма содержала два вопроса, представляющих интерес для настоящего исследования. Первый: «Есть ли обитаемые жилища?» определяли, получили ли оценщики второй вопрос «Есть ли на этом квартале хотя бы 2 жилых дома?»
Для завершения оценки пары оценщиков отправились вместе в светлое время суток по назначенному начальному адресу. Они шли вместе (ища признаки проживания в жилищах) по отрезку улицы, пока не доходили до пересекающейся улицы или тупика, поворачивались на 180° и возвращались в исходную точку.Они заполняли форму EpiCollect на электронных планшетах во время ходьбы. Оценки были завершены в январе-марте 2018 года. Оценщики прошли обучение в течение 1 часа, которое включало ориентацию на EpiCollect, ориентацию на навигацию с помощью электронного планшета, меры безопасности, процедуры ответов на вопросы людей на участках улицы. Обучение также включало в себя рекомендации по поиску признаков жилья (например, освещение, расчищенный снег, детские игрушки во дворе, видимость людей в окнах или выставленный для сбора мусор). Оценщикам было предложено использовать свои субъективные рассуждения при оценке жилья. Оценщикам было приказано не обсуждать жилье при проведении оценок. Использовался метод одновременного тестирования, и домохозяйства считались заселенными, если на это указывал хотя бы один оценщик.
Оценщикам было предложено использовать свои субъективные рассуждения при оценке жилья. Оценщикам было приказано не обсуждать жилье при проведении оценок. Использовался метод одновременного тестирования, и домохозяйства считались заселенными, если на это указывал хотя бы один оценщик.
Для четвертого шага, если на любом случайно выбранном отрезке улицы на третьем шаге жилая площадь была ≤ 1 (т. е. только одно домохозяйство во всем квартале оказалось заселенным), мы завершали наблюдения на множестве вторичных, случайно выбранных отрезков улиц.Мы установили порог двух или более населенных домохозяйств, потому что нашей конечной целью было проведение обследования здоровья населения. Мы предполагали, что 50% домохозяйств могут отказаться. Если бы на первом сегменте улицы было только одно жилое домохозяйство, необходимо было бы иметь резервную копию на случай, если жители единственного населенного домохозяйства из первого сегмента улицы откажутся. Таким образом, когда основных сегментов улиц было менее двух, мы случайным образом выбирали и наблюдали резервные (второстепенные, третичные и т. д.) сегменты улиц в пределах CBG до тех пор, пока на сегменте улицы не наблюдалось по крайней мере два занятых дома.Данные были экспортированы из EpiCollect, а описательная статистика была сгенерирована с использованием статистического программного обеспечения R. Мы провели пропорциональную (порядковую) логистическую регрессию, чтобы определить, как уровень оценки PROP коррелирует с данными переписи о вакансиях для всех CBG в городе.
д.) сегменты улиц в пределах CBG до тех пор, пока на сегменте улицы не наблюдалось по крайней мере два занятых дома.Данные были экспортированы из EpiCollect, а описательная статистика была сгенерирована с использованием статистического программного обеспечения R. Мы провели пропорциональную (порядковую) логистическую регрессию, чтобы определить, как уровень оценки PROP коррелирует с данными переписи о вакансиях для всех CBG в городе.
Описательная статистика
Описательная статистика Как упоминалось ранее, частотное распределение содержит все наблюдения для конкретной выборки, которую мы называем
в качестве исходных данных .Только в редких случаях мы представляем необработанные данные. Цель описательной статистики состоит в том, чтобы
обеспечивают средства обобщения информации, содержащейся в частотном распределении. Две самые важные части
Информация, которая должна быть предоставлена для любого распределения, — это центральная тенденция распределения и дисперсия дистрибутива. Меры центральной тенденции по существу описывают положение распределения на
Ось X (значение измеряемой переменной), тогда как меры дисперсии описывают, насколько разбросаны наблюдения по оси X.В ряде случаев
форма распределения, особенно степень симметрии, также будет важна для описания.
Меры центральной тенденции по существу описывают положение распределения на
Ось X (значение измеряемой переменной), тогда как меры дисперсии описывают, насколько разбросаны наблюдения по оси X.В ряде случаев
форма распределения, особенно степень симметрии, также будет важна для описания.
(Глава 3 в Заре, 2010 г.)
Если конкретное распределение данных расположено на оси X (которая представляет значения переменной, измеренное) суммируется ссылкой на некоторое значение, связанное с приблизительным центром распределения. 3 стандарт мерами центральной тенденции являются среднее , медиана и мода .
Среднее значение — это просто среднее арифметическое наблюдений, сводная статистика, с которой мы все знакомы. Для этого По этой причине мы будем использовать формулу для расчета среднего значения выборки, чтобы указать некоторые обозначения, которые мы будем использовать. на протяжении семестр:
Мы будем использовать Y для обозначения значения наблюдения. Общее количество наблюдений, т. е. размер выборки, будем обозначать как n.Когда
мы хотим идентифицировать конкретное наблюдение, мы будем использовать нижний индекс. За
например, Y 4 будет означать 4-е наблюдение. ∑Y — обозначение, которое мы будем использовать для суммы всех
наблюдения
(Y 1 + Y 2 + Y 3 +… Y n ). В этом случае нижний индекс для Y будет указывать на конкретный
группа наблюдений,
например, ∑Y контроль будет означать сумму всех наблюдений для контрольной группы.) над
Верх
это указывает на то, что это оценка. Таким образом, предыдущую формулу можно прочитать как «выборочное среднее является оценкой
средняя численность населения».
Общее количество наблюдений, т. е. размер выборки, будем обозначать как n.Когда
мы хотим идентифицировать конкретное наблюдение, мы будем использовать нижний индекс. За
например, Y 4 будет означать 4-е наблюдение. ∑Y — обозначение, которое мы будем использовать для суммы всех
наблюдения
(Y 1 + Y 2 + Y 3 +… Y n ). В этом случае нижний индекс для Y будет указывать на конкретный
группа наблюдений,
например, ∑Y контроль будет означать сумму всех наблюдений для контрольной группы.) над
Верх
это указывает на то, что это оценка. Таким образом, предыдущую формулу можно прочитать как «выборочное среднее является оценкой
средняя численность населения».
Делая оценки, мы гораздо больше заботимся о точности (близости к фактическому значению), чем о точности
(близость оценок друг к другу). Чрезвычайно важным для получения точности в наших оценках является использование
оценщики, которые
беспристрастный. Непредвзятый оценщик может как переоценить, так и недооценить, в то время как предвзятый оценщик будет иметь тенденцию к занижению.
постоянно переоценивать или постоянно недооценивать.Запишите это… вас попросят оценить предвзятость.
Непредвзятый оценщик может как переоценить, так и недооценить, в то время как предвзятый оценщик будет иметь тенденцию к занижению.
постоянно переоценивать или постоянно недооценивать.Запишите это… вас попросят оценить предвзятость.
Мы можем использовать наши новообретенные навыки чтения частотных распределений (если вы чувствуете, что не умеете, просмотрите материал прошлой недели) изучить поведение среднего значения выборки как оценки среднего значения генеральной совокупности. Следующий график был получен путем рисования (наугад) 1000 выборок по 50 наблюдений в каждой из статистической совокупности, где μ=10. Этот среднее значение генеральной совокупности, равное 10, было вычтено из каждого среднего значения выборки (таким образом, значение 0 указывало бы на то, что среднее значение выборки и средние значения популяции были одинаковыми), рассчитанные по 1000 выборкам для получения следующего распределения:
Примечание. Эти данные были созданы как объект «smean» в этом
Программа R
Эти данные были созданы как объект «smean» в этом
Программа R
Вопрос 1: Судя по этим данным, является ли среднее значение выборки объективной оценкой среднего значения генеральной совокупности? Обосновать ответ.
Две другие меры центральной тенденции, медиана и мода, вернут значения, аналогичные среднему для распределения, которые симметричны, как и выше, но могут передавать различную, а иногда и важную информацию применительно к асимметричным распределениям. Медиана — это среднее наблюдение, когда наблюдения выровнены по возрастанию. (или по убыванию) по величине их значений. Это может быть полезной мерой, потому что 50% ваших наблюдений выше этого значения, и 50% ваших наблюдений находятся ниже этого значения.Мода – это наблюдение, которое происходит чаще всего часто, т. е. пик частотного распределения.
Для симметричных распределений среднее значение, медиана и мода должны сходиться к одному и тому же значению. Распределение, которое Далее показаны наблюдения за скоростью питания личинок плодовой мухи ( Drosophila melanogaster ), измеренной путем подсчета число сокращений пищевого аппарата (головоглоточных склевитов) в течение минуты.
Распределение норм кормления является (более или менее) симметричным, в результате чего среднее значение выборки, медиана выборки и режим выборки всего примерно 85 сокращений в минуту. Для симметричных распределений все три меры передают в основном одну и ту же информацию. Когда распределения асимметричны, вы должны тщательно продумать, что информацию, которую вы хотите передать при выборе меры центральной тенденции. Следующий дистрибутив был создан изучение дистрибутива Vica sp.(вика), вьющееся бобовое растение, растущее на лужайке за пределами общежития Pacer Commons на территории кампуса, путем подсчета количества особей. присутствует в серии 0,5 м 2 квадраты:
Как видите, это распределение имеет положительную (правую) асимметрию, что приводит к различным значениям выборочного среднего,
выборочная медиана и выборочная мода. Отчет о среднем значении выборки даст значение, которое не часто встречается в качестве наблюдения,
и поэтому вам придется взвесить, является ли частота более важной частью информации, чем положение
распределение для
вопрос, которым вы занимаетесь.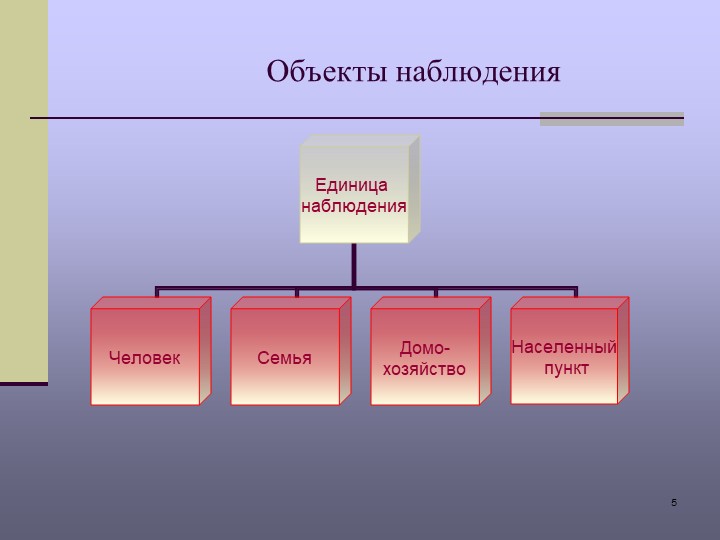
В некоторых случаях распределение может свидетельствовать о более чем одной связанной группе наблюдений, например, распределение экзаменационных оценок, показанных ниже:
В таких случаях выборочное среднее и медиана плохо отражают модель, и следует указывать оба режима (этот тип распределение называется бимодальным).
Хотя важно признать существование и потенциальное использование других мер центральной тенденции, это будет редкий случай, когда сообщается мера центральной тенденции, отличная от выборочного среднего.
(Глава 4 в Заре, 2010 г.)
Хотя положение распределения по оси X является важной частью информации для передачи, релевантность этой меры зависит от того, насколько широко это распределение, то есть количество вариаций этой переменной, особенно при сравнении между или среди дистрибутивов. Меры рассеивания индексы того, насколько разбросаны наблюдения по оси X.
Простейшей мерой дисперсии является диапазон , который включает отчет о наименьшем и наибольшем наблюдении, или
разница между ними. Эта мера очень чувствительна к выбросам , то есть к необычно высоким или низким значениям.
относительно других наблюдений. Хотя нетрудно найти рекомендации по исключению выбросов из набора
данные, если не ясно, что наблюдение невозможно, например, температура тела человека 183 градуса С, или известно
что произошла ошибка в измерении, всегда следует воздерживаться от удаления таких наблюдений (см. раздел 2.5 в главе 2).
вашего текста).
Эта мера очень чувствительна к выбросам , то есть к необычно высоким или низким значениям.
относительно других наблюдений. Хотя нетрудно найти рекомендации по исключению выбросов из набора
данные, если не ясно, что наблюдение невозможно, например, температура тела человека 183 градуса С, или известно
что произошла ошибка в измерении, всегда следует воздерживаться от удаления таких наблюдений (см. раздел 2.5 в главе 2).
вашего текста).
Причина, по которой диапазон чувствителен к выбросам, заключается в том, что он основан только на двух ваших наблюдениях. Очевидно, мера дисперсия, основанная на всех ваших наблюдениях, была бы более ценной и лучше оправдала бы всю тяжелую работу, проделанную в сбор этих наблюдений. Наше новообретенное и глубокое понимание центральной тенденции предполагает одну возможную мера: среднее расстояние наблюдений от центра распределения.
Расстояние наблюдения от среднего значения выборки можно рассчитать путем вычитания среднего значения выборки из наблюдения следующим образом:
Это значение, обозначаемое строчной буквой y, называется отклонением . Интуитивно тогда среднее расстояние будет
сумма отклонений, ∑y, деленная на количество наблюдений, n. Эту проблему можно проиллюстрировать, изучив
следующая таблица результатов викторины из 2 отдельных разделов класса биологии:
Интуитивно тогда среднее расстояние будет
сумма отклонений, ∑y, деленная на количество наблюдений, n. Эту проблему можно проиллюстрировать, изучив
следующая таблица результатов викторины из 2 отдельных разделов класса биологии:
Поскольку среднее значение выборки является математическим центром наблюдений, сумма отклонений всегда (в пределах ошибка округления) равняться нулю. Два распределения баллов по тестам явно различаются, но средние отклонения не предоставит никакой информации об этих различиях.
Решение, которое мы применим, состоит в том, чтобы возвести отклонения в квадрат, сделав все разности положительными. Обозначение, которое мы
будет использовать для квадрата отклонения будет y 2 , так что ∑y 2 будет обозначать сумму возведенных в квадрат
отклоняется. Сумма квадратов отклонений обычно называется суммой квадратов и представляет собой значение, которое
занимают видное место практически во всех анализах, которые мы рассмотрим, поэтому убедитесь, что вы знакомы с тем, как
рассчитать его и то, что он представляет .
Применение этого к данных результатов викторины, мы видим, что сумма квадратов (∑y 2 ) лучше отражает различия между двумя дистрибутивами:
Разделив сумму квадратов отклонений на количество наблюдений (∑y 2 /n), мы получим среднее квадрат расстояния наблюдений от среднего значения наблюдений. Хотя должно быть интуитивно понятно, что это хорошо мера разброса наблюдений (кроме использования квадратов расстояний, к которым мы вскоре обратимся), мы не можем упустить из виду тот факт, что целью получения этого значения из выборки является оценка того же параметра для статистическое население.Таким образом, важно установить, приведет ли вычисление этого значения, как описано, к смещению. при оценке того же параметра населения.
Расчет среднего квадрата расстояния наблюдений от среднего для статистической совокупности, т. е. с использованием
каждое существующее наблюдение является параметром, который мы называем дисперсией генеральной совокупности и обозначаем с помощью символа:
о 2 . К сожалению, использование того же расчета на основе выборочных данных дает смещенную оценку σ 2 .Следующее распределение было получено путем взятия 1000 случайных выборок из статистической совокупности с μ = 10 и
σ 2 =4, и вычисление среднего квадрата расстояния наблюдений из среднего значения наблюдений для
каждый образец. Для каждой выборки дисперсия совокупности (σ 2 ) вычиталась из среднего квадрата расстояния
наблюдений из среднего значения выборки ((∑y 2 /n)-σ 2 ) для получения значений, показанных ниже, так что
оценка, соответствующая дисперсии населения, даст значение 0:
К сожалению, использование того же расчета на основе выборочных данных дает смещенную оценку σ 2 .Следующее распределение было получено путем взятия 1000 случайных выборок из статистической совокупности с μ = 10 и
σ 2 =4, и вычисление среднего квадрата расстояния наблюдений из среднего значения наблюдений для
каждый образец. Для каждой выборки дисперсия совокупности (σ 2 ) вычиталась из среднего квадрата расстояния
наблюдений из среднего значения выборки ((∑y 2 /n)-σ 2 ) для получения значений, показанных ниже, так что
оценка, соответствующая дисперсии населения, даст значение 0:
Примечание. Эти данные были созданы как объект «pvd» в этом Программа R
Вопрос 2: В каком направлении наблюдается смещение среднего квадрата расстояния наблюдений от выборки среднее значение как оценка σ 2 ?
Приведенное выше распределение предполагает, что для получения несмещенной оценки σ 2 из
Пример данных. В этом случае исправление простое, включающее использование n-1 в знаменателе вместо n. То
полученная формула вычисляет параметр, который мы называем выборочной дисперсией , обозначаемый как s 2 :
В этом случае исправление простое, включающее использование n-1 в знаменателе вместо n. То
полученная формула вычисляет параметр, который мы называем выборочной дисперсией , обозначаемый как s 2 :
Примечание: Дополнительная серия выпускалась как объект «СВД» в эта программа R
Из этого распределения видно, что поправка на выборочную дисперсию устраняет систематическую ошибку в оценке.Таким образом, мы будем использовать выборочную дисперсию (s 2 ) в качестве наилучшей оценки дисперсии генеральной совокупности (σ 2 ):
Единственная проблема, которую можно с разбросом принять за показатель разброса данных, заключается в том, что единицы
в квадрате относительно значений наблюдений и, следовательно, среднего. Решение этого, как вы можете себе представить,
простой: просто возьмите квадратный корень из дисперсии. Это дает значение, называемое стандартом .
отклонение , которое для выборки обозначим как s, а для совокупности – как σ.Очевидно (по крайней мере, я надеюсь
что это очевидно), квадратный корень выборочной дисперсии (вычисленный с n-1 в качестве знаменателя) даст
стандартное отклонение выборки (с) и квадратный корень из дисперсии генеральной совокупности (рассчитанный с использованием n в качестве знаменателя)
даст стандартное отклонение населения (σ). Учитывая, что мы почти всегда будем работать с образцами, мы
будет использовать стандартное отклонение выборки в качестве нашей оценки стандартного отклонения населения:
Решение этого, как вы можете себе представить,
простой: просто возьмите квадратный корень из дисперсии. Это дает значение, называемое стандартом .
отклонение , которое для выборки обозначим как s, а для совокупности – как σ.Очевидно (по крайней мере, я надеюсь
что это очевидно), квадратный корень выборочной дисперсии (вычисленный с n-1 в качестве знаменателя) даст
стандартное отклонение выборки (с) и квадратный корень из дисперсии генеральной совокупности (рассчитанный с использованием n в качестве знаменателя)
даст стандартное отклонение населения (σ). Учитывая, что мы почти всегда будем работать с образцами, мы
будет использовать стандартное отклонение выборки в качестве нашей оценки стандартного отклонения населения:
Теперь давайте попрактикуемся в вычислении некоторых описательных статистик для некоторых фактических данных.Загрузите книгу Excel для этого недельное упражнение ЗДЕСЬ.
Данные о птицах
Первый рабочий лист (птицы) содержит данные из примера 3. 3 в вашем учебнике (стр. 25). Это позволит вам
дважды проверьте свои расчеты и те, которые Excel делает за вас.
3 в вашем учебнике (стр. 25). Это позволит вам
дважды проверьте свои расчеты и те, которые Excel делает за вас.
В ячейке F15 введите формулу для расчета среднего значения выборки для видов B:
=СУММ(F3:F12)/СЧЁТ(F3:F12)
Введите «среднее» в ячейку, непосредственно примыкающую к ячейке, содержащей среднее значение выборки (G15), чтобы потом не запутаться (и чтобы я не запутался, когда буду просматривать вашу таблицу).В Excel есть функция вычислить медиану, которую мы будем использовать в ячейке F16:
=МЕДИАНА(F3:F12)
Добавьте метку для медианы в соседнюю ячейку, как вы делали это для среднего значения. Обратите внимание, что значение медианы не встречаются среди списка наблюдений. Причина этого в том, что при четном числе наблюдений мы интерполируйте между двумя средними наблюдениями, чтобы получить медианное значение. Теперь выделите 2 ячейки, содержащие формулы для среднего и медианы, используйте «Ctrl+c», чтобы скопировать ячейки, щелкните ячейку A15 и
используйте «Ctrl-v» для вставки. То чувство беспокойства, которое вы испытываете, является результатом вашего сознательного (или
подсознательно) признание того, что размеры выборки для двух групп наблюдений различаются. Вставка результатов формул
в расчетах для видов А, которые включают пустую ячейку. Используйте «F2», чтобы убедиться в этом.
То чувство беспокойства, которое вы испытываете, является результатом вашего сознательного (или
подсознательно) признание того, что размеры выборки для двух групп наблюдений различаются. Вставка результатов формул
в расчетах для видов А, которые включают пустую ячейку. Используйте «F2», чтобы убедиться в этом.
Вспомни слова, написанные дружескими буквами на каждый экземпляр «Автостопом по Галактике» : «Не паникуйте» (если вы еще не прочитали ни одну из 5 книг в этой трилогии, пожалуйста, исправьте это тревожное упущение как можно скорее).А пока возьмем объективный и аналитический подход к изучению последствий наших действий.
Поскольку существует нечетное количество наблюдений за продолжительностью жизни вида А, и поскольку эти наблюдения
были отсортированы в порядке возрастания значения, мы можем с первого взгляда увидеть, что на самом деле есть среднее наблюдение, и что
Значение
этого наблюдения соответствует значению медианы, рассчитанному Excel. Казалось бы, функция «МЕДИАНА»
игнорирует пустые ячейки.Мы можем убедиться, что то же самое верно для обеих функций «СУММ» и «СЧЁТ», пересчитав
означает использование функции «СРЕДНИЙ». Введите следующее в ячейку A17:
Казалось бы, функция «МЕДИАНА»
игнорирует пустые ячейки.Мы можем убедиться, что то же самое верно для обеих функций «СУММ» и «СЧЁТ», пересчитав
означает использование функции «СРЕДНИЙ». Введите следующее в ячейку A17:
=СРЕДНЕЕ(A3:A11)
Мы не только проверили, что некоторые важные функции игнорируют пустые ячейки, что немного облегчает жизнь. (потому что мы можем вставлять формулы), когда имеет дело с неравными размерами выборки, но мы также проверили, что функция «СРЕДНИЙ» следует формуле, которую мы узнали (или, что более вероятно, вспомнили) для среднего значения выборки.Чувствуете, как уходит напряжение?
Теперь мы собираемся вычислить дисперсию для обеих выборок. В ячейке G3 введите формулу для расчета отклоняться как:
=F3-F$15
Наличие привязки ($) для номера строки позволяет копировать формулу вниз для остальных наблюдений при ссылке
та же ячейка для среднего. Анкеровка
столбец не нужен, когда формула только копируется вниз, и оставление столбца незакрепленным позволит вам
скопируйте столбец в его
полноту, чтобы вычислить отклонения для наблюдений за видом B, потому что эталон будет соответствовать местоположению
образец означает. 2) в столбце Г, но
это хорошее напоминание о
шаги, которые мы обсуждали (и кроме того, я заставил вас поставить метки там, где нам нужно было бы вычислять суммы).
2) в столбце Г, но
это хорошее напоминание о
шаги, которые мы обсуждали (и кроме того, я заставил вас поставить метки там, где нам нужно было бы вычислять суммы).
Пора брать тренировочные колеса выключенный. Напомним формулу выборочной дисперсии:
Вы должны быть в состоянии рассчитать выборочную дисперсию, используя функцию «СУММ» и функцию «СЧЁТ». предположительно вы можете подсчитать наблюдения самостоятельно, но это будет хорошей практикой, когда мы используем большие размеры выборки.Просто убедитесь что вы используете круглые скобки в своей формуле, чтобы получить правильный порядок операций при вычитании 1 из счета, или вы будете вычитать 1 от дисперсии населения! Вы тоже должен иметь возможность чтобы повторить эти расчеты для вида A, вырезая и вставляя, если вы были осторожны со своими ссылками на ячейки.
Наконец, рассчитайте стандартное отклонение выборки для двух выборок. Чтобы найти квадратный корень значения в Excel, Функция «SQRT» используется как:
=КОРЕНЬ( значение )
Значение может быть фактическим числом или ячейкой для значения. Например, если отклонение вашей выборки находилось в
в ячейке C15 стандартное отклонение выборки может быть рассчитано как:
Например, если отклонение вашей выборки находилось в
в ячейке C15 стандартное отклонение выборки может быть рассчитано как:
= SQRT (C15)
Убедитесь, что маркированы как выборочная дисперсия, так и пример стандартного отклонения четко на вашем рабочем листе, и не забудьте сохранить свою работу!
Данные солнечной рыбы
Второй рабочий лист (рыба) содержит измерения массы и стандартной длины синежаберной солнечной рыбы.
( Lepomis macrochirus ) и гибриды синежаберной солнечной рыбы и зеленой солнечной рыбы ( Lepomis cynanellus ),
собранный из построенного пруда в округе Седжвик, штат Канзас.Эти измерения были использованы для
рассчитать «коэффициент состояния» (K), который представляет собой отношение массы к кубу длины (в см). Рыба с
большее значение для K будет иметь большую массу для данной длины. Поскольку у зеленых солнечных рыб зияние больше, и они, как правило,
чтобы быть более агрессивным, возник вопрос о том, может ли внедрение гибридов иметь негативные последствия. влияние на состояние синежаберных солнечных рыб.
влияние на состояние синежаберных солнечных рыб.
На следующем графике показано частотное распределение фактора состояния для обоих видов:
Должно быть сразу видно, что распределения подобны с точки зрения их центральных тенденций, но отличаются степенью дисперсии данных.
Вопрос 3. Рассчитайте среднее значение, дисперсию и стандартное отклонение обоих наборы данных факторов состояния и определить, отражают ли эти сводные статистические данные сходства и различия что можно наблюдать между две раздачи.
Перейдем к изучению симметрии и стандартной ошибки…
Комментарии, предложения и исправления направляйте по адресу: Derek Zelmer
Значение наблюдения по сравнению с ошибкой процесса при анализе глобальных популяций копытных
Turchin, P.Регулирование населения: старые аргументы и новый синтез. Динамика населения [Капучино Н. и Прайс П. (ред.)] [19–40] (Academic Press, Нью-Йорк, 1995).
и Прайс П. (ред.)] [19–40] (Academic Press, Нью-Йорк, 1995).
Брук, Б.В. и Брэдшоу, К.Дж.А. Достоверность доказательств зависимости плотности во временных рядах численности 1198 видов. Экология 87, 1445–1451, 10.1890/0012-9658(2006)87[1445:soefdd]2.0.co;2 (2006).
Артикул пабмед Google Scholar
Холиок, М.Выявление зависимости от плотности с задержкой во временных рядах данных. Ойкос 70, 296–304, 10.2307/3545641 (1994).
Артикул Google Scholar
Айвз, А. Р., Эбботт, К. С. и Зибарт, Н. Л. Анализ экологических временных рядов с помощью моделей ARMA (p, q). Экология 91, 858–871, 10.1890/09-0442.1 (2010).
Артикул пабмед Google Scholar
Уильямс, С. К., Айвз, А.Р. и Эпплгейт, Р. Д. Динамика популяции в разных географических ареалах: анализ временных рядов трех видов мелких игр. Экология 84, 2654–2667, 10.1890/03-0038 (2003).
Экология 84, 2654–2667, 10.1890/03-0038 (2003).
Артикул Google Scholar
Гордон И. Дж., Хестер А. Дж. и Феста-Бьянше М. Управление дикими крупными травоядными для достижения экономических, природоохранных и экологических целей. J Appl Ecol 41, 1021–1031, 10.1111/j.0021-8901.2004.00985.x (2004).
Артикул Google Scholar
Форчхаммер, М. К., Пост, Э., Стенсет, Н. К. и Боертманн, Д. М. Долгосрочные реакции динамики арктических копытных на изменения климатических и трофических процессов. Popul Ecol 44, 113–120, 10.1007/s101440200013 (2002).
Артикул Google Scholar
Jachmann, H. Сравнение воздушных и наземных учетов крупных африканских травоядных.J Appl Ecol 39, 841–852, 10.1046/j.1365-2664.2002.00752.x (2002).
Артикул Google Scholar
Морелле, Н.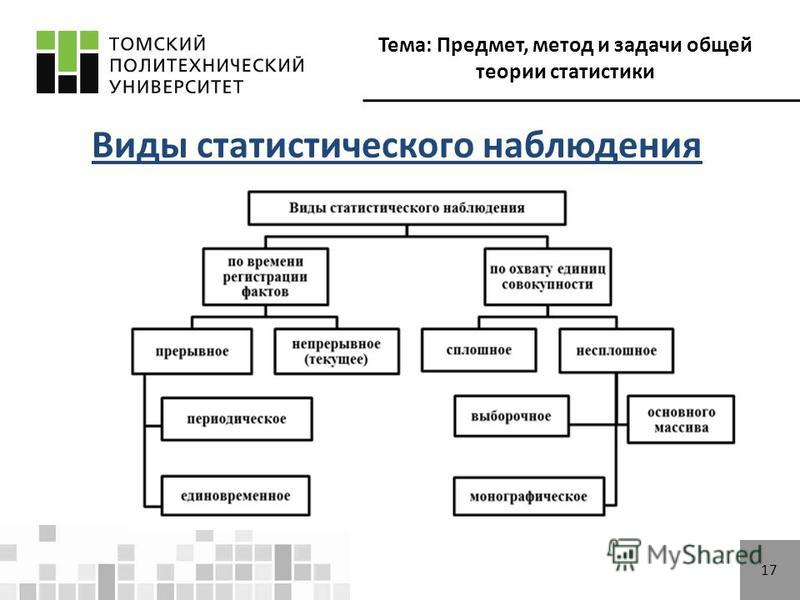 и др. Индикаторы экологических изменений: новые инструменты управления популяциями крупных травоядных. J Appl Ecol 44, 634–643, 10.1111/j.1365-2664.2007.01307.x (2007).
и др. Индикаторы экологических изменений: новые инструменты управления популяциями крупных травоядных. J Appl Ecol 44, 634–643, 10.1111/j.1365-2664.2007.01307.x (2007).
Артикул Google Scholar
Кларк, Дж. С. и Бьорнстад, О. Н. Временные ряды населения: изменчивость процесса, ошибки наблюдения, пропущенные значения, запаздывания и скрытые состояния.Экология 85, 3140–3150, 10.1890/03-0520 (2004).
Артикул Google Scholar
Бесбеас, П., Борисевич, Р. С. и Морган, Б. Дж. Т. [Завершение экологической головоломки]. Моделирование демографических процессов в маркированных популяциях Vol. 3 [Томсон Д. Л., Куч Э. Г. и Конрой М. Дж. (ред.)] [513–539] (Springer, New York, 2009).
Ньюман, К. Б., Бакленд, С. Т., Линдли, С. Т., Томас, Л. и Фернандес, К.Модели скрытых процессов динамики популяций животных. Ecol Appl 16, 74–86, 10.1890/04-0592 (2006).
КАС Статья пабмед Google Scholar
Левинс Р. Стратегия построения модели в популяционной биологии. Am Sci 54, 421–431 (1966).
Google Scholar
Тавеккья Г., Бесбеас П., Коулсон Т., Морган Б. Дж. Т. и Клаттон-Брок Т. Х. Оценка численности населения и скрытых демографических параметров с помощью моделирования в пространстве состояний.Am Nat 173, 722–733, 10.1086/598499 (2009).
Артикул пабмед Google Scholar
Рояма Т. Аналитическая динамика населения. (Чепмен и Холл, Лондон, 1992).
Книга Google Scholar
Конн, П. Б., Дифенбах, Д. Р., Лааке, Дж. Л., Тернент, М. А. и Уайт, Г. К. Байесовский анализ данных о возрасте диких животных на момент промысла. Биометрия 64, 1170–1177, 10.1111/j.1541-0420.2008.00987.x (2008 г. ).
).
MathSciNet Статья пабмед МАТЕМАТИКА Google Scholar
Де Валпин, П. Улучшенные выводы из экспериментов по динамике населения с использованием методов Монте-Карло в пространстве состояний. Экология 84, 3064–3077, 10.1890/02-0039 (2003).
Артикул Google Scholar
Мюррей Д.Л., Андерсон М.Г. и Стейри Т.D. Временной сдвиг в зависимости от плотности среди популяций размножающихся уток в Северной Америке. Экология 91, 571–581, 10.1890/ms08-1032.1 (2010).
Артикул пабмед Google Scholar
Вилюгрейн Х., Стенсет Н.К., Смит Г.В. и Стейнбакк Г.Х. Зависимость от плотности у североамериканских уток. Экология 86, 245–254, 10.1890/04-0467 (2005).
Артикул Google Scholar
Ван Г.М. и др. Пространственная и временная изменчивость изменяет зависимость от плотности в популяциях крупных травоядных. Экология 87, 95–102, 10.1890/05-0355 (2006).
Экология 87, 95–102, 10.1890/05-0355 (2006).
Артикул Google Scholar
Брукс С.П. Метод Монте-Карло с цепями Маркова и его применение. J Roy Stat Soc D- Sta 47, 69–100 (1998).
Артикул Google Scholar
Коулз, М. К. и Карлин, Б.П. Диагностика сходимости цепи Маркова Монте-Карло: сравнительный обзор. J Am Stat Assoc 91, 883–904, 10.2307/2291683 (1996).
MathSciNet Статья МАТЕМАТИКА Google Scholar
Флегал, Дж. М. и Джонс, Г. Л. [Внедрение MCMC: оценка с уверенностью]. Справочник по цепи Маркова Монте-Карло [Brooks S., et al. (ред.)] [175–197] (Чепмен и Холл, Бока-Ратон, 2011 г.).
Хименес, О. и др.[WinBUGS для популяционных экологов: байесовское моделирование с использованием методов Монте-Карло с цепями Маркова]. Моделирование демографических процессов в маркированных популяциях Vol. 3 [Томсон Д. Л., Куч Э. Г. и Конрой М. Дж. (ред.)] [883–915] (Springer, New York, 2009).
3 [Томсон Д. Л., Куч Э. Г. и Конрой М. Дж. (ред.)] [883–915] (Springer, New York, 2009).
Hebblewhite, M. Хищничество волков взаимодействует с Северо-Тихоокеанским колебанием (NPO) в популяции лосей западной части Северной Америки. J Anim Ecol 74, 226–233, 10.1111/j.1365–2656.2004.00909.x (2005).
Артикул Google Scholar
Де Вальпин, П.и Гастингс, А. Подгонка моделей населения, включающая технологический шум и ошибку наблюдения. Экол Моногр 72, 57–76, 10.2307/3100085 (2002).
Артикул Google Scholar
Деннис Б., Пончиано Дж. М., Леле С. Р., Тапер М. Л. и Стейплс Д. Ф. Оценка зависимости плотности, шума процесса и ошибки наблюдения. Ecol Monogr 76, 323–341, 10.1890/0012-9615(2006)76[323:eddpna]2.0.co;2 (2006).
Артикул Google Scholar
Линден, А.и Кнапе, Дж. Оценка воздействия окружающей среды на динамику населения: последствия ошибки наблюдения. Oikos 118, 675–680, 10.1111/j.1600-0706.2008.17250.x (2009).
Oikos 118, 675–680, 10.1111/j.1600-0706.2008.17250.x (2009).
Артикул Google Scholar
Griffin, K.A. et al. Неонатальная смертность лосей обусловлена климатом, фенологией хищников и составом сообщества хищников. J Anim Ecol 80, 1246–1257, 10.1111/j.1365-2656.2011.01856.x (2011).
Артикул пабмед Google Scholar
Хоббс, Н.Т., Андрен Х., Перссон Дж., Аронссон М. и Чапрон Г. Местные хищники сокращают добычу оленей саамскими скотоводами. Ecol Appl 22, 1640–1654 (2012).
Артикул Google Scholar
Wang, G.M. et al. Зависимость от плотности у северных копытных: взаимодействие с хищниками и ресурсами. Popul Ecol 51, 123–132, 10.1007/s10144-008-0095-3 (2009).
Артикул Google Scholar
Мелис, К.и другие. Хищничество оказывает большее влияние в менее продуктивной среде: разнообразие косуль, Capreolus capreolus, плотность популяции по всей Европе. Global Ecol Biogeogr 18, 724–734, 10.1111/j.1466-8238.2009.00480.x (2009).
Global Ecol Biogeogr 18, 724–734, 10.1111/j.1466-8238.2009.00480.x (2009).
Артикул Google Scholar
Коулсон Т., Гиннесс Ф., Пембертон Дж. и Клаттон-Брок Т. Демографические последствия освобождения популяции благородных оленей от выбраковки. Экология 85, 411–422, 10.1890/03-0009 (2004 г.).
Артикул Google Scholar
Хауэлл, Дж. А., Брукс, Г. К., Семенофф-Ирвинг, М. и Грин, К. Динамика популяции туле-лося на национальном побережье Пойнт-Рейес, Калифорния. J Wildlife Manage 66, 478–490, 10.2307/3803181 (2002).
Артикул Google Scholar
Нельсон, М. П., Вучетич, Дж. А., Петерсон, Р. О. и Вучетич, Л.М. Проект «Волк-лось» на острове Рояль (с 1958 г. по настоящее время) и чудо долгосрочных экологических исследований. Endeavour 35, 30–38, 10.1016/j.endeavour.2010.09.002 (2011).
Артикул Google Scholar
Джеймс, А. Р. К. и Стюарт-Смит, А. К. Распределение карибу и волков по отношению к линейным коридорам. J Wildlife Manage 64, 154–159, 10.2307/3802985 (2000).
Р. К. и Стюарт-Смит, А. К. Распределение карибу и волков по отношению к линейным коридорам. J Wildlife Manage 64, 154–159, 10.2307/3802985 (2000).
Артикул Google Scholar
Кожола И.и другие. Нападение волков ( Canis lupus ) на европейского дикого лесного северного оленя ( Rangifer tarandus ) в Финляндии. J Zool 263, 229–235, 10.1017/s0952836
5084 (2004).Артикул Google Scholar
Этвуд, Т. К., Гиз, Э. М. и Кункель, К. Э. Сравнительные модели хищничества пумы и повторного заселения волков в хребте Мэдисон в Монтане. J Wildlife Manage 71, 1098–1106, 10.2193/2006–102 (2007).
Артикул Google Scholar
Яркович Ю., Кларк, Дж. Д. и Мерроу, Дж. Л. Влияние переселения черного медведя на пополнение лосята в Национальном парке Грейт-Смоки-Маунтинс. J Wildlife Manage 75, 1145–1154, 10. 1002/jwmg.149 (2011).
1002/jwmg.149 (2011).
Артикул Google Scholar
Форчхаммер, М. К., Стенсет, Н. К., Пост, Э. и Лангватн, Р. Динамика популяции норвежского благородного оленя: зависимость от плотности и климатические вариации. P Roy Soc Lond B Bio 265, 341–350 (1998).
КАС Статья Google Scholar
Пост, Э.Крупномасштабные пространственные градиенты в динамике популяций травоядных. Экология 86, 2320–2328, 10.1890/04-0823 (2005).
Артикул Google Scholar
Бакленд, С. Т., Ньюман, К. Б., Томас, Л. и Кёстерс, Н. Б. Модели динамики популяций диких животных в пространстве состояний. Ecol Model 171, 157–175, 10.1016/j.ecolmodel.2003.08.002 (2004).
Артикул Google Scholar
Бьорнстад, О.Н., Фальк В. и Стенсет Н.К. Географический градиент колебаний плотности мелких грызунов — подход статистического моделирования. P Roy Soc B Bio 262, 127–133, 10.1098/rspb.1995.0186 (1995).
P Roy Soc B Bio 262, 127–133, 10.1098/rspb.1995.0186 (1995).
КАС Статья Google Scholar
Пост, Э. и Стенсет, Северная Каролина. Климатическая изменчивость, фенология растений и северные копытные. Экология 80, 1322–1339, 10.1890/0012-9658(1999)080[1322:cvppan]2.0.co;2 (1999).
Артикул Google Scholar
Пламмер М.JAGS — Еще один сэмплер Гиббса, <http://mcmc-jags.sourceforge.net> (2011) [Дата обращения: 7 февраля 2013 г.].
R Основная команда. R: Язык и среда для статистических вычислений. (Вена, Австрия, 2013 г.).
Джассби, А. Д. и Пауэлл, Т. М. Обнаружение изменений в экологических временных рядах. Экология 71, 2044–2052, 10.2307/1938618 (1990).
Артикул Google Scholar
Хардин Дж.W. & Hilbe, JM. Обобщенные линейные модели и расширения. Второе изд. (Stata Press, Колледж-Стейшн, 2007 г.).
(Stata Press, Колледж-Стейшн, 2007 г.).
Статистика, наука и наблюдения
|

 Мы также будем ссылаться на образцы баллов .
Мы также будем ссылаться на образцы баллов .

 Что-то, что может измениться
называется переменной.
Что-то, что может измениться
называется переменной. Мы можем сказать, что «более высокое удовлетворение связано с
с более высоким средним баллом», но мы не можем сказать, что «Высший средний балл
вызывает большее удовлетворение» (или наоборот).
Мы можем сказать, что «более высокое удовлетворение связано с
с более высоким средним баллом», но мы не можем сказать, что «Высший средний балл
вызывает большее удовлетворение» (или наоборот).
 Смущает результаты (плохо, плохо, плохо!).
Смущает результаты (плохо, плохо, плохо!).
 Футбол
номера на футболках и адреса домашних улиц являются общими
Примеры.
Футбол
номера на футболках и адреса домашних улиц являются общими
Примеры.

3.2.2 Вероятностная выборка
Под вероятностной выборкой понимается отбор выборки из совокупности, когда этот отбор основан на принципе рандомизации, то есть случайного отбора или случайности. Вероятностная выборка более сложна, требует больше времени и обычно дороже, чем невероятностная выборка. Однако, поскольку единицы из совокупности выбираются случайным образом и можно рассчитать вероятность выбора каждой единицы, можно получить надежные оценки и сделать статистические выводы о совокупности.
Однако, поскольку единицы из совокупности выбираются случайным образом и можно рассчитать вероятность выбора каждой единицы, можно получить надежные оценки и сделать статистические выводы о совокупности.
Существует несколько различных способов выбора вероятностной выборки.
При выборе плана вероятностной выборки цель состоит в том, чтобы свести к минимуму ошибку выборки оценок наиболее важных переменных обследования, одновременно сводя к минимуму время и затраты на проведение обследования. Некоторые операционные ограничения также могут повлиять на этот выбор, например, характеристики инструментария обследования.
В настоящем разделе каждый из этих методов будет кратко описан и проиллюстрирован примерами.
Простая случайная выборка
В простой случайной выборке (SRS) каждая единица выборки совокупности имеет равные шансы быть включенной в выборку. Следовательно, каждая возможная выборка также имеет равные шансы быть отобранной. Чтобы выбрать простую случайную выборку, вам необходимо перечислить все единицы в генеральной совокупности обследования.
Чтобы выбрать простую случайную выборку, вам необходимо перечислить все единицы в генеральной совокупности обследования.
Чтобы сделать простую случайную выборку из телефонной книги, каждая запись должна быть последовательно пронумерована.Если бы в телефонной книге было 10 000 записей и размер выборки составлял 2 000, то компьютер должен был бы случайным образом сгенерировать 2 000 номеров от 1 до 10 000. Все числа будут иметь одинаковые шансы быть сгенерированными компьютером. 2000 телефонных записей, соответствующих 2000 сгенерированным компьютером случайным числам, составили бы выборку.
SRS можно сделать с заменой или без. SRS с заменой означает, что существует вероятность того, что выбранная телефонная запись может быть выбрана дважды или более.Обычно подход SRS проводится без замены, поскольку он более удобен и дает более точные результаты. В остальной части текста SRS будет использоваться для ссылки на SRS без замены, если не указано иное.
В остальной части текста SRS будет использоваться для ссылки на SRS без замены, если не указано иное.
SRS — наиболее часто используемый метод. Преимущество этого метода заключается в том, что он не требует никакой информации об инструментарии обследования, кроме полного списка единиц обследуемой совокупности вместе с контактной информацией.Кроме того, поскольку SRS является простым методом и его теория хорошо известна, существуют стандартные формулы для определения размера выборки, оценок и т. д., и эти формулы просты в использовании.
С другой стороны, этот метод требует списка всех единиц совокупности. Если такого списка еще не существует, а целевая аудитория велика, его создание может быть очень дорогим или нереалистичным. Если список уже существует и включает вспомогательную информацию о единицах измерения, то SRS не использует информацию, позволяющую повысить эффективность других методов (например, стратифицированной выборки). Если сбор должен производиться лично, SRS может предоставить выборку, которая слишком распределена по нескольким регионам, что может увеличить затраты и продолжительность обследования.
Если сбор должен производиться лично, SRS может предоставить выборку, которая слишком распределена по нескольким регионам, что может увеличить затраты и продолжительность обследования.
Представьте, что у вас есть кинотеатр, и вы предлагаете специальный фестиваль фильмов ужасов в следующем месяце. Чтобы решить, какие фильмы ужасов показать, вы опрашиваете кинозрителей, какие из перечисленных фильмов им нравятся больше всего. Чтобы составить список фильмов, необходимых для вашего опроса, вы решаете выбрать 10 из 100 лучших фильмов ужасов всех времен.Один из способов выбрать образец — написать все названия фильмов на листках бумаги и поместить их в пустую коробку. Затем нарисуйте 10 названий, и у вас будет образец. Используя этот подход, вы обеспечите равную вероятность выбора каждого фильма. Вы даже можете рассчитать эту вероятность выбора, разделив размер выборки (n=10) на размер совокупности 100 лучших фильмов ужасов всех времен (N=100). Эта вероятность будет равна 0,10 (10/100) или 1 из 10.
Эта вероятность будет равна 0,10 (10/100) или 1 из 10.
Систематический отбор проб
Систематическая выборка означает наличие пробела или интервала между каждой выбранной единицей в выборке.Например, вы можете выполнить следующие шаги:
- Пронумеруйте единицы на вашей рамке от 1 до N (где N — общая численность населения).
- Определите интервал выборки ( K ), разделив количество единиц в совокупности на желаемый размер выборки. Например, чтобы выбрать выборку 100 из совокупности 400, вам потребуется интервал выборки 400/100 = 4. Следовательно, K = 4. Вам нужно будет выбрать одну единицу из каждых четырех единиц, чтобы закончить до 100 единиц в вашей выборке.
- Случайным образом выберите число от 1 до K . Это число называется , случайное начало , и это будет первое число, включенное в вашу выборку. Если вы выберете 3, третья единица на вашем кадре будет первой единицей, включенной в вашу выборку; если вы выберете 2, ваша выборка начнется со второго устройства на вашей раме.
- Выберите каждую Kth (в данном случае каждую четвертую) единицу после этого первого числа. Например, выборка может состоять из следующих единиц, чтобы составить выборку из 100: 3 (случайное начало), 7, 11, 15, 19 … 395, 399 (до N , что в данном случае равно 400). ).
 Если вы выберете 3, третья единица на вашем кадре будет первой единицей, включенной в вашу выборку; если вы выберете 2, ваша выборка начнется со второго устройства на вашей раме.
Если вы выберете 3, третья единица на вашем кадре будет первой единицей, включенной в вашу выборку; если вы выберете 2, ваша выборка начнется со второго устройства на вашей раме.В приведенном выше примере видно, что можно выбрать только четыре возможных образца, соответствующих четырем возможным случайным запускам:
1, 5, 9, 13 … 393, 397
2, 6, 10, 14 … 394, 398
3, 7, 11, 15 … 395, 399
4, 8, 12, 16 … 396, 400
Каждый член совокупности принадлежит только к одной из четырех выборок, и каждая выборка имеет одинаковую вероятность быть отобранной. Из этого мы видим, что каждая единица имеет один шанс из четырех быть выбранным в выборке.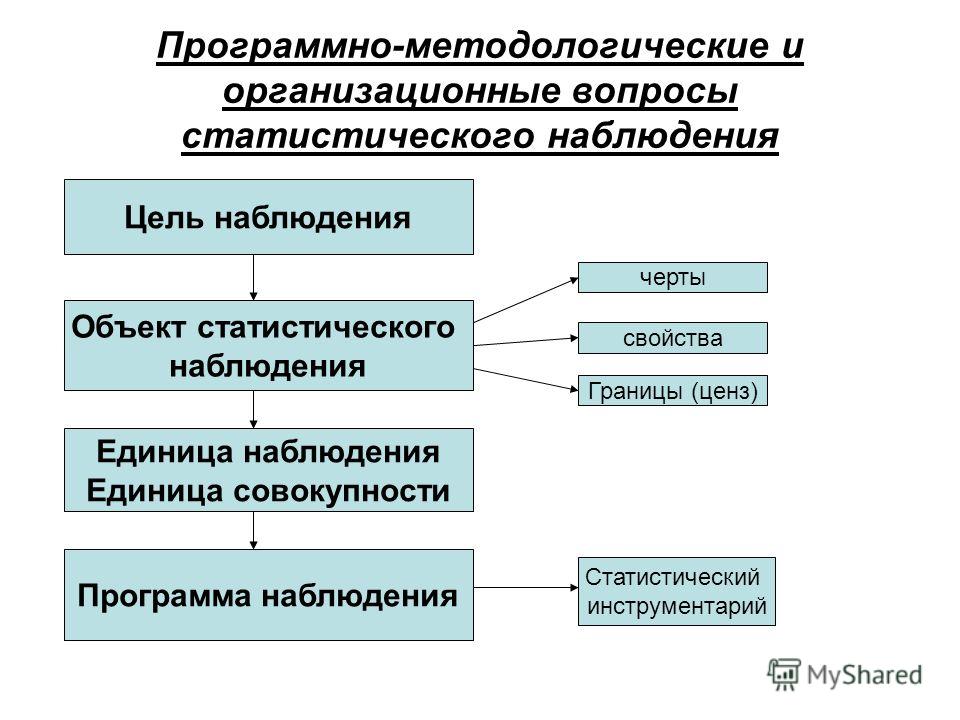 Это такая же вероятность, как если бы была выбрана простая случайная выборка из 100 единиц. Основное отличие состоит в том, что с SRS любая комбинация из 100 единиц может составить выборку, в то время как при систематической выборке есть только четыре возможных выборки. Порядок единиц в кадре будет определять возможные выборки для систематической выборки. Если совокупность случайным образом распределена в основе, систематическая выборка должна давать результаты, аналогичные простой случайной выборке.
Это такая же вероятность, как если бы была выбрана простая случайная выборка из 100 единиц. Основное отличие состоит в том, что с SRS любая комбинация из 100 единиц может составить выборку, в то время как при систематической выборке есть только четыре возможных выборки. Порядок единиц в кадре будет определять возможные выборки для систематической выборки. Если совокупность случайным образом распределена в основе, систематическая выборка должна давать результаты, аналогичные простой случайной выборке.
Этот метод часто используется в промышленности, где изделие выбирается для испытаний с производственной линии, чтобы гарантировать, что машины и оборудование имеют стандартное качество. Например, тестер на заводе-изготовителе может выполнять проверку качества каждого 20-го продукта на сборочной линии. Тестер может выбрать случайное начало между числами 1 и 20. Это определит первый тестируемый продукт; после этого каждый 20-й продукт будет протестирован.
Интервьюеры могут использовать этот метод выборки при опросе людей для выборочного обследования.Исследователь рынка может выбрать, например, каждого 10-го человека, который входит в конкретный магазин, после случайного выбора первого человека. Инспектор может опросить жителей каждого пятого дома на улице после случайного выбора одного из первых пяти домов.
Преимущества систематической выборки заключаются в том, что выборка не может быть проще: вы получаете только одно случайное число, случайное начало, а остальная часть выборки следует автоматически. Самым большим недостатком метода систематической выборки является то, что если в способе размещения совокупности в списке есть какой-либо периодический признак, и этот периодический признак каким-то образом совпадает с интервалом выборки, возможные выборки могут не быть репрезентативными для совокупности.Это можно увидеть в следующем примере:
Пример 3 Предположим, вы управляете большим продуктовым магазином и у вас есть список сотрудников в каждом отделе. Продуктовый магазин разделен на следующие 10 секций: гастроном, пекарня, кассы, склад, мясной прилавок, продукты, аптека, фотосалон, цветочный магазин и химчистка. В каждой секции работает 10 сотрудников, включая менеджера (всего 100 сотрудников). Ваш список упорядочен по разделам, где сначала указан менеджер, а затем остальные сотрудники в порядке убывания старшинства.
Продуктовый магазин разделен на следующие 10 секций: гастроном, пекарня, кассы, склад, мясной прилавок, продукты, аптека, фотосалон, цветочный магазин и химчистка. В каждой секции работает 10 сотрудников, включая менеджера (всего 100 сотрудников). Ваш список упорядочен по разделам, где сначала указан менеджер, а затем остальные сотрудники в порядке убывания старшинства.
Если вы хотите опросить своих сотрудников о том, что они думают об их рабочей среде, вы можете выбрать небольшую выборку, чтобы ответить на ваши вопросы. Если вы используете метод систематической выборки и ваш интервал выборки равен 10, вы можете выбрать только руководителей или только новых сотрудников в каждом разделе. Этот тип выборки не даст вам полной или адекватной картины мыслей ваших сотрудников.
Выборка с вероятностью, пропорциональной размеру
Вероятностная выборка требует, чтобы каждый член обследуемой совокупности имел известную вероятность включения в выборку, но не требует, чтобы эта вероятность была одинаковой для всех. Если в основе имеется информация о размере каждой единицы (например, количество работников для каждого предприятия) и если эти единицы различаются по размеру, эту информацию можно использовать при отборе выборки для повышения эффективности. Это известно как выборка с вероятностью, пропорциональной размеру (PPS). При использовании этого метода чем больше размер единицы, тем выше вероятность ее включения в выборку. Для повышения эффективности этого метода необходимо, чтобы измерение размера было точным.Это более сложный метод выборки, который не будет подробно обсуждаться здесь.
Если в основе имеется информация о размере каждой единицы (например, количество работников для каждого предприятия) и если эти единицы различаются по размеру, эту информацию можно использовать при отборе выборки для повышения эффективности. Это известно как выборка с вероятностью, пропорциональной размеру (PPS). При использовании этого метода чем больше размер единицы, тем выше вероятность ее включения в выборку. Для повышения эффективности этого метода необходимо, чтобы измерение размера было точным.Это более сложный метод выборки, который не будет подробно обсуждаться здесь.
Стратифицированная выборка
При использовании стратифицированной выборки совокупность разбивается на однородные взаимоисключающие группы, называемые стратами, а затем из каждой страты отбираются независимые выборки. Любой из методов выборки, упомянутых в этом разделе, может быть использован для выборки внутри каждой страты. Метод выборки может варьироваться от одной страты к другой. Совокупность может быть стратифицирована по любой переменной, значение которой доступно для всех единиц основы выборки до формирования выборки (т.г. возраст, пол, провинция проживания, доход).
Совокупность может быть стратифицирована по любой переменной, значение которой доступно для всех единиц основы выборки до формирования выборки (т.г. возраст, пол, провинция проживания, доход).
Зачем создавать слои? Есть много причин, главная из которых заключается в том, что это может сделать стратегию выборки более эффективной. В предыдущем разделе упоминалось, что для оценки определенной точности требуется больший размер выборки для характеристики, которая сильно варьируется от одной единицы к другой, чем для характеристики с меньшей изменчивостью. Например, если бы каждый человек в совокупности имел одинаковую заработную плату, то выборки одного человека было бы достаточно, чтобы получить точную оценку средней заработной платы.
Это идея повышения эффективности, полученного с помощью стратификации. Если вы создаете страты, в которых единицы имеют сходные характеристики и значительно отличаются от единиц в других стратах, вам потребуется только небольшая выборка из каждой страты, чтобы получить точную оценку общего дохода для этой страты. Затем вы можете объединить эти оценки, чтобы получить точную оценку общего дохода для всего населения. Если бы вы использовали SRS для всего населения без стратификации, выборка должна была бы быть больше, чем сумма всех размеров выборок страты, чтобы получить оценку общего дохода с тем же уровнем точности.
Затем вы можете объединить эти оценки, чтобы получить точную оценку общего дохода для всего населения. Если бы вы использовали SRS для всего населения без стратификации, выборка должна была бы быть больше, чем сумма всех размеров выборок страты, чтобы получить оценку общего дохода с тем же уровнем точности.
Еще одним преимуществом является то, что стратифицированная выборка обеспечивает достаточный размер выборки для представляющих интерес подгрупп населения. При стратификации совокупности каждая страта становится независимой совокупностью, и для каждой из них рассчитывается размер выборки.
Пример 4 Предположим, вы хотите оценить, сколько старшеклассников работают неполный рабочий день на национальном уровне и уровне провинции. Если бы вы выбрали простую случайную выборку из 25 000 человек из списка всех старшеклассников в Канаде (при условии, что такой список был доступен для выбора), вы бы получили немногим более 100 человек с Острова Принца Эдуарда, поскольку они составляют менее 0. 5% населения Канады. Эта выборка, вероятно, не будет достаточно большой для подробного анализа, который вы планировали. Разделение вашего списка по провинциям, а затем определение размера выборки, необходимого для каждой провинции, позволит вам получить требуемый уровень точности для острова Принца Эдуарда, а также для каждой из других провинций.
5% населения Канады. Эта выборка, вероятно, не будет достаточно большой для подробного анализа, который вы планировали. Разделение вашего списка по провинциям, а затем определение размера выборки, необходимого для каждой провинции, позволит вам получить требуемый уровень точности для острова Принца Эдуарда, а также для каждой из других провинций.
Стратификация наиболее полезна, когда стратифицирующие переменные равны
- прост в обращении,
- легко заметить,
- тесно связаны с темой опроса.
Кластерная выборка
Иногда очень дорого иметь слишком разбросанную географическую выборку. Командировочные расходы могут стать дорогими, если интервьюерам приходится опрашивать людей из одного конца страны в другой. Чтобы снизить затраты, статистики могут выбрать метод кластерной выборки .
Кластерная выборка делит совокупность на группы или кластеры. Несколько кластеров выбираются случайным образом для представления общей совокупности, а затем все единицы внутри выбранных кластеров включаются в выборку. В выборку не включены единицы из невыбранных кластеров. Они представлены представителями выбранных кластеров. Это отличается от стратифицированной выборки, когда некоторые единицы выбираются из каждой страты. Примерами кластеров являются фабрики, школы и географические районы, такие как избирательные округа.
В выборку не включены единицы из невыбранных кластеров. Они представлены представителями выбранных кластеров. Это отличается от стратифицированной выборки, когда некоторые единицы выбираются из каждой страты. Примерами кластеров являются фабрики, школы и географические районы, такие как избирательные округа.
Предположим, вы представитель спортивной организации и хотите узнать, в каких видах спорта участвуют учащиеся 11-х (или 4-х) классов по всей Канаде.Было бы слишком дорого и долго опрашивать каждого канадца в 11-м классе или даже пару учеников из каждого класса 11-го класса в Канаде. Вместо этого случайным образом выбираются 100 школ со всей Канады. Эти 100 школ являются отобранными кластерами. Затем опрашиваются все учащиеся 11-х классов во всех 100 кластерах.
Кластерная выборка создает «карманы» единиц выборки, а не распределяет выборку по всей территории, что позволяет снизить затраты на операции по сбору.Еще одна причина использования кластерной выборки заключается в том, что иногда список всех единиц генеральной совокупности недоступен, в то время как список всех кластеров либо доступен, либо его легко создать.
В большинстве случаев кластерная выборка менее эффективна, чем SRS . Это главный недостаток метода. По этой причине обычно лучше обследовать большое количество небольших скоплений, а не небольшое количество больших скоплений. Почему? Поскольку соседние единицы имеют тенденцию быть более похожими, в результате получается выборка, которая не отражает весь спектр мнений или ситуаций, присутствующих в генеральной совокупности.В примере 5 учащиеся одной и той же школы, как правило, занимаются одними и теми же видами спорта, то есть теми, для которых в их школе имеются возможности.
Еще один недостаток кластерной выборки заключается в том, что у вас нет полного контроля над окончательным размером выборки. Поскольку не во всех школах одинаковое количество учащихся 11-х классов, и вы должны опросить каждого учащегося в своей выборке, окончательный размер может быть больше или меньше, чем вы ожидали.
Многоступенчатый отбор проб
Многоступенчатая выборка похожа на кластерную выборку, за исключением того, что она включает выборку выборки в каждом выбранном кластере, а не включает все единицы из выбранных кластеров. Этот тип выборки требует как минимум двух этапов. На первом этапе выявляются и отбираются большие кластеры. На втором этапе единицы выбираются из выбранных кластеров с использованием любого из методов вероятностной выборки. В этом контексте кластеры называются первичными единицами выборки (ПЕВ), а единицы внутри кластеров называются вторичными единицами выборки (ВЕВ). При наличии более двух этапов в рамках SSE выбираются третичные единицы выборки (TSU), и процесс продолжается до тех пор, пока не будет получена окончательная выборка.
Этот тип выборки требует как минимум двух этапов. На первом этапе выявляются и отбираются большие кластеры. На втором этапе единицы выбираются из выбранных кластеров с использованием любого из методов вероятностной выборки. В этом контексте кластеры называются первичными единицами выборки (ПЕВ), а единицы внутри кластеров называются вторичными единицами выборки (ВЕВ). При наличии более двух этапов в рамках SSE выбираются третичные единицы выборки (TSU), и процесс продолжается до тех пор, пока не будет получена окончательная выборка.
В примере 5 кластерная выборка будет выбирать 100 школ, а затем опрашивать каждого учащегося 11-го класса из этих школ. Вместо этого вы можете выбрать больше школ, получить список всех учащихся 11-х классов из этих выбранных школ и выбрать случайную выборку учащихся 11-х классов из каждой школы. Это будет двухэтапный план выборки. Школы будут иметь номер PSU , а учащиеся — номер SSU .
Вы также можете получить список всех классов 11 класса в выбранных школах, выбрать случайную выборку классов из каждой из этих школ, получить список всех учащихся в выбранных классах и, наконец, выбрать случайную выборку учащихся из каждого выбранный класс.Это будет трехэтапный план выборки. Школы — PSU , классы — SSU , а учащиеся — TSU . Каждый раз, когда добавляется этап, процесс усложняется.
Теперь представьте, что в каждой школе учится в среднем 80 11-классников. Тогда кластерная выборка даст вашей организации выборку из примерно 8000 учащихся (100 школ x 80 учащихся). Если вам нужна большая выборка, вы можете выбрать школы с большим количеством учащихся.Для меньшей выборки вы можете выбрать школы с меньшим количеством учащихся. Одним из способов контроля размера выборки может быть разделение школ на большие, средние и малые размеры (с точки зрения количества учащихся 11-х классов) и выборка школ из каждой страты. Это называется стратифицированной кластерной выборкой .
Это называется стратифицированной кластерной выборкой .
В качестве альтернативы можно использовать трехэтапный план. Вы должны выбрать выборку из 400 школ, затем выбрать два класса 11 класса в каждой школе и, наконец, выбрать 10 учащихся в классе.Таким образом, вы все равно получите выборку из примерно 8000 учащихся (400 школ x 2 класса x 10 учащихся), но выборка будет более разбросанной.
Из этого примера видно, что при многоступенчатой выборке у вас все еще есть преимущество более концентрированной выборки для снижения затрат. Однако выборка не такая концентрированная, как кластерная выборка, и размер выборки, необходимый для получения заданного уровня точности, все равно будет больше, чем для SRS , поскольку метод менее эффективен.Тем не менее, многоэтапная выборка по-прежнему может сэкономить много времени и усилий по сравнению с SRS , поскольку вам не нужно иметь список всех учащихся 11-х классов. Все, что вам нужно, это список классов из 400 школ и список учеников из 800 классов.
Все, что вам нужно, это список классов из 400 школ и список учеников из 800 классов.
Многофазный отбор проб
Многоэтапная выборка собирает базовую информацию из большой выборки единиц, а затем собирает более подробную информацию для подвыборки этих единиц.Наиболее распространенной формой многоэтапной выборки является двухэтапная выборка (или двойная выборка), но также возможны три или более этапов.
Многоэтапный отбор проб сильно отличается от многоступенчатого отбора проб, несмотря на схожесть их названий. Хотя многоэтапная выборка также включает в себя получение двух или более выборок, все выборки берутся из одного и того же кадра. Выбор подразделения на втором этапе обусловлен его выбором на первом этапе. Единица, не выбранная на первом этапе, не будет частью выборки на втором этапе.Как и в случае многоэтапной выборки, чем больше фаз используется, тем сложнее план выборки и ее оценка.
Многоэтапная выборка полезна, когда в основе выборки отсутствует вспомогательная информация, которую можно было бы использовать для стратификации совокупности или для исключения части совокупности.
Пример 7Предположим, что организации требуется информация о животноводческих фермах в Альберте, но в инструментарии обследования перечислены все типы ферм — крупного рогатого скота, молочные, зерновые, свиноводческие, птицеводческие и сельскохозяйственные.Ситуация усложняется тем, что инструментарий обследования не предоставляет никакой вспомогательной информации по перечисленным там хозяйствам.
Простой опрос, единственным вопросом которого будет «Часть или вся ваша ферма посвящена животноводству?» можно было провести. При наличии только одного вопроса это обследование должно иметь низкую стоимость интервью (особенно если оно проводится по телефону) и, следовательно, организация должна быть в состоянии составить большую выборку. После того, как первая выборка составлена, можно взять вторую, меньшую выборку среди фермеров, занимающихся выращиванием крупного рогатого скота, и задать этим фермерам более подробные вопросы.Используя этот метод, организация избегает затрат на съемочные единицы, которые не входят в эту конкретную область (например, фермеры, не занимающиеся животноводством).
В примере 7 данные, собранные на первом этапе, использовались для исключения единиц, не входящих в целевую совокупность. В другом контексте эти данные можно было бы использовать для повышения эффективности второй фазы, например, путем создания пластов. Многоэтапная выборка также может использоваться для уменьшения нагрузки на респондентов или в случае очень разных затрат, связанных с разными вопросами опроса, как показано в следующем примере.
Пример 8В ходе опроса о состоянии здоровья участникам задают несколько основных вопросов об их питании, привычках к курению, физических упражнениях и употреблении алкоголя. Кроме того, опрос требует, чтобы респонденты подвергали себя некоторым прямым физическим тестам, таким как бег на беговой дорожке или измерение артериального давления и уровня холестерина.
Заполнение анкет или опрос участников являются относительно недорогими процедурами, но медицинские тесты требуют наблюдения и помощи квалифицированного врача, а также использования оборудованной лаборатории, что может быть довольно дорогостоящим.Наилучшим способом проведения этого обследования было бы использование метода двухэтапной выборки. На первом этапе интервью проводятся на выборке соответствующего размера. Из этой выборки берется меньшая выборка. Только участники, отобранные во второй выборке, будут принимать участие в медицинских тестах.
7.3 Единица анализа и единица наблюдения – Научные исследования в социальной работе
Цели обучения
- Дайте определение единицам анализа и единицам наблюдения и опишите две распространенные ошибки, которые совершают люди, смешивая их
При разработке исследовательского проекта необходимо учитывать единицы анализа и единицы наблюдения.Они могут немного отличаться по количественному и качественному дизайну исследований. Эти два пункта касаются того, что исследователь наблюдает при сборе данных и что он надеется сказать об этих наблюдениях. Единица анализа — это объект, о котором вы хотите что-то сказать в конце вашего исследования, и он считается центром вашего исследования. единица наблюдения — это элемент (или элементы), который вы наблюдаете, измеряете или собираете, пытаясь узнать что-то о своей единице анализа.
В некоторых исследованиях единица наблюдения может совпадать с единицей анализа. Например, в исследовании зависимости от электронных гаджетов можно взять интервью у студентов бакалавриата (наша единица наблюдения) с целью сказать что-то о студентах бакалавриата (наша единица анализа) и их зависимости от гаджетов. Возможно, если бы мы исследовали зависимость от гаджетов у детей младшего школьного возраста (наша единица анализа), мы могли бы собрать наблюдения учителей и родителей (наши единицы наблюдения), потому что младшие дети могут неточно сообщать о своем поведении.В этом и многих других случаях единицы анализа не совпадают с единицами наблюдения. Однако от исследователей требуется четкое определение своих единиц анализа и единиц наблюдения для себя и своей аудитории.
Более конкретно, ваша единица анализа будет определяться вашим исследовательским вопросом. С другой стороны, ваша единица наблюдения во многом определяется методом сбора данных, который вы используете для ответа на этот исследовательский вопрос. Далее в учебнике мы более подробно рассмотрим методы сбора данных.А пока давайте рассмотрим наше предыдущее исследование, целью которого было изучение пристрастия учащихся к электронным гаджетам. Сначала мы рассмотрим, как различные типы исследовательских вопросов по этой теме могут привести к различным единицам анализа. Затем мы подумаем, как можно ответить на эти вопросы и с какими данными. Это приводит нас к разнообразию единиц наблюдения.
Допустим, мы собираемся выяснить, какие ученики с наибольшей вероятностью будут зависимы от своих электронных гаджетов.Нашей единицей анализа будут отдельные студенты. Скорее всего, мы отправим опрос студентам в кампусе. Мы бы классифицировали людей на основе принадлежности к социальным группам, чтобы увидеть, как принадлежность к определенным социальным группам коррелирует с зависимостью от электронных гаджетов. Например, мы можем обнаружить, что студенты, изучающие новые медиа, студенты, идентифицирующие себя как мужчины, и студенты с высоким социально-экономическим статусом чаще, чем другие студенты, становятся зависимыми от своих электронных гаджетов. Мы также могли бы изучить, чем различаются зависимости студентов от гаджетов и чем они похожи.В этом случае мы могли бы проводить наблюдения за зависимыми учениками и фиксировать, когда, где, почему и как они используют свои гаджеты. Независимо от того, собирается ли информация о пристрастии учащихся к электронным гаджетам путем опроса или непосредственного наблюдения, данные собираются от отдельных учащихся. Таким образом, единицей наблюдения в обоих примерах является индивидуум.
Другой распространенной единицей анализа в социальных науках является группа. Конечно, группы различаются по размеру, но почти ни одна группа не является слишком маленькой или слишком большой, чтобы представлять интерес для социологов.Семьи, группы дружбы и участники групповой терапии — вот некоторые распространенные примеры групп микроуровня, которые исследуют социологи. Сотрудники организации, профессионалы в определенной области (например, повара, юристы, социальные работники) и члены клубов (например, девочек-скаутов, Ротари, Общества красных шляп) — все это группы мезоуровня, которые могут изучать социологи. Наконец, на макроуровне социологи иногда исследуют граждан целых народов или жителей разных континентов или других регионов.
Исследование пристрастия учащихся к своим электронным гаджетам на групповом уровне могло бы выяснить, имеют ли определенные типы социальных клубов больше или меньше членов, зависимых от гаджетов, чем другие виды клубов. Возможно, мы обнаружим, что в клубах физической подготовки, таких как клуб регби и клуб подводного плавания, меньше членов, зависимых от гаджетов, чем в клубах умственной активности, таких как шахматный клуб и клуб женских исследований. Наша единица анализа в этом примере — группы, потому что группы — это то, о чем мы надеемся что-то сказать.Если бы мы спросили, являются ли люди, вступающие в церебральные клубы, более склонными к зависимости от гаджетов, чем те, кто вступает в социальные клубы, то нашей единицей анализа были бы отдельные люди. Однако в любом случае нашей единицей наблюдения будут индивидуумы.
Организации — еще одна потенциальная единица анализа, о которой социологи, возможно, захотят что-то сказать. К организациям относятся такие организации, как корпорации, колледжи и университеты и даже ночные клубы. На уровне организации изучение зависимости студентов от электронных гаджетов может помочь выяснить, как различные колледжи решают эту социальную проблему.В данном случае нас интересует не опыт отдельных студентов, а различия между университетскими городками в борьбе с зависимостью от гаджетов. Исследователь, проводящий исследование такого типа, может изучить письменные правила и процедуры школы, поэтому его единицей наблюдения будут документы. Однако, поскольку в конечном итоге они хотят описать различия между кампусами, единицей анализа будет колледж.
В общем, существует много потенциальных единиц анализа, которые может исследовать социальный работник, но некоторые из наиболее распространенных единиц включают следующее:
- Физические лица
- Группы
- Организации
| Исследование вопрос | Блок анализа | Данные Коллекция | Блок наблюдения | Заявление о выводах |
| Какие учащиеся наиболее склонны к зависимости от своих электронных гаджетов? | Физические лица | Опрос студентов на территории кампуса | Физические лица | Специалисты по новым медиа, мужчины и студенты с высоким социально-экономическим статусом чаще, чем другие студенты, становятся зависимыми от своих электронных гаджетов. |
| В некоторых социальных клубах больше членов, зависимых от гаджетов, чем в других клубах? | Группы | Опрос студентов на территории кампуса | Физические лица | Клубы с научной направленностью, такие как клуб социальной работы и математический клуб, имеют больше членов, зависимых от гаджетов, чем клубы с социальной направленностью, такие как клуб 100 бутылок пива на стене и клуб вязания. клуб. |
| Как разные колледжи решают проблему зависимости от электронных гаджетов? | Организации | Контент-анализ политик | Документы | Кампусы без сильных программ по информатике с большей вероятностью, чем те, где есть такие программы, отчисляют студентов, у которых обнаружено пристрастие к их электронным гаджетам. |
| Примечание : Помните, что описанные здесь результаты являются гипотетическими. Нет оснований полагать, что какие-либо из описанных здесь гипотетических выводов действительно подтвердятся, если их проверить эмпирическими исследованиями. | ||||
Когда дело доходит до причинно-следственных связей и единиц анализа, люди совершают одну распространенную ошибку, которая называется экологической ошибкой . Это происходит, когда заявления об одной единице анализа более низкого уровня делаются на основе данных какой-либо единицы анализа более высокого уровня.Во многих случаях это происходит, когда претензии предъявляются к отдельным лицам, но собираются данные только на уровне группы. Например, мы можем захотеть понять, является ли зависимость от электронных гаджетов более распространенной в одних кампусах, чем в других. Возможно, разные кампусы по всей стране предоставили нам свой процент студентов, зависимых от гаджетов, и из этих данных мы узнаем, что зависимость от электронных гаджетов более распространена в кампусах, где есть бизнес-программы, чем в кампусах без них.Затем мы делаем вывод, что студенты, изучающие бизнес, чаще, чем студенты, не изучающие бизнес, становятся зависимыми от своих электронных гаджетов. Однако такой вывод был бы неверным. У нас есть только показатели зависимости по кампусам, поэтому мы можем делать выводы только о кампусах, а не об отдельных студентах в этих кампусах. Возможно, специалисты по социальной работе в бизнес-кампусах являются теми, кто вызвал такой высокий уровень зависимости в этих кампусах. Дело в том, что мы просто не знаем, потому что у нас есть данные только на уровне кампуса.Следовательно, мы рискуем совершить экологическую ошибку, если будем делать выводы о студентах, когда наши данные относятся к университетскому городку.
Кроме того, еще одна ошибка, чтобы знать об этом редукционизм. Редукционизм возникает, когда утверждения о какой-либо единице анализа более высокого уровня делаются на основе данных из некоторой единицы анализа более низкого уровня. В этом случае утверждения о группах или явлениях макроуровня делаются на основе данных индивидуального уровня. Пример редукционизма можно увидеть в некоторых описаниях движения за гражданские права.Время от времени люди заявляли, что Роза Паркс начала движение за гражданские права в Соединенных Штатах, отказавшись уступить свое место белому человеку в городском автобусе в Монтгомери, штат Алабама, в декабре 1955 года. Хотя Паркс сыграла неоценимую роль в движение и ее акт гражданского неповиновения вдохновили других на мужество, было бы редукционистом приписывать ей начало движения. Безусловно, подъему и успеху американского движения за гражданские права способствовали многие факторы, в том числе узаконенная расовая сегрегация, историческое решение Верховного суда 1954 года о десегрегации школ и создание Студенческого координационного комитета ненасильственных действий, и это лишь некоторые из них.Другими словами, движение обусловлено многими факторами — некоторыми социальными, другими политическими и третьими экономическими. Роза Паркс сыграла очень важную роль в этом развитии американской истории, но сказать, что она вызвала все движение за гражданские права, было бы редукционизмом.
Предыдущее обсуждение не предназначалось для того, чтобы удержать вас от заявлений о данных или взаимосвязях между уровнями анализа. Хотя важно быть внимательным к возможности ошибки в причинно-следственных рассуждениях о различных уровнях анализа, это предупреждение не должно мешать вам делать обоснованные аналитические выводы из ваших данных.Суть в том, чтобы быть осторожным и добросовестным в выводах между уровнями анализа. Ошибки в анализе происходят из-за отсутствия строгости и отклонения от научного метода.
Ключевые выводы
- Единицей анализа является элемент, о котором вы хотите сказать что-то в конце вашего исследования, а единицей наблюдения является предмет, который вы действительно наблюдаете.
- Когда исследователи путают свои единицы анализа и наблюдения, они могут быть склонны совершать либо экологическую ошибку, либо редукционизм.
Глоссарий
Экологическое заблуждение – заявления об одной единице анализа более низкого уровня сделаны на основе данных какой-либо единицы анализа более высокого уровня
Редукционизм – когда заявления о какой-либо единице анализа более высокого уровня делаются на основе данных какой-либо единицы анализа более низкого уровня
Единица анализа – объект, о котором исследователь хочет что-то сказать в конце своего исследования
Единица наблюдения – элемент, который исследователь фактически наблюдает, измеряет или собирает в ходе попытки узнать что-то о своей единице анализа
Авторство изображений
Бинокль Nightowl CC-0
Совокупности, параметры и выборки в логической статистике
Логическая статистика позволяет делать выводы о популяциях, используя небольшие выборки.Следовательно, дедуктивная статистика обеспечивает огромные преимущества, потому что обычно вы не можете измерить все население.
Однако, чтобы воспользоваться этими преимуществами, вы должны понимать взаимосвязь между совокупностями, субпопуляциями, параметрами совокупности, выборками и выборочной статистикой.
В этом сообщении блога я обсуждаю эти концепции и способы получения репрезентативных выборок с помощью случайной выборки.
Связанный пост : Разница между описательной и логической статистикой
Население
Население может включать людей, но другие примеры включают объекты, события, предприятия и т. д.В статистике есть два основных типа населения.
Популяции могут быть полным набором всех существующих подобных элементов. Например, население страны включает всех людей, проживающих в настоящее время в этой стране. Это конечный, но потенциально большой список участников.
Однако популяция может быть теоретической конструкцией потенциально бесконечного размера. Например, аналитики по улучшению качества часто рассматривают всю текущую и будущую продукцию производственной линии как часть генеральной совокупности.
Популяции имеют общий набор определяемых вами атрибутов. Например, следующие популяции:
- Звезды в галактике Млечный Путь.
- Детали с производственной линии.
- граждан США.
Прежде чем приступить к исследованию, вы должны тщательно определить изучаемую группу населения. Эти популяции могут быть узко определены в соответствии с потребностями вашего анализа. Например, взрослые шведские женщины, которые в остальном здоровы, но страдают остеопорозом.
Субпопуляции могут улучшить ваш анализ
Подгруппы имеют дополнительные атрибуты. Например, население Соединенных Штатов содержит подгруппы мужчин и женщин. Вы также можете подразделить его другими способами, такими как регион, возраст, социально-экономический статус и т. д. Различные исследования, в которых участвует одна и та же популяция, могут разделить ее на разные подгруппы в зависимости от того, что имеет смысл для данных и анализа.
Понимание субпопуляций в вашем исследовании поможет вам лучше понять предмет.Они также могут помочь вам создать статистические модели, которые лучше соответствуют данным. Субпопуляции особенно важны, когда они имеют характеристики, которые систематически отличаются от общей совокупности. Когда вы анализируете свои данные, вам нужно знать об этих более глубоких разделениях. Фактически, вы можете рассматривать соответствующие подгруппы как дополнительные факторы в более поздних анализах.
Например, если вы анализируете средний рост взрослого населения США, вы улучшите свои результаты, включив в него мужские и женские субпопуляции, поскольку их рост систематически различается.Я подробно расскажу об этом примере позже в этом посте!
Параметры совокупности в сравнении со статистикой выборки
Параметр — это значение, описывающее характеристику всей совокупности, например среднее значение совокупности. Поскольку вы почти никогда не можете измерить всю совокупность, вы обычно не знаете реальное значение параметра. На самом деле значения параметров почти всегда неизвестны. Хотя мы не знаем значения, оно определенно существует.
Например, средний рост взрослых женщин в США — это параметр, который имеет точное значение — мы просто не знаем, что это такое!
Среднее значение генеральной совокупности и стандартное отклонение являются двумя общими параметрами.В статистике греческие символы обычно обозначают параметры совокупности, такие как μ (мю) для среднего значения и σ (сигма) для стандартного отклонения.
Статистика — это характеристика выборки. Если вы собираете выборку и вычисляете среднее значение и стандартное отклонение, это статистика выборки. Выводная статистика позволяет использовать выборочную статистику, чтобы делать выводы о генеральной совокупности. Однако, чтобы сделать правильные выводы, вы должны использовать определенные методы выборки. Эти методы помогают гарантировать, что выборки дают несмещенные оценки.Смещенные оценки систематически завышены или занижены. Вам нужны объективные оценки, потому что в среднем они верны.
В логической статистике мы используем выборочную статистику для оценки параметров совокупности. Например, если мы соберем случайную выборку взрослых женщин в Соединенных Штатах и измерим их рост, мы сможем вычислить среднее значение выборки и использовать его в качестве объективной оценки среднего значения генеральной совокупности. Мы также можем выполнить проверку гипотезы по оценке выборки и создать доверительные интервалы, чтобы построить диапазон, в который, вероятно, попадает фактическое значение генеральной совокупности.
Закон больших чисел гласит, что по мере роста размера выборки статистика выборки будет сходиться к параметрам генеральной совокупности. Кроме того, стандартная ошибка среднего математически описывает, как большие выборки дают более точные оценки.
Похожие сообщения : Меры центральной тенденции и меры изменчивости
Репрезентативная выборка и простая случайная выборка
Выборка — это подмножество всего населения. В статистике выборка означает выбор подмножества населения.После составления выборки вы измеряете одну или несколько характеристик всех элементов выборки, таких как рост, доход, температура, мнение и т. д. Если вы хотите сделать выводы об этих характеристиках во всей совокупности, это накладывает ограничения на то, как вы собрать образец. Если вы используете неправильную методологию, выборка может не представлять генеральную совокупность, что может привести к ошибочным выводам.
Наиболее известным методом получения объективной репрезентативной выборки является простая случайная выборка.При использовании этого метода все элементы совокупности имеют равную вероятность быть выбранными. Этот процесс помогает гарантировать, что выборка включает весь диапазон генеральной совокупности. Кроме того, все соответствующие субпопуляции должны быть включены в выборку и точно представлены в среднем. Простая случайная выборка минимизирует систематическую ошибку и упрощает анализ данных.
Я рассмотрю методологию выборки более подробно в одной из следующих статей блога, но есть несколько важных предостережений относительно простой случайной выборки.Хотя этот подход сводит к минимуму систематическую ошибку, он не означает, что статистика вашей выборки в точности соответствует параметрам генеральной совокупности. Вместо этого оценки по конкретной выборке, вероятно, будут немного завышены или занижены, но в среднем процесс дает точные оценки. Кроме того, при случайном отборе можно получить необычные выборки — это просто не ожидаемый результат.
Методы сбора репрезентативной пробы включают следующее:
Кроме того, случайная выборка может показаться несколько случайной и легкой в использовании — и то, и другое не соответствует действительности.Простая случайная выборка предполагает, что вы систематически составляете полный список всех людей или предметов, существующих в совокупности. Затем вы случайным образом выбираете субъектов из этого списка и включаете их в выборку. Это может быть очень трудоемким процессом.
Случайная выборка может повысить внутреннюю и внешнюю валидность вашего исследования. Узнайте больше о внутренней и внешней валидности.
И наоборот, удобная выборка не позволяет получить репрезентативные выборки. Эти образцы гораздо легче собрать, но результаты минимально полезны.
Давайте воплотим эти концепции в жизнь!
Связанный пост : Статистика выборки всегда неверна (в некоторой степени)!
Пример совокупности с важными субпопуляциями
Предположим, мы изучаем рост американских граждан и предположим, что мы мало что знаем об этом предмете. Следовательно, мы собираем случайную выборку, измеряем рост в сантиметрах и вычисляем среднее значение выборки и стандартное отклонение. Вот файл данных CSV: Heights.
Получаем следующие результаты:
Поскольку мы собрали случайную выборку, мы можем предположить, что эта выборочная статистика является объективной оценкой параметров совокупности.
Теперь предположим, что мы узнали больше об изучаемой области и включили мужчин и женщин в качестве подгрупп. Мы получаем следующие результаты.
Обратите внимание, как одно широкое распределение было заменено двумя более узкими распределениями? Распределение для каждого пола имеет меньшее стандартное отклонение, чем отдельное распределение для всех взрослых, что согласуется с более узким разбросом средних значений для мужчин и женщин на графике.Эти результаты показывают, как среднее дает более точные оценки, когда мы оцениваем рост по полу. На самом деле, среднее значение для всего населения не равно среднему для любой подгруппы. Это заблуждение!
В ходе этого процесса мы узнаем, что пол является важной субпопуляцией, связанной с ростом и расширяющей наше понимание предмета. В будущих исследованиях роста мы можем включить пол в качестве предиктора.
В этом примере используется категориальная группирующая переменная (Пол) и непрерывная переменная результата (Рост).Если вы хотите сравнить распределения непрерывных значений между группами, как в этом примере, рассмотрите возможность использования коробчатых диаграмм и графиков отдельных значений. Эти графики становятся более полезными по мере увеличения количества групп.
Этот пример намеренно прост для понимания, но представьте себе исследование на менее очевидную тему. Этот процесс поможет вам получить новые сведения и создать более совершенные статистические модели.
Используя свои знания о популяциях, субпопуляциях, параметрах, выборке и выборочной статистике, вы можете делать ценные выводы о больших популяциях, используя небольшие выборки.Для получения дополнительной информации о том, как вы можете проверять гипотезы о популяциях, прочитайте мой обзор проверки гипотез.
При проведении измерений убедитесь, что ваши измерительные инструменты и результаты тестов действительны. Чтобы узнать больше, прочитайте мой пост Validity.
Родственные .