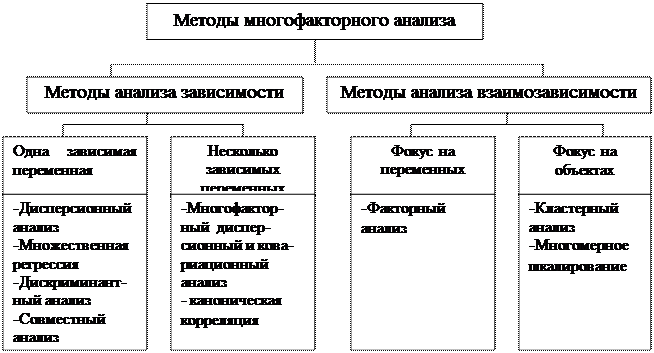
Инструментарий статистического наблюдения включает: ТЕСТ Зачетная работа по предмету «Статистика»для специальностей СПО
Тема 2 Статистическое наблюдение Основные вопросы темы
Тема 2. Статистическое наблюдение
Основные вопросы темы: 2. 1. Сущность, цель и этапы статистического наблюдения 2. 2. Проектирование статистического наблюдения 2. 3. Организационные формы статистического наблюдения 2. 4. Виды и способы статистического наблюдения 2. 5. Ошибки статистического наблюдения и способы контроля точности статистических данных
Сущность статистического наблюдения Статистическое наблюдение – научно-организационный сбор данных о социально-экономических процессах и явлениях путем регистрации их существенных признаков по специально разработанной программе
Цель статистического наблюдения – получение объективной и полной информации об объекте наблюдения
Основные элементы статистического наблюдения статистик (исследователь) статистический инструментарий Объект наблюдения программа статистического наблюдения инструкция бланки документов для регистрации признаков (статистические формуляры) Данные статист.
Проектирование статистического наблюдения включает: Ø разработку программно методологического обеспечения статистического наблюдения; Ø решение организационных вопросов наблюдения.
Программно– методологическое обеспечение статистического наблюдения включает: установление цели статистического наблюдения; определение объекта наблюдения; выбор единицы наблюдения; разработку программы наблюдения.
Цель статистического наблюдения определяется конкретной исследовательской проблемой и заключается в информационном обеспечении процесса принятия решения по данной проблеме
Объект наблюдения – статистическая совокупность, о которой должны быть собраны необходимые статистические данные
Единица наблюдения – составной элемент объекта наблюдения, который является носителем признаков, подлежащих регистрации
В зависимости от предмета исследования единицами наблюдения могут выступать: Ø физические лица Ø реально существующие физические объекты Ø организационно и территориально обособленные единицы (образования) Ø отдельные события или состояния объекта
Программа статистического наблюдения – перечень признаков единицы наблюдения, подлежащих регистрации в процессе статистического наблюдения
Факторы, влияющие на содержание программы: Ø цели исследования; Ø особенности наблюдаемого объекта; Ø установленные сроки получения материалов наблюдения; Ø установленные требования к степени детализации исследования; Ø располагаемые ресурсы (материальнотехнические, трудовые, финансовые).
Программа наблюдения разрабатывается в виде: формуляра и инструкции по его заполнению Статистический формуляр – это документ, содержащий программу и отражающий результаты наблюдения. Формуляр может иметь разные названия: отчет, карточка, опросный лист, анкеты и др.
Разработка организационных вопросов статистического наблюдения включает: определение организационной формы, вида и способа статистического наблюдения; Ø определение времени и места статистического наблюдения; Ø определение органов, проводящих наблюдение; Ø разработку календарного плана статистического наблюдения; Ø составление сметы. Ø
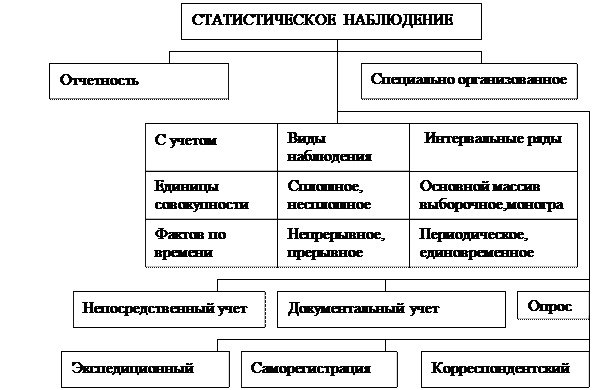
Организационные формы статистического наблюдения Статистическа я отчетность переписи Единовременные учеты Регистры Специально организованное наблюдение мониторинг Специально организованное обследование
Организационные формы статистического наблюдения Статистическая отчетность – основная форма статистического наблюдения, при которой организации и предприятия представляют в органы статистики сведения о своей деятельности в виде отчетов, регламентированных по содержанию и срокам представления за подписью лиц, ответственных за своевременность и достоверность представленных данных.
Организационные формы статистического наблюдения Перепись – это специально организованное наблюдение, повторяющееся, как правило, через равные промежутки времени с целью получения информации об объекте наблюдения на определенный момент времени.
Организационные формы статистического наблюдения Мониторинг – система мероприятий, позволяющих непрерывно следить за состоянием определенного объекта, регистрировать его важнейшие характеристики, оценивать их, оперативно выявлять результаты воздействия на объект различных факторов.
Организационные формы статистического наблюдения Регистровое наблюдение – это форма непрерывного статистического наблюдения за долговременными процессами, имеющими фиксированное начало, стадию развития и фиксированный конец. Оно основано на ведении статистического регистра.
Организационные формы статистического наблюдения Статистический регистр – перечень респондентов с указанием сведений о них, необходимых для организации государственных статистических наблюдений.
Виды и способы статистического наблюдения Способы статистического наблюдения Непосредствен ное наблюдение Документальное наблюдение Опрос анкетный явочный экспедиционный саморегистрация корреспондентски й
Виды статистического наблюдения По времени регистрации фактов Прерывное Текущее или непрерывное По охвату единиц совокупности Сплошное Несплошное Периодическое Выборочное Единовременное Основного массива Монографическое
Ошибки статистического наблюдения и способы контроля точности статистических данных Ошибка наблюдения – это величина расхождения между результатом наблюдения и истинным значением признака
Виды ошибок статистического наблюдения Ошибки репрезентативности Ошибки регистрации Случайные Систематические Преднамеренные Случайные Непреднамеренные Систематические
Статистическое наблюдение
Тема 3. Статистическое наблюдение.

1.Основные понятия.
2. Формы, виды и способы статистического наблюдения.
3. Контроль материалов наблюдения.
4. Регистровая форма наблюдения.
1. Основные понятия
Любое статистическое исследование состоит из трех последовательных этапов: статистического наблюдения, сводки собранных материалов и анализа результатов сводки.
Статистическое наблюдение — это первая стадия всякого статистического исследования, представляющего собой научно-организованный по единой программе учет фактов, характеризующих явления и процессы общественной жизни.
Процесс проведения статистического наблюдения включает следующие этапы:
— подготовка наблюдения
— проведение массового сбора данных
— подготовка данных к автоматизированной обработке
— разработка предложений по совершенствованию статистического наблюдения
Статистические наблюдения чаще всего преследуют практическую цель – получение достоверной информации для выявления закономерностей развития явлений и процессов.
Задача наблюдения предопределяет его программу и формы организации. Неясно поставленная цель может привести к тому, что в процессе наблюдения будут собраны ненужные данные или, наоборот, не будут получены сведения, необходимые для анализа.
Научная организация статистического наблюдения предполагает определение объекта и единицы наблюдения, разработки программы и организационного плана проведения наблюдения.
Объект статистического наблюдения – это совокупность общественных явлений и процессов, которые подлежат данному статистическому наблюдению. Для объекта статистического наблюдения характерно то, что его нельзя изучать непосредственно в целом. Изучение объекта предполагает выделение в его составе отдельных единиц и их наблюдение.
Единицей статистического наблюдения является составной элемент объекта наблюдения, являющийся носителем признаков, подлежащих регистрации в процессе данного наблюдения (объект переписи населения – совокупность всех жителей страны, а единица наблюдения — каждый человек).
Важно также определить
территорию проведения наблюдения – все места нахождения единиц наблюдения;
время наблюдения – время, к которому относятся собираемые данные.
При изучении объектов наблюдения, численность и характеристика которых непрерывно изменяются, устанавливается критическая дата, по состоянию на которую собирают сведения при переписи населения – время начала и время окончания регистрации данных).
Часто устанавливается критический момент – момент времени, на который регистрируют состояние объекта.
Программа статистического наблюдения представляет собой перечень вопросов, по которым нужно получить в процессе наблюдения сведения в отношении каждой обследуемой единицы. Один и тот же объект может быть исследован с различных сторон.
Поэтому при разработке программы наблюдения, прежде всего, необходимо сформулировать цель и задачи всего исследования.
Одним из основных требований, предъявляемых к программе наблюдения, а, следовательно, и к документам, является краткость и точность вопросов. Важное значение имеет последовательность вопросов, так как ответы в известной степени должны контролировать друг друга.
Важное значение имеет последовательность вопросов, так как ответы в известной степени должны контролировать друг друга.
Организационный план статистического наблюдения представляет собой перечень мероприятий, необходимых для успешного выполнения работы по сбору и обработке материалов, с указанием сроков и исполнителей.
В плане наблюдения, прежде всего, определяются права и обязанности каждого соисполнителя.
В плане указывается:
срок проведения наблюдения.
территория, на которой производится наблюдение
лица и организации, ответственных за проведение подготовительных работ, сбор, проверку и обработку материалов на отдельных участках территории.
Для проведения наблюдения в каждом конкретном случае разрабатывается инструментарий статистического наблюдения, который включает в себя формуляр и инструкцию.
Формуляр статистического наблюдения – это специальный документ, в котором регистрируются ответы на вопросы программы наблюдения. Он представляет собой разграфленный лист бумаги, в котором содержится перечень вопросов программы, свободные места для записи ответов (с указанием шифров и кодов) на них. Формуляр наблюдения состоит из двух частей: титульной и адресной. Титульная часть формуляра наблюдения включает: наименование статистического наблюдения и органа, его проводящего, а также дату и наименование органа, утвердившего данный формуляр. Адресная часть формуляра содержит запись точного адреса единицы или совокупности единиц наблюдения, их соподчиненность, иногда – сроки и место рассылки заполненных формуляров.
Он представляет собой разграфленный лист бумаги, в котором содержится перечень вопросов программы, свободные места для записи ответов (с указанием шифров и кодов) на них. Формуляр наблюдения состоит из двух частей: титульной и адресной. Титульная часть формуляра наблюдения включает: наименование статистического наблюдения и органа, его проводящего, а также дату и наименование органа, утвердившего данный формуляр. Адресная часть формуляра содержит запись точного адреса единицы или совокупности единиц наблюдения, их соподчиненность, иногда – сроки и место рассылки заполненных формуляров.
В статистике различают две системы статистического формуляра: индивидуальную (формуляр-карточка) и списочную (формуляр-список). Индивидуальный формуляр (формуляр-карточс) – это формуляр, предназначенный для регистрации в нем ответов на вопросы программы наблюдения только об одной единице наблюдения. Списочный формуляр (формуляр-список) – это формуляр, предназначенный для регистрации в нем ответов на вопросы программы наблюдения о нескольких единицах наблюдения.
Для обеспечения единообразного толкования вопросов программы наблюдения и облегчения их понимания в статистических форсылают может быть дан статистический подсказ, который выражается либо в перечислении возможных ответов на вопросы, либо в указании методики или способа расчета того или иного показателя. Статистический подсказ – это перечень возможных ответов на поставленный вопрос.
С целью обеспечения более полного и правильного процесса организации и проведения наблюдения к программе статистического наблюдения составляется подробная инструкция. Статистическая инструкция – это документ, разъясняющий вопросы программы статистического наблюдения, порядок заполнения статистического формуляра и частично планово-организационные вопросы. В инструкции отражаются цели и задачи наблюдения, сведения об объекте и единицах наблюдения, о времени и сроках проведения наблюдения, об оформлении результатов и сроков их представления в соответствующие организации. В инструкции, так же как и в формуляре наблюдения, но в более развернутом виде, могут быть представлены толкование того или иного вопроса программы, примерные ответы на вопросы, типичные случаи заполнения формуляров и т. д. Инструкция статистического наблюдения должна быть составлена кратко, просто и ясно.
д. Инструкция статистического наблюдения должна быть составлена кратко, просто и ясно.
2. Формы, виды и способы статистического наблюдения
С точки зрения организации статистического наблюдения различают две основные формы: отчетность и специально организованное статистическое наблюдение.
Отчетность как форма статистического наблюдения характеризуется тем, что статистические органы систематически получают от предприятий, учреждений и организаций в установленные сроки сведения об условиях и результатах работы за прошедший период, объем, и содержание которых определены утвержденными формами отчетности. При этом источником сведений являются первичные учетные записи в документах бухгалтерского и оперативного учета.
Статистическая отчетность — это официальный документ, в котором содержатся сведения о работе подотчетного объекта, занесенные на специальную форму. Статистическая отчетность чаще всего базируется на данных бухгалтерского учета.
Первичный учет представляет собой регистрацию различных фактов (событий, процессов и т. д.), производимых по мере их свершения и, как правило, на первичном учетном документе.
д.), производимых по мере их свершения и, как правило, на первичном учетном документе.
Каждое предприятие или учреждение представляет установленные формы статистической отчетности, характеризующие различные стороны их деятельности. Все формы статистической отчетности утверждают органы государственной статистики.
По своему содержанию формы отчетности бывают типовыми (общими) и специализированными.
Общая отчетность — это отчетность, содержащая одни и те же данные для определенной отрасли народного хозяйства и для предприятий (учреждений) всего народного хозяйства.
В специализированной отчетности содержатся специфические показатели отдельных отраслей промышленности, сельского хозяйства и т.п.
По периоду времени, за который предоставляется отчетность, по его длительности различают отчетность текущую и годовую. Если сведения представляются за год, то такую отчетность называют годовой. Отчетность за все другие периоды в пределах менее года, соответственно квартальная, месячная, недельная и т.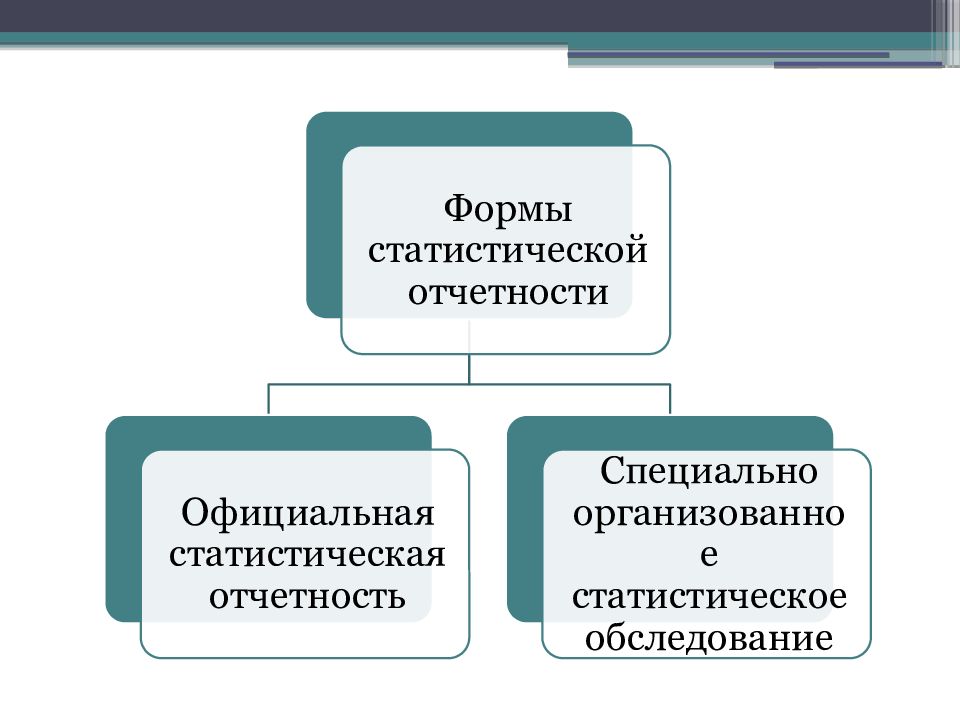 п. называется текущей.
п. называется текущей.
Специально организованное статистическое наблюдение представляет собой сбор сведений в форме переписей, единовременных учетов и обследований. Их организуют для изучения тех явлений, которые не могут быть охвачены обязательной отчетностью.
Виды статистического наблюдения – по характеру регистрации данных во времени различают непрерывные (текущие) и прерывные (периодические и единовременные) статистические наблюдения.
Текущие наблюдения ведут непрерывно по мере возникновения изучаемого факта. Практически в основе всей статистической отчетности лежит непрерывная первичная регистрация фактов на предприятиях и в учреждениях: учет произведенной продукции, учет поступления и отпуска материалов, учет выручки в магазинах, учет количества родившихся и т.д.При текущем наблюдении нельзя допускать значительного разрыва между моментом возникновения факта и моментом его регистрации.
Прерывное наблюдение отражает состояние изучаемого явления на определенный момент. Оно может быть периодическим, если проводится через равные промежутс времени, или единовременным, если проводится нерегулярно, по мере необходимости.
Оно может быть периодическим, если проводится через равные промежутс времени, или единовременным, если проводится нерегулярно, по мере необходимости.
По степени охвата единиц изучаемой совокупности различают сплошные и несплошные статистические наблюдения.
При сплошном статистическом наблюдении обследованию подлежат все единицы, входящие в состав изучаемой совокупности.
При несплошном наблюдении обследуется часть единиц изучаемой совокупности. При организации несплошного наблюдения, как правило, ставится задача распространить результаты наблюдения на всю совокупность
Несплошное наблюдение проводят в тех случаях, когда наблюдение сопряжено с уничтожением или порчей обследуемых единиц либо с целью экономии материальных и трудовых затрат, либо с целью контроля данных сплошного наблюдения.
В статистической практике несплошное наблюдение проводят в трех видах: обследование основного массива, выборочное наблюдение и монографическое описание.
Обследование основного массива представляет собой такое несплошное наблюдение, при котором из всей совокупности единиц для наблюдения отбирается такая часть их, у которой объем изучаемого признака составляет подавляющую долю в объеме признака по всей совокупности.
Выборочное наблюдение является наиболее совершенным видом несплошного наблюдения. Характерной особенностью выборочного наблюдения является строго научный отбор единиц для обследования, обеспечивающий близость состава отобранной части единиц к составу единиц всей совокупности.
Для монографического описания характерно детальное изучение и описание отдельных единиц совокупности или небольших групп явлений, характерных в каком-либо отношении. Монографическое описание не ставит своей задачей давать характеристику всей совокупности.
Основными способами получения статистической информации являются непосредственное наблюдение, документальный способ и опрос.
Способ непосредственного наблюдения характеризуется тем, что представители органов государственной статистики или других организаций записывают данные в статистические документы после личного осмотра, пересчета, измерения или взвешивания единиц наблюдения.
При документальном способе наблюдения источником сведений служат различные документы.
При способе опроса источником сведений являются ответы опрашиваемых лиц. Опрос может быть организован по-разному; экспедиционным способом, саморегистрацией, корреспондентским способом и анкетным способом.
При экспедиционном способе (устном опросе) представители статистических органов спрашивают обследуемое лицо (или его представителя) и с его слов записывают сведения в бланк наблюдения.
При способе саморегистрации (самоисчислении) обследуемым единицам (предприятиям или гражданам) вручают бланк обследования и дают указания по его заполнению. Заполненные бланки в установленный срок пересылают по почте, или представители статистических органов непосредственно на месте проверяют правильность заполнения и собирают бланки.
При корреспондентском способе сведения статистическим органам сообщают добровольные корреспонденты.
Анкетный способ сбора данных основан на принципе добровольного заполнения адресатами анкет (листов опроса).
3. Контроль материалов наблюдения
Статистическое наблюдение
Введение
1. Понятие и требования
статистического наблюдения
Понятие и требования
статистического наблюдения
2. Программно-методологические и организационные вопросы статистического наблюдения
3. Виды и способы статистического наблюдения
4. Ошибки статистического наблюдения. Меры по обеспечению надежности статистического наблюдения
Заключение
Список использованной литературы
Статистика
имеет многовековую историю.  Это требует глубоких экономических
знаний в области сбора, обработки и
анализа экономической информации.
Это требует глубоких экономических
знаний в области сбора, обработки и
анализа экономической информации.
Количественная характеристика социально-экономических процессов в непосредственной связи с их качественной сущностью невозможна без глубокого статистического исследования. Использование различных способов и приемов статистической методологии предполагает наличие исчерпывающей и достоверной информации об изучаемом объекте, что включает этапы сбора статистической информации и ее первичной обработки, сведения и группировки результатов наблюдения в определенные совокупности, обобщения и анализа полученных материалов.
Если при сборе статистических данных
допущена ошибка или материал оказался
недоброкачественным, это повлияет на
правильность и достоверность как теоретических,
так и практических выводов. Поэтому статистическое
наблюдение, от начальной до завершающей
стадии, должно быть тщательно продуманным
и четко организованным.
Статистическое наблюдение — это начальная стадия экономико-стати стического исследования. Она представляет собой научно организованную работу по собиранию массовых первичных данных о явлениях и процессах общественной жизни.
Важность этого этапа исследований определяется тем, что использование только объективной и достаточно полной информации, полученной в результате статистического наблюдения, на последующих этапах исследования в состоянии обеспечить научно обоснованные выводы о характере и закономерностях развития изучаемого объекта.
Цель контрольной работы — изучение теоретических аспектов методологии статистического наблюдения.
Объектом исследования выступает статистическое наблюдение, его виды, формы и способы.
Предметом исследования будут работы и исследования ученых в области статистики.
Методика исследования
– анализ теоретических данных с области
статистики и статистических наблюдений
в частности.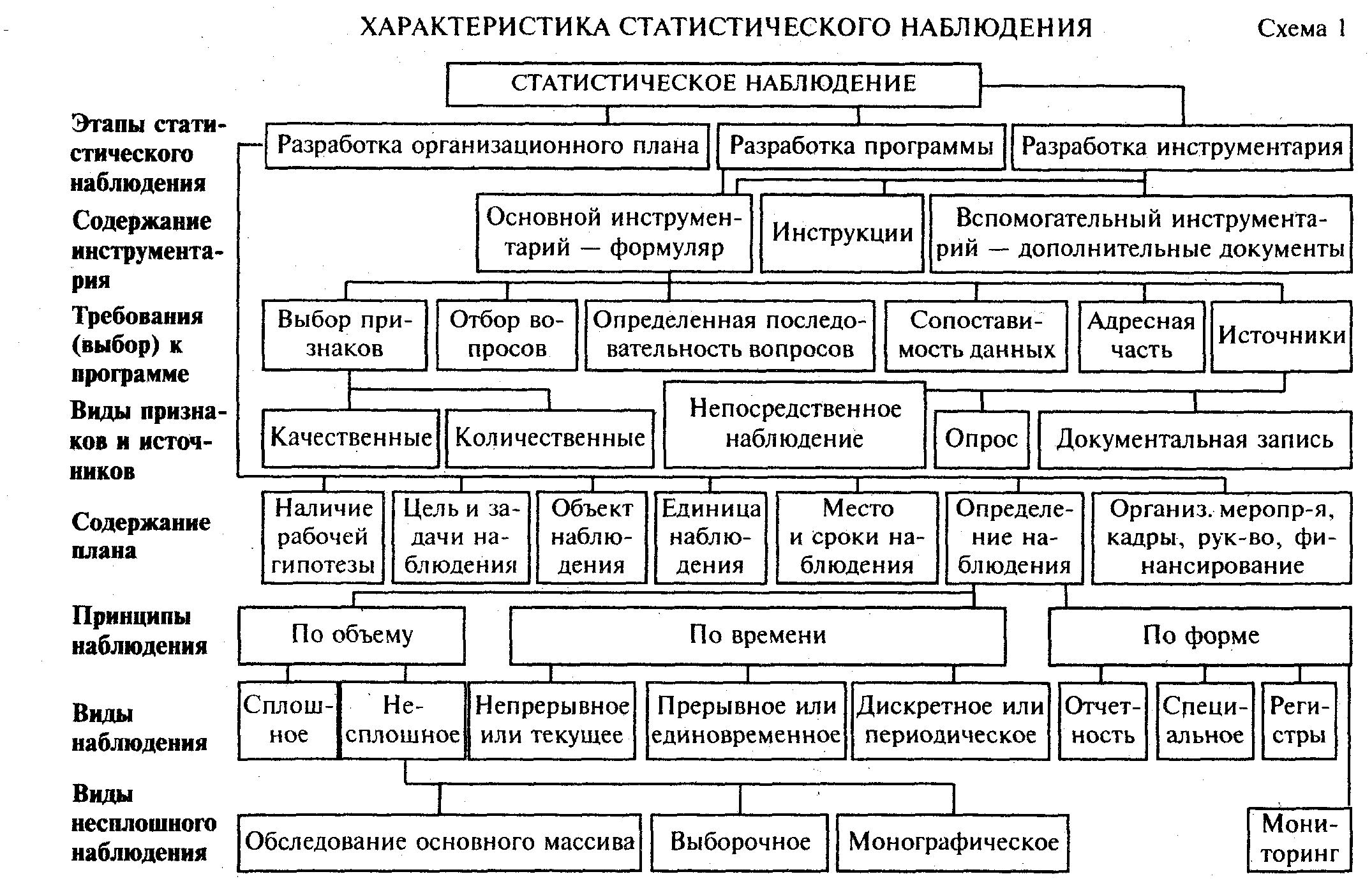
Задачи контрольной работы:
- провести анализ теоретических данных по вопросу статистического наблюдения;
- определить основные виды и способы статистического наблюдения;
- дать короткий анализ этапов статистического наблюдения;
- определить понятие ошибки статистического наблюдения.
- Понятие и требования статистического наблюдения
Статистическое
наблюдение — это первая стадия
всякого статистического исследования,
массовое (оно охватывает большое число
случаев проявления исследуемого явления
для получения правдивых статистических
данных), планомерное (проводится по разработанному
плану, включающему вопросы методологии,
организации сбора и контроля достоверности
информации), систематическое (проводится
систематически, либо непрерывно, либо
регулярно), научно организованное (для
повышения достоверности данных, которая
зависит от программы наблюдения, содержания
анкет, качества подготовки инструкций)
наблюдение за явлениями и процессами
социально-экономической жизни, которое
заключается в сборе и регистрации отдельных
признаков у каждой единицы совокупности.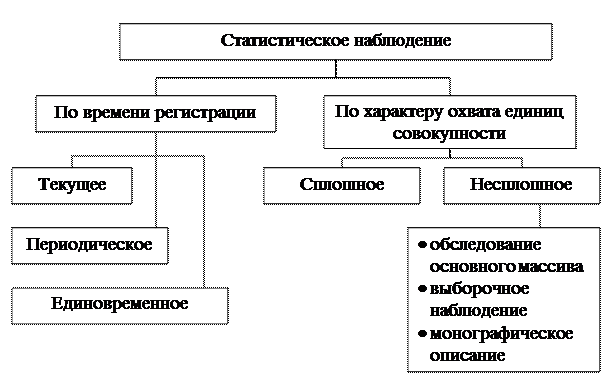 [1]
[1]
Планомерность статистического наблюдения заключается в том, что оно проводится по специально разработанному плану, который включает в себя вопросы, связанные с организацией и техникой сбора статистической информации, контроля ее качества и достоверности, представления итоговых материалов.
Массовый характер статистического наблюдения обеспечивается наиболее полным охватом всех случаев проявления изучаемого явления или процесса, т. е. в процессе статистического наблюдения подвергаются измерению и регистрации количественные и качественные характеристики не отдельных единиц изучаемой совокупности, а всей массы единиц совокупности.
Систематичность статистического наблюдения означает, что оно должно проводиться не случайным образом, т. е. стихийно, а выполняться либо непрерывно, либо регулярно через равные промежутки времени.[1]
Процесс проведения статистического наблюдения представлен на рисунке 1.[4]
Рисунок 1. Схема проведения
статистического наблюдения
Схема проведения
статистического наблюдения
Однако, следует отметить, что не всякий сбор сведений является статистическим наблюдением. О статистическом наблюдении можно говорить лишь тогда, когда, во-первых, обеспечивается регистрация устанавливаемых фактов в специальных учетных документах и, во-вторых, изучаются статистические закономерности, т.е. такие, которые проявляются только в массовом процессе, в большом числе единиц какой-то совокупности. Поэтому статистическое наблюдение должно быть планомерным, массовым и систематическим.
Любое статистическое наблюдение осуществляется
с помощью оценки и регистрации признаков
единиц изучаемой совокупности в соответствующих
учетных документах. Таким образом, полученные
данные представляют собой факты, которые,
так или иначе, характеризуют явления
общественной жизни. В результате статистической
обработки доказательная способность
фактов еще более возрастает, что обеспечивает
их систематизацию и представление в
сжатом виде. [4]
[4]
Статистическое наблюдение должно отвечать следующим требованиям:
- наблюдаемые явления должны иметь научную или практическую ценность, выражать определенные социально – исторические типы явлений;
- непосредственный сбор массовых данных должен обеспечить полноту фактов, относящихся к рассматриваемому вопросу, так как явления находятся в постоянном изменении, развитии. В том случае, если отсутствуют полные данные, анализ и выводы могут быть ошибочными;
- для обеспечения достоверности статистических данных необходима тщательная и всесторонняя проверка (контроль) качества собираемых фактов, что является одной из важнейших характеристик статистического наблюдения.
- научная организация статистического наблюдения необходима для того, чтобы создать наилучшие условия для получения объективных материалов.
Таким образом, статистическое
наблюдение представляет собой трудоемкую
и кропотливую работу, требующую привлечения
квалифицированных кадров, всесторонне
продуманной ее организации, планирования,
подготовки и проведения.
Статистическое наблюдение может проводиться органами государственной статистики, научно – исследовательскими институтами, экономическими, экономическими службами банков, бирж, фирм.[6]
2.Программно-методологические и организационные вопросы статистического наблюдения
Одной из важнейших задач, которую необходимо решить при подготовке статистического наблюдения, является определение цели, объекта и единицы наблюдения.[3]
Цель практически любого статистического наблюдения – получение достоверной информации о явлениях и процессах общественной жизни, с тем чтобы выявить взаимосвязи факторов, оценить масштабы явления и закономерности его развития. Исходя из задач наблюдения, определяются его программа и формы организации. Кроме цели следует установить объект наблюдения, т. е. определить, что именно подлежит наблюдению.
Любое
статистическое исследование необходимо
начинать с точной формулировки его цели
и конкретных задач, а тем самым и тех сведений,
которые могут быть получены в процессе
наблюдения. После этого определяются
объект и единица наблюдения, разрабатывается
программа, выбираются вид и способ
наблюдения.
После этого определяются
объект и единица наблюдения, разрабатывается
программа, выбираются вид и способ
наблюдения.
Объект наблюдения – совокупность социально-экономических явлений и процессов, которые подлежат исследованию, или точные границы, в пределах которых будут регистрироваться статистические сведения.
В ряде случаев для отграничения объекта наблюдения пользуются тем или иным цензом. Ценз есть ограничительный признак, которому должны удовлетворять все единицы изучаемой совокупности.
Единицей наблюдения называется составная часть объекта наблюдения, которая служит основой счета и обладает признаками, подлежащими регистрации при наблюдении.
Программа
наблюдения – это перечень вопросов,
по которым собираются сведения, либо
перечень признаков и показателей, подлежащих
регистрации. Программа наблюдения оформляется
в виде бланка (анкеты, формуляра), в который
заносятся первичные сведения.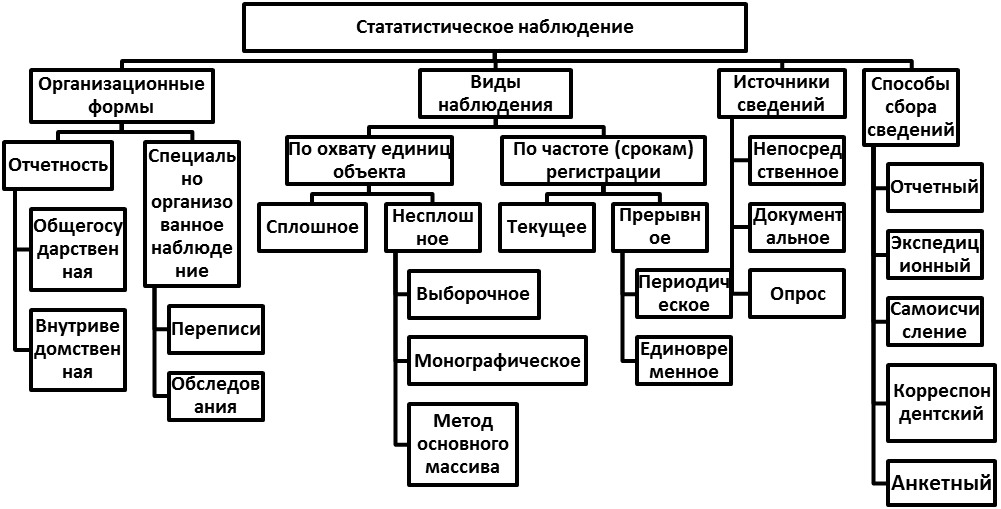 Необходимым
дополнением к бланку является инструкция
(или указания на самих формулярах), разъясняющая
смысл вопроса. Состав и содержание вопросов
программы наблюдения зависят от задач
исследования и от особенностей изучаемого
общественного явления.
Необходимым
дополнением к бланку является инструкция
(или указания на самих формулярах), разъясняющая
смысл вопроса. Состав и содержание вопросов
программы наблюдения зависят от задач
исследования и от особенностей изучаемого
общественного явления.
Организационные вопросы статистического наблюдения включают в себя определение субъекта, места, времени, формы и способа наблюдения.
- Виды и способы статистического наблюдения
Задачей общей теории статистики является определение форм, видов и способов статистического наблюдения для решения вопроса, где, когда и какие приемы наблюдения применять. Приведенная ниже схема иллюстрирует классификацию форм, видов и способов статистического наблюдения (рисунок 2).[3]
Рисунок 2. Формы, виды и способы статистического наблюдения
Статистические наблюдения можно разбить на группы:
- по охвату единиц совокупности;
- времени регистрации фактов.

По степени охвата исследуемой совокупности статистическое наблюдение подразделяется на два вида: сплошное и не сплошное. При сплошном (полном) наблюдении охватываются все единицы изучаемой совокупности. Сплошное наблюдение обеспечивает полноту информации об изучаемых явлениях и процессах. Такой вид наблюдения связан с большими затратами трудовых и материальных ресурсов, так как для сбора и обработки всего объема необходимой информации требуется значительное время.[2]
При
не сплошном наблюдении охватывается
только определенная часть изучаемой
совокупности, при этом важно заранее
определить, какая именно часть изучаемой
совокупности будет подвергнута наблюдению
и какой критерий будет положен в основу
выборки. Преимущество проведения не
сплошного наблюдения заключается в том,
что оно проводится в короткие сроки, связано
с меньшими трудовыми и материальными
затратами, полученная информация носит
оперативный характер. Существует несколько
видов не сплошного наблюдения: выборочное,
наблюдение основного массива, монографическое. [2]
[2]
Выборочным называют наблюдение части единиц исследуемой совокупности, выделенной методом случайного отбора. При правильной организации выборочное наблюдение дает достаточно точные результаты, которые можно применить с определенной вероятностью на всю совокупность. Если выборочное наблюдение предполагает отбор не только единиц изучаемой совокупности (выборку в пространстве), но и моментов времени, в которые проводится регистрация признаков (выборка во времени), такое наблюдение называется методом моментных наблюдений.[2]
Наблюдение основного массива охватывает собой обследование определенных, наиболее существенных по значимости изучаемых признаков единиц совокупности. При этом наблюдении в учет принимаются самые крупные единицы совокупности, а регистрируются самые существенные для данного исследования признаки.
Для монографического
наблюдения характерно всестороннее и
глубокое изучение лишь отдельных единиц
совокупности, обладающих какими-либо
особенными характеристиками или представляющими
какое-либо новое явление. Цель такого
наблюдения – выявление имеющихся или
только зарождающихся тенденций в
развитии данного процесса или явления.
При монографическом обследовании отдельные
единицы совокупности подвергаются детальному
изучению, которое позволяет зафиксировать
очень важные зависимости и пропорции,
которые не обна-ружимы при других, не
столь подробных, наблюдениях. Важно отметить,
что монографическое наблюдение тесно
связано со сплошным и выборочным наблюдениями.[2]
Цель такого
наблюдения – выявление имеющихся или
только зарождающихся тенденций в
развитии данного процесса или явления.
При монографическом обследовании отдельные
единицы совокупности подвергаются детальному
изучению, которое позволяет зафиксировать
очень важные зависимости и пропорции,
которые не обна-ружимы при других, не
столь подробных, наблюдениях. Важно отметить,
что монографическое наблюдение тесно
связано со сплошным и выборочным наблюдениями.[2]
ВОПРОСЫ ТЕСТОВОГО КОНТРОЛЯ по теме МЕТОДИКА СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ | Методические материалы ОЗиЗ
ДОПОЛНИТЕ:1. Основным методом медико-социального анализа является _____________ метод.
2. В статистическом исследовании выделяют __________этапа.
3. Статистическое исследование начинается с определения__________и _________.
4. Группа относительно однородных элементов в конкретных условиях времени и пространства называется ______________________________________________.
5. Единица наблюдения – это первичный элемент статистической совокупности, имеющий признаки сходства и ______________.
6. Составление плана и программы исследования – это _________________ этап статистического исследования.
7. Признаки, по которым различаются элементы статистической совокупности – это ______________ признаки.
8. Учетные признаки статистической совокупности по характеру подразделяются на количественные и __________________________________________
9. Учетные признаки статистической совокупности по роли в совокупности бывают факторными и __________________.
10. В зависимости от охвата единиц наблюдения статистическая совокупность бывает генеральной и _____________________.
11. Наблюдение за всеми единицами изучаемой совокупности называется ___________________________________.
12. Наблюдение, охватывающее часть единиц совокупности для характеристики целого, — это _________________наблюдение.
13. Обследование, проведенное на определенную дату (время), называется _____________________________наблюдением.
14. Основное требование к выборочной совокупности – это ______________________________.
15. Таблицы бывают простые, групповые и __________________.
16. Вторым этапом статистического исследования является _________________________ ______________________.
ВЫБЕРИТЕ НОМЕР ПРАВИЛЬНОГО ОТВЕТА17. Статистическая совокупность состоит из
1) статистических величин
2) единиц наблюдения
3) средних величин
4) всего перечисленного.
18. Свойством репрезентативности обладает совокупность
1) генеральная
2) выборочная
19. Статистическое наблюдение – это этап статистического исследования:
1) первый
2) второй
3) третий
20. Статистическая разработка – это этап статистического исследования
Статистическая разработка – это этап статистического исследования
1) первый
2) второй
3) третий
4) четвертый
21. В программу статистического исследования входит определение
1) объема наблюдения
2) места и сроков наблюдения
3) видов наблюдения
4) единицы наблюдения и учетных признаков
22. Единица наблюдения – это
1) первичный элемент статистического наблюдения, являющийся носителем признаков, подлежащих регистрации
2) первичный элемент, из которых состоит вся наблюдаемая совокупность
3) перечень элементов, определяющих комплекс признаков, подлежащих регистрации
4) перечень признаков, определяющих совокупность наблюдения.
23. Основным требованием к выборочной совокупности является
Основным требованием к выборочной совокупности является
1) репрезентативность
2) однородность групп
3) типичность входящих в группу единиц
24. По времени статистическое наблюдение может быть
1) текущее
2) сплошное
3) выборочное
25. Существуют признаки различия (учетные)
1) количественные
2) результативные
3) факторные
4) атрибутивные
5) все перечисленное
26. В комбинационной таблице представлена группировка данных по
1) одному признаку
2) двум признакам
3) трем признакам и более
ВЫБЕРИТЕ НОМЕРА ПРАВИЛЬНЫХ ОТВЕТОВ27.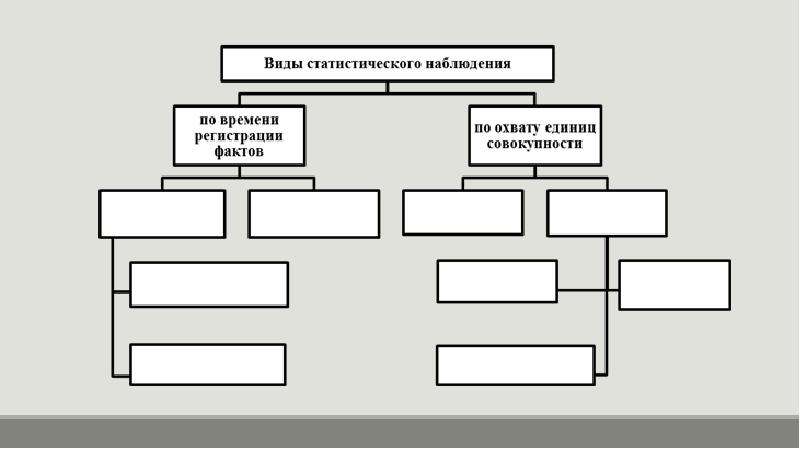 Групповые свойства статистической совокупности
Групповые свойства статистической совокупности
1) распределение признаков
2) средний уровень признака
3) разнообразие признака
4) репрезентативность
5) однородность
6) взаимосвязь признаков.
28. По охвату статистическое наблюдение бывает
1) текущее
2) единовременное
3) сплошное
4) выборочное
29. Учетные признаки по характеру могут быть:
1) количественные
2) факторные
3) качественные
4) результативные
30. К количественным учетным признакам можно отнести
1) диагноз
2) длительность заболевания
3) исход заболевания
4) возраст
5) степень тяжести заболевания
31. Единовременным наблюдением является
Единовременным наблюдением является
1) изучение рождаемости
2) профилактический осмотр населения
3) перепись больных, находящихся в стационаре
4) изучение инвалидности
32. Текущим наблюдением является
1) перепись населения
2) изучение рождаемости
3) изучение заболеваемости по данным обращаемости
4) изучение обеспеченности населения больничными койками
33. Для формирования выборочной совокупности используют метод
1) механический
2) типологический
3) основного массива
4) сплошного отбора
5) случайный
34. К программе статистического исследования относятся
1) организация исследования, финансирование и др.
2) определение единицы наблюдения и учетных признаков
3) определение видов наблюдения
4) разработка статистического документа
5) разработка макетов статистических таблиц
35. К плану статистического исследования относятся
1) определение видов наблюдения
2) определение объекта исследования
3) организация исследования, финансирование и др.
4) разработка статистического документа
5) составление анкеты.
36. Статистическое наблюдение включает
1) инструктаж исполнителей
2) выкопировку сведений
3) контроль качества регистрации (логический и аналитический)
4) составление макетов таблиц.
37. Статистическая разработка включает
1) контроль собранного материала
2) шифровку материала в соответствии с группировочными признаками
3) раскладку карт в соответствии с макетами разработочных таблиц
4) составление макетов таблиц
5) заполнение таблиц и подсчет итогов
УСТАНОВИТЕ СООТВЕТСТВИЕОтвет: 1 -___; 2 — ___ .
Ответ: 1 -___; 2 — ___ .
Ответ: 1 -___; 2 — ___ .Ответ: 1 -___; 2 — ___ .
Ответ: 1 -___; 2 — ___ .Ответ: 1 -___; 2 — ___ .
Ответ: 1 -___; 2 — ___ .Ответ: 1 -___; 2 — ___ .
Ответ: 1 -___; 2 — ___ .Ответ: 1 -___; 2 — ___ .
УСТАНОВИТЕ ПОСЛЕДОВАТЕЛЬНОСТЬ43.Этапы статистического исследования:
1) сбор материала
2) анализ данных
3) разработка материала
4) составление плана и программы исследования.
44. Содержание III этапа статистического исследования:
1) шифровка
2) вычисление показателей
3) сводка (заполнение таблиц)
4) контроль документов
5) распределение по группам для подсчета
6) графическое изображение
ОТВЕТЫ НА ТЕСТОВЫЕ ЗАДАНИЯ- статистический
- 4
- цели и задач
- статистической совокупностью
- различия
- первый
- учетные
- качественные
- результативными
- выборочной
- сплошным
- выборочное
- единовременным
- репрезентативность
- комбинационные
- статистическое наблюдение (сбор материала)
- 2
- 2
- 2
- 3
- 4
- 1
- 1
- 1
- 5
- 3
- 1,2,3,4,6
- 3,4
- 1,3
- 2,4
- 2,3
- 2,3
- 1,2,5
- 2,5
- 1,2,3
- 1,2,3
- 1,2,3,5
- 1 – Б,Д; 2 – А,В,Г.
- 1 – В; 2 – Б.
- 1 – Б; 2 – В.
- 1 – Б; 2 – Д; 3 – А.
- 1 – Г; 2 – В.
- 4,1,3,2
- 4,1,5,3,2,6.

Основные статистические инструменты в исследованиях и анализе данных
Описательная статистика[4] пытается описать взаимосвязь между переменными в выборке или генеральной совокупности. Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды. Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика
Степень, в которой наблюдения группируются вокруг центрального местоположения, описывается центральной тенденцией, а распространение к крайним значениям описывается степенью дисперсии.
Меры центральной тенденции
Меры центральной тенденции – это среднее значение, медиана и мода[6]. Среднее (или среднее арифметическое) — это сумма всех баллов, деленная на количество баллов. На среднее значение могут сильно влиять экстремальные переменные.Например, на среднее пребывание пациентов с отравлением фосфорорганическими соединениями в ОИТ может повлиять один пациент, который находится в ОИТ около 5 месяцев из-за септицемии. Экстремальные значения называются выбросами. Формула для среднего:
Среднее,
, где x = каждое наблюдение и n = количество наблюдений. Медиана[6] определяется как середина распределения в ранжированных данных (с половиной переменных в выборке выше и половиной ниже медианного значения), в то время как мода является наиболее часто встречающейся переменной в распределении.Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных. В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль).Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль).Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
, где σ 2 — дисперсия совокупности, X — среднее значение совокупности, X i — i элемент из популяции, а N — количество элементов в популяции.Дисперсия выборки определяется несколько иной формулой:
, где s 2 — дисперсия выборки, x — среднее значение выборки, x i — i th элемент выборки n — количество элементов в выборке. Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
, где σ — стандартное отклонение совокупности, X — среднее значение совокупности, X i — i th элемент совокупности и N – количество элементов в популяции.SD выборки определяется по несколько иной формуле:
, где s — SD выборки, x — среднее значение выборки, x i — i th элемент выборки и n — количество элементов в выборке. Пример расчета вариации и стандартного отклонения показан на рис.
Пример расчета вариации и стандартного отклонения показан на рис.
Таблица 2
Пример среднего значения, дисперсии, стандартного отклонения
Нормальное распределение или распределение Гаусса
Большинство биологических переменных обычно группируются вокруг центрального значения с симметричными положительными и отрицательными отклонениями относительно этой точки.[1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
Кривая нормального распределения
Наклонное распределение
Это распределение с асимметрией переменных относительно их среднего значения. В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
Кривые, показывающие распределение с отрицательной и положительной асимметрией
Статистика логического вывода
В статистике логического вывода данные анализируются из выборки, чтобы сделать выводы в большей совокупности совокупности. Цель состоит в том, чтобы ответить или проверить гипотезы. Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Вероятность — это мера вероятности того, что событие произойдет. Вероятность определяется как число от 0 до 1 (где 0 означает невозможность, а 1 означает уверенность).
В логической статистике термин «нулевая гипотеза» ( H 0 ‘ H-ноль ,’ ‘ H-нуль ‘) означает, что между рассматриваемыми переменными генеральной совокупности нет связи (различия). .[9]
Альтернативная гипотеза ( H 1 и H a ) означает, что утверждение между переменными, как ожидается, будет истинным. [9]
[9]
Значение P (или вычисленная вероятность) представляет собой вероятность того, что событие произойдет случайно, если нулевая гипотеза верна. Значение P представляет собой число от 0 до 1 и интерпретируется исследователями при принятии решения об отклонении или сохранении нулевой гипотезы [].
Таблица 3
Значения P с интерпретацией
Если значение P меньше произвольно выбранного значения (известного как α или уровень значимости), нулевая гипотеза (H0) отклоняется [].Однако, если нулевая гипотеза (H0) ошибочно отвергается, это называется ошибкой первого рода.[11] Дополнительные сведения об альфа-ошибке, бета-ошибке и расчете размера выборки, а также о факторах, влияющих на них, рассматриваются в другом разделе этого выпуска Das S et al. .[12]
Таблица 4
Иллюстрация для нулевой гипотезы НЕПАРАМЕТРИЧЕСКИЕ ТЕСТЫ
Числовые данные (количественные переменные), которые имеют нормальное распределение, анализируются с помощью параметрических тестов. [13]
[13]
Двумя основными предпосылками для параметрического статистического анализа являются: выборки и соответствующая им совокупность равны.
Однако, если распределение выборки смещено в одну сторону или распределение неизвестно из-за небольшого размера выборки, используются непараметрические[14] статистические методы.Непараметрические тесты используются для анализа порядковых и категориальных данных.
Параметрические тесты
Параметрические тесты предполагают, что данные представлены в количественном (числовом) масштабе с нормальным распределением основной совокупности. Выборки имеют одинаковую дисперсию (однородность дисперсий). Выборки случайным образом берутся из населения, и наблюдения внутри группы не зависят друг от друга. Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Критерий Стьюдента t
Критерий Стьюдента t используется для проверки нулевой гипотезы об отсутствии различий между средними значениями двух групп. Он используется в трех случаях:
Он используется в трех случаях:
Чтобы проверить, значительно ли среднее значение выборки (как оценка среднего значения совокупности) отличается от среднего значения данной совокупности (это одновыборочный t -тест)
Формула для одной выборки t — тест равен
, где X = среднее значение выборки, u = среднее значение генеральной совокупности и SE = стандартная ошибка среднего значимо (непарный т -тест).Формула для непарного t -теста:
, где X 1 − X 2 — разница между средними значениями двух групп, а SE обозначает стандартную ошибку разницы.
Проверить, значительно ли различаются средние значения совокупности, оцененные по двум зависимым выборкам (парный t -тест). Обычная установка для парного теста t – это когда измерения проводятся на одних и тех же субъектах до и после лечения.
Формула для парного t -критерия:
, где d — средняя разность, а SE — стандартная ошибка этой разности.
Групповые отклонения можно сравнить с помощью теста F . Критерий F представляет собой отношение дисперсий (вар 1/вар 2). Если F значительно отличается от 1,0, то делается вывод, что групповые дисперсии различаются значительно.
Дисперсионный анализ
Критерий Стьюдента t нельзя использовать для сравнения трех или более групп.Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
В ANOVA мы изучаем две дисперсии – (а) межгрупповую изменчивость и (б) внутригрупповую изменчивость. Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Однако дисперсия между группами (или эффект дисперсии) является результатом нашего лечения. Эти две оценки дисперсии сравниваются с помощью F-теста.
Упрощенная формула для статистики F составляет:
, где мс B — это средние квадраты между группами и мс W — это средние квадраты внутри групп.
Дисперсионный анализ с повторными измерениями
Как и в случае дисперсионного анализа, дисперсионный анализ с повторными измерениями анализирует равенство средних трех или более групп. Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Поскольку переменные измеряются по выборке в разные моменты времени, измерение зависимой переменной повторяется. Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Непараметрические тесты
Когда допущения о нормальности не выполняются, а выборочные средние ненормальны, распределенные параметрические тесты могут привести к ошибочным результатам. Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Как и для параметрических тестов, статистика теста сравнивается с известными значениями выборочного распределения этой статистики, и принимается или отвергается нулевая гипотеза. Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Таблица 5
Аналог параметрического и непараметрического критериев
Критерий медианы для одного образца: критерий знаков и критерий знакового ранга Вилкоксона . Эти тесты проверяют, является ли один экземпляр выборочных данных больше или меньше медианного эталонного значения.
Тест знаков
Этот тест проверяет гипотезу о медиане θ0 совокупности.Он проверяет нулевую гипотезу H0 = θ0. Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Если нулевая гипотеза верна, то будет равное количество знаков + и знаков -.
Проверка знаков игнорирует фактические значения данных и использует только знаки + или -. Поэтому это полезно, когда трудно измерить значения.
Знаковый ранговый критерий Уилкоксона
Критерий знаков имеет существенное ограничение, поскольку мы теряем количественную информацию данных и просто используем знаки + или –. Критерий знакового ранга Уилкоксона не только исследует наблюдаемые значения по сравнению с θ0, но также принимает во внимание относительные размеры, добавляя тесту больше статистической мощности. Как и в тесте на знак, если имеется наблюдаемое значение, равное эталонному значению θ0, это наблюдаемое значение исключается из выборки.
Критерий суммы рангов Уилкоксона ранжирует все точки данных по порядку, вычисляет сумму рангов каждой выборки и сравнивает разницу в суммах рангов.
Критерий Манна-Уитни
Он используется для проверки нулевой гипотезы о том, что две выборки имеют одинаковую медиану, или, наоборот, для проверки того, имеют ли наблюдения в одной выборке больше, чем наблюдения в другой.
Критерий Манна-Уитни сравнивает все данные (xi), принадлежащие группе X, и все данные (yi), принадлежащие группе Y, и вычисляет вероятность того, что xi больше yi: P (xi > yi).Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Критерий Колмогорова-Смирнова
Двухвыборочный критерий Колмогорова-Смирнова (КС) был разработан как общий метод для проверки того, взяты ли две случайные выборки из одного и того же распределения. Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Критерий Краскела-Уоллиса
Критерий Краскела-Уоллиса — это непараметрический критерий для анализа дисперсии.[14] Он анализирует, есть ли какая-либо разница в медианных значениях трех или более независимых выборок. Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Тест Джонкхира
В отличие от теста Крускала–Уоллиса, в тесте Джонкхира существует априорное упорядочение, которое придает ему большую статистическую силу, чем тест Крускала–Уоллиса.[14]
Критерий Фридмана
Критерий Фридмана — это непараметрический критерий для проверки различий между несколькими связанными выборками. Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тесты для анализа категориальных данных
Критерий хи-квадрат, точный критерий Фишера и критерий Макнемара используются для анализа категориальных или номинальных переменных.Тест хи-квадрат сравнивает частоты и проверяет, значительно ли отличаются наблюдаемые данные от ожидаемых данных, если не было различий между группами (т. Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
A Поправочный коэффициент Йейтса используется, когда размер выборки мал.Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Основные статистические инструменты в исследованиях и анализе данных
Описательная статистика[4] пытается описать взаимосвязь между переменными в выборке или генеральной совокупности. Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды.Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика
Степень, в которой наблюдения группируются вокруг центрального местоположения, описывается центральной тенденцией, а распространение к крайним значениям описывается степенью дисперсии.
Меры центральной тенденции
Меры центральной тенденции – это среднее значение, медиана и мода[6]. Среднее (или среднее арифметическое) — это сумма всех баллов, деленная на количество баллов. На среднее значение могут сильно влиять экстремальные переменные. Например, на среднее пребывание пациентов с отравлением фосфорорганическими соединениями в ОИТ может повлиять один пациент, который находится в ОИТ около 5 месяцев из-за септицемии. Экстремальные значения называются выбросами. Формула для среднего:
Среднее,
, где x = каждое наблюдение и n = количество наблюдений.Медиана[6] определяется как середина распределения в ранжированных данных (с половиной переменных в выборке выше и половиной ниже медианного значения), в то время как мода является наиболее часто встречающейся переменной в распределении. Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных.В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных.В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
, где σ 2 — дисперсия совокупности, X — среднее значение совокупности, X i — i элемент из популяции, а N — количество элементов в популяции. Дисперсия выборки определяется несколько иной формулой:
Дисперсия выборки определяется несколько иной формулой:
, где s 2 — дисперсия выборки, x — среднее значение выборки, x i — i th элемент выборки n — количество элементов в выборке. Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
, где σ — стандартное отклонение совокупности, X — среднее значение совокупности, X i — i th элемент совокупности и N – количество элементов в популяции. SD выборки определяется по несколько иной формуле:
SD выборки определяется по несколько иной формуле:
, где s — SD выборки, x — среднее значение выборки, x i — i th элемент выборки и n — количество элементов в выборке. Пример расчета вариации и стандартного отклонения показан на рис.
Таблица 2
Пример среднего значения, дисперсии, стандартного отклонения
Нормальное распределение или распределение Гаусса
Большинство биологических переменных обычно группируются вокруг центрального значения с симметричными положительными и отрицательными отклонениями относительно этой точки.[1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
Кривая нормального распределения
Наклонное распределение
Это распределение с асимметрией переменных относительно их среднего значения. В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
Кривые, показывающие распределение с отрицательной и положительной асимметрией
Статистика логического вывода
В статистике логического вывода данные анализируются из выборки, чтобы сделать выводы в большей совокупности совокупности. Цель состоит в том, чтобы ответить или проверить гипотезы. Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Вероятность — это мера вероятности того, что событие произойдет. Вероятность определяется как число от 0 до 1 (где 0 означает невозможность, а 1 означает уверенность).
В логической статистике термин «нулевая гипотеза» ( H 0 ‘ H-ноль ,’ ‘ H-нуль ‘) означает, что между рассматриваемыми переменными генеральной совокупности нет связи (различия). .[9]
.[9]
Альтернативная гипотеза ( H 1 и H a ) означает, что утверждение между переменными, как ожидается, будет истинным.[9]
Значение P (или вычисленная вероятность) представляет собой вероятность того, что событие произойдет случайно, если нулевая гипотеза верна. Значение P представляет собой число от 0 до 1 и интерпретируется исследователями при принятии решения об отклонении или сохранении нулевой гипотезы [].
Таблица 3
Значения P с интерпретацией
Если значение P меньше произвольно выбранного значения (известного как α или уровень значимости), нулевая гипотеза (H0) отклоняется [].Однако, если нулевая гипотеза (H0) ошибочно отвергается, это называется ошибкой первого рода.[11] Дополнительные сведения об альфа-ошибке, бета-ошибке и расчете размера выборки, а также о факторах, влияющих на них, рассматриваются в другом разделе этого выпуска Das S et al. .[12]
.[12]
Таблица 4
Иллюстрация для нулевой гипотезы НЕПАРАМЕТРИЧЕСКИЕ ТЕСТЫ
Числовые данные (количественные переменные), которые имеют нормальное распределение, анализируются с помощью параметрических тестов.[13]
Двумя основными предпосылками для параметрического статистического анализа являются: выборки и соответствующая им совокупность равны.
Однако, если распределение выборки смещено в одну сторону или распределение неизвестно из-за небольшого размера выборки, используются непараметрические[14] статистические методы.Непараметрические тесты используются для анализа порядковых и категориальных данных.
Параметрические тесты
Параметрические тесты предполагают, что данные представлены в количественном (числовом) масштабе с нормальным распределением основной совокупности. Выборки имеют одинаковую дисперсию (однородность дисперсий). Выборки случайным образом берутся из населения, и наблюдения внутри группы не зависят друг от друга. Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Критерий Стьюдента t
Критерий Стьюдента t используется для проверки нулевой гипотезы об отсутствии различий между средними значениями двух групп. Он используется в трех случаях:
Чтобы проверить, значительно ли среднее значение выборки (как оценка среднего значения совокупности) отличается от среднего значения данной совокупности (это одновыборочный t -тест)
Формула для одной выборки t — тест равен
, где X = среднее значение выборки, u = среднее значение генеральной совокупности и SE = стандартная ошибка среднего значимо (непарный т -тест).Формула для непарного t -теста:
, где X 1 − X 2 — разница между средними значениями двух групп, а SE обозначает стандартную ошибку разницы.
Проверить, значительно ли различаются средние значения совокупности, оцененные по двум зависимым выборкам (парный t -тест). Обычная установка для парного теста t – это когда измерения проводятся на одних и тех же субъектах до и после лечения.

Формула для парного t -критерия:
, где d — средняя разность, а SE — стандартная ошибка этой разности.
Групповые отклонения можно сравнить с помощью теста F . Критерий F представляет собой отношение дисперсий (вар 1/вар 2). Если F значительно отличается от 1,0, то делается вывод, что групповые дисперсии различаются значительно.
Дисперсионный анализ
Критерий Стьюдента t нельзя использовать для сравнения трех или более групп.Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
В ANOVA мы изучаем две дисперсии – (а) межгрупповую изменчивость и (б) внутригрупповую изменчивость. Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Однако дисперсия между группами (или эффект дисперсии) является результатом нашего лечения. Эти две оценки дисперсии сравниваются с помощью F-теста.
Упрощенная формула для статистики F составляет:
, где мс B — это средние квадраты между группами и мс W — это средние квадраты внутри групп.
Дисперсионный анализ с повторными измерениями
Как и в случае дисперсионного анализа, дисперсионный анализ с повторными измерениями анализирует равенство средних трех или более групп. Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Поскольку переменные измеряются по выборке в разные моменты времени, измерение зависимой переменной повторяется. Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Непараметрические тесты
Когда допущения о нормальности не выполняются, а выборочные средние ненормальны, распределенные параметрические тесты могут привести к ошибочным результатам.Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Как и для параметрических тестов, статистика теста сравнивается с известными значениями выборочного распределения этой статистики, и принимается или отвергается нулевая гипотеза. Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Таблица 5
Аналог параметрического и непараметрического критериев
Критерий медианы для одного образца: критерий знаков и критерий знакового ранга Вилкоксона . Эти тесты проверяют, является ли один экземпляр выборочных данных больше или меньше медианного эталонного значения.
Тест знаков
Этот тест проверяет гипотезу о медиане θ0 совокупности.Он проверяет нулевую гипотезу H0 = θ0. Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Если нулевая гипотеза верна, то будет равное количество знаков + и знаков -.
Проверка знаков игнорирует фактические значения данных и использует только знаки + или -. Поэтому это полезно, когда трудно измерить значения.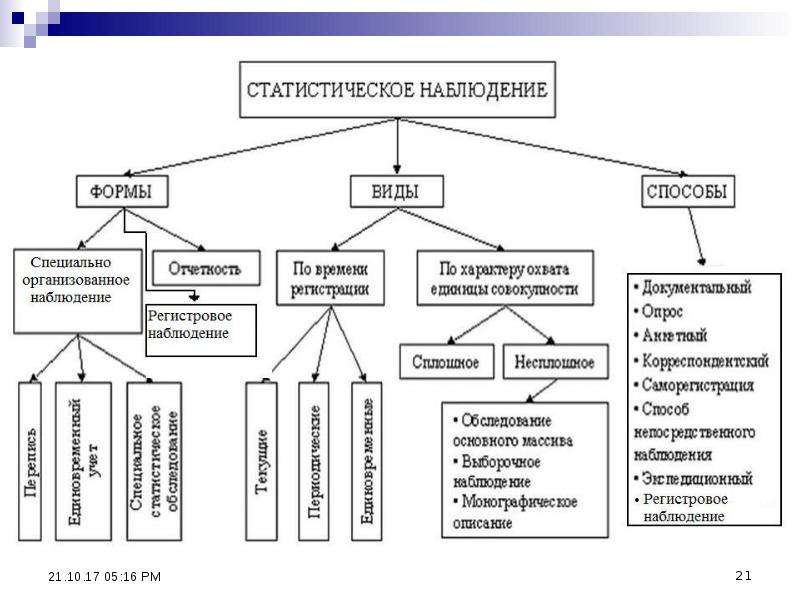
Знаковый ранговый критерий Уилкоксона
Критерий знаков имеет существенное ограничение, поскольку мы теряем количественную информацию данных и просто используем знаки + или –. Критерий знакового ранга Уилкоксона не только исследует наблюдаемые значения по сравнению с θ0, но также принимает во внимание относительные размеры, добавляя тесту больше статистической мощности. Как и в тесте на знак, если имеется наблюдаемое значение, равное эталонному значению θ0, это наблюдаемое значение исключается из выборки.
Критерий суммы рангов Уилкоксона ранжирует все точки данных по порядку, вычисляет сумму рангов каждой выборки и сравнивает разницу в суммах рангов.
Критерий Манна-Уитни
Он используется для проверки нулевой гипотезы о том, что две выборки имеют одинаковую медиану, или, наоборот, для проверки того, имеют ли наблюдения в одной выборке больше, чем наблюдения в другой.
Критерий Манна-Уитни сравнивает все данные (xi), принадлежащие группе X, и все данные (yi), принадлежащие группе Y, и вычисляет вероятность того, что xi больше yi: P (xi > yi). Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Критерий Колмогорова-Смирнова
Двухвыборочный критерий Колмогорова-Смирнова (КС) был разработан как общий метод для проверки того, взяты ли две случайные выборки из одного и того же распределения. Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Критерий Краскела-Уоллиса
Критерий Краскела-Уоллиса — это непараметрический критерий для анализа дисперсии.[14] Он анализирует, есть ли какая-либо разница в медианных значениях трех или более независимых выборок. Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Тест Джонкхира
В отличие от теста Крускала–Уоллиса, в тесте Джонкхира существует априорное упорядочение, которое придает ему большую статистическую силу, чем тест Крускала–Уоллиса.[14]
Критерий Фридмана
Критерий Фридмана — это непараметрический критерий для проверки различий между несколькими связанными выборками. Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тесты для анализа категориальных данных
Критерий хи-квадрат, точный критерий Фишера и критерий Макнемара используются для анализа категориальных или номинальных переменных.Тест хи-квадрат сравнивает частоты и проверяет, значительно ли отличаются наблюдаемые данные от ожидаемых данных, если не было различий между группами (т. Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
A Поправочный коэффициент Йейтса используется, когда размер выборки мал. Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Основные статистические инструменты в исследованиях и анализе данных
Описательная статистика[4] пытается описать взаимосвязь между переменными в выборке или генеральной совокупности. Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды.Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды.Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика
Степень, в которой наблюдения группируются вокруг центрального местоположения, описывается центральной тенденцией, а распространение к крайним значениям описывается степенью дисперсии.
Меры центральной тенденции
Меры центральной тенденции – это среднее значение, медиана и мода[6]. Среднее (или среднее арифметическое) — это сумма всех баллов, деленная на количество баллов. На среднее значение могут сильно влиять экстремальные переменные. Например, на среднее пребывание пациентов с отравлением фосфорорганическими соединениями в ОИТ может повлиять один пациент, который находится в ОИТ около 5 месяцев из-за септицемии. Экстремальные значения называются выбросами. Формула для среднего:
Экстремальные значения называются выбросами. Формула для среднего:
Среднее,
, где x = каждое наблюдение и n = количество наблюдений.Медиана[6] определяется как середина распределения в ранжированных данных (с половиной переменных в выборке выше и половиной ниже медианного значения), в то время как мода является наиболее часто встречающейся переменной в распределении. Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных.В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
, где σ 2 — дисперсия совокупности, X — среднее значение совокупности, X i — i элемент из популяции, а N — количество элементов в популяции.Дисперсия выборки определяется несколько иной формулой:
, где s 2 — дисперсия выборки, x — среднее значение выборки, x i — i th элемент выборки n — количество элементов в выборке. Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
, где σ — стандартное отклонение совокупности, X — среднее значение совокупности, X i — i th элемент совокупности и N – количество элементов в популяции.SD выборки определяется по несколько иной формуле:
, где s — SD выборки, x — среднее значение выборки, x i — i th элемент выборки и n — количество элементов в выборке. Пример расчета вариации и стандартного отклонения показан на рис.
Таблица 2
Пример среднего значения, дисперсии, стандартного отклонения
Нормальное распределение или распределение Гаусса
Большинство биологических переменных обычно группируются вокруг центрального значения с симметричными положительными и отрицательными отклонениями относительно этой точки. [1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
[1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
Кривая нормального распределения
Наклонное распределение
Это распределение с асимметрией переменных относительно их среднего значения. В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
Кривые, показывающие распределение с отрицательной и положительной асимметрией
Статистика логического вывода
В статистике логического вывода данные анализируются из выборки, чтобы сделать выводы в большей совокупности совокупности. Цель состоит в том, чтобы ответить или проверить гипотезы. Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Вероятность — это мера вероятности того, что событие произойдет. Вероятность определяется как число от 0 до 1 (где 0 означает невозможность, а 1 означает уверенность).
В логической статистике термин «нулевая гипотеза» ( H 0 ‘ H-ноль ,’ ‘ H-нуль ‘) означает, что между рассматриваемыми переменными генеральной совокупности нет связи (различия). .[9]
Альтернативная гипотеза ( H 1 и H a ) означает, что утверждение между переменными, как ожидается, будет истинным.[9]
Значение P (или вычисленная вероятность) представляет собой вероятность того, что событие произойдет случайно, если нулевая гипотеза верна. Значение P представляет собой число от 0 до 1 и интерпретируется исследователями при принятии решения об отклонении или сохранении нулевой гипотезы [].
Таблица 3
Значения P с интерпретацией
Если значение P меньше произвольно выбранного значения (известного как α или уровень значимости), нулевая гипотеза (H0) отклоняется [].Однако, если нулевая гипотеза (H0) ошибочно отвергается, это называется ошибкой первого рода.[11] Дополнительные сведения об альфа-ошибке, бета-ошибке и расчете размера выборки, а также о факторах, влияющих на них, рассматриваются в другом разделе этого выпуска Das S et al. .[12]
Таблица 4
Иллюстрация для нулевой гипотезы НЕПАРАМЕТРИЧЕСКИЕ ТЕСТЫ
Числовые данные (количественные переменные), которые имеют нормальное распределение, анализируются с помощью параметрических тестов.[13]
Двумя основными предпосылками для параметрического статистического анализа являются: выборки и соответствующая им совокупность равны.
Однако, если распределение выборки смещено в одну сторону или распределение неизвестно из-за небольшого размера выборки, используются непараметрические[14] статистические методы. Непараметрические тесты используются для анализа порядковых и категориальных данных.
Непараметрические тесты используются для анализа порядковых и категориальных данных.
Параметрические тесты
Параметрические тесты предполагают, что данные представлены в количественном (числовом) масштабе с нормальным распределением основной совокупности. Выборки имеют одинаковую дисперсию (однородность дисперсий). Выборки случайным образом берутся из населения, и наблюдения внутри группы не зависят друг от друга. Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Критерий Стьюдента t
Критерий Стьюдента t используется для проверки нулевой гипотезы об отсутствии различий между средними значениями двух групп. Он используется в трех случаях:
Чтобы проверить, значительно ли среднее значение выборки (как оценка среднего значения совокупности) отличается от среднего значения данной совокупности (это одновыборочный t -тест)
Формула для одной выборки t — тест равен
, где X = среднее значение выборки, u = среднее значение генеральной совокупности и SE = стандартная ошибка среднего значимо (непарный т -тест).
Формула для непарного t -теста:, где X 1 − X 2 — разница между средними значениями двух групп, а SE обозначает стандартную ошибку разницы.
Проверить, значительно ли различаются средние значения совокупности, оцененные по двум зависимым выборкам (парный t -тест). Обычная установка для парного теста t – это когда измерения проводятся на одних и тех же субъектах до и после лечения.
 Формула для непарного t -теста:
Формула для непарного t -теста:Формула для парного t -критерия:
, где d — средняя разность, а SE — стандартная ошибка этой разности.
Групповые отклонения можно сравнить с помощью теста F . Критерий F представляет собой отношение дисперсий (вар 1/вар 2). Если F значительно отличается от 1,0, то делается вывод, что групповые дисперсии различаются значительно.
Дисперсионный анализ
Критерий Стьюдента t нельзя использовать для сравнения трех или более групп. Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
В ANOVA мы изучаем две дисперсии – (а) межгрупповую изменчивость и (б) внутригрупповую изменчивость. Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Однако дисперсия между группами (или эффект дисперсии) является результатом нашего лечения. Эти две оценки дисперсии сравниваются с помощью F-теста.
Упрощенная формула для статистики F составляет:
, где мс B — это средние квадраты между группами и мс W — это средние квадраты внутри групп.
Дисперсионный анализ с повторными измерениями
Как и в случае дисперсионного анализа, дисперсионный анализ с повторными измерениями анализирует равенство средних трех или более групп. Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Поскольку переменные измеряются по выборке в разные моменты времени, измерение зависимой переменной повторяется. Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Непараметрические тесты
Когда допущения о нормальности не выполняются, а выборочные средние ненормальны, распределенные параметрические тесты могут привести к ошибочным результатам.Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
То есть они обычно имеют меньшую мощность.
Как и для параметрических тестов, статистика теста сравнивается с известными значениями выборочного распределения этой статистики, и принимается или отвергается нулевая гипотеза. Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Таблица 5
Аналог параметрического и непараметрического критериев
Критерий медианы для одного образца: критерий знаков и критерий знакового ранга Вилкоксона . Эти тесты проверяют, является ли один экземпляр выборочных данных больше или меньше медианного эталонного значения.
Тест знаков
Этот тест проверяет гипотезу о медиане θ0 совокупности.Он проверяет нулевую гипотезу H0 = θ0. Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Если нулевая гипотеза верна, то будет равное количество знаков + и знаков -.
Проверка знаков игнорирует фактические значения данных и использует только знаки + или -. Поэтому это полезно, когда трудно измерить значения.
Знаковый ранговый критерий Уилкоксона
Критерий знаков имеет существенное ограничение, поскольку мы теряем количественную информацию данных и просто используем знаки + или –. Критерий знакового ранга Уилкоксона не только исследует наблюдаемые значения по сравнению с θ0, но также принимает во внимание относительные размеры, добавляя тесту больше статистической мощности. Как и в тесте на знак, если имеется наблюдаемое значение, равное эталонному значению θ0, это наблюдаемое значение исключается из выборки.
Критерий суммы рангов Уилкоксона ранжирует все точки данных по порядку, вычисляет сумму рангов каждой выборки и сравнивает разницу в суммах рангов.
Критерий Манна-Уитни
Он используется для проверки нулевой гипотезы о том, что две выборки имеют одинаковую медиану, или, наоборот, для проверки того, имеют ли наблюдения в одной выборке больше, чем наблюдения в другой.
Критерий Манна-Уитни сравнивает все данные (xi), принадлежащие группе X, и все данные (yi), принадлежащие группе Y, и вычисляет вероятность того, что xi больше yi: P (xi > yi).Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Критерий Колмогорова-Смирнова
Двухвыборочный критерий Колмогорова-Смирнова (КС) был разработан как общий метод для проверки того, взяты ли две случайные выборки из одного и того же распределения. Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Критерий Краскела-Уоллиса
Критерий Краскела-Уоллиса — это непараметрический критерий для анализа дисперсии.[14] Он анализирует, есть ли какая-либо разница в медианных значениях трех или более независимых выборок. Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Тест Джонкхира
В отличие от теста Крускала–Уоллиса, в тесте Джонкхира существует априорное упорядочение, которое придает ему большую статистическую силу, чем тест Крускала–Уоллиса.[14]
Критерий Фридмана
Критерий Фридмана — это непараметрический критерий для проверки различий между несколькими связанными выборками. Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тесты для анализа категориальных данных
Критерий хи-квадрат, точный критерий Фишера и критерий Макнемара используются для анализа категориальных или номинальных переменных.Тест хи-квадрат сравнивает частоты и проверяет, значительно ли отличаются наблюдаемые данные от ожидаемых данных, если не было различий между группами (т. Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
A Поправочный коэффициент Йейтса используется, когда размер выборки мал.Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Основные статистические инструменты в исследованиях и анализе данных
Описательная статистика[4] пытается описать взаимосвязь между переменными в выборке или генеральной совокупности. Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды.Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика
Степень, в которой наблюдения группируются вокруг центрального местоположения, описывается центральной тенденцией, а распространение к крайним значениям описывается степенью дисперсии.
Меры центральной тенденции
Меры центральной тенденции – это среднее значение, медиана и мода[6]. Среднее (или среднее арифметическое) — это сумма всех баллов, деленная на количество баллов. На среднее значение могут сильно влиять экстремальные переменные. Например, на среднее пребывание пациентов с отравлением фосфорорганическими соединениями в ОИТ может повлиять один пациент, который находится в ОИТ около 5 месяцев из-за септицемии. Экстремальные значения называются выбросами. Формула для среднего:
Среднее,
, где x = каждое наблюдение и n = количество наблюдений.Медиана[6] определяется как середина распределения в ранжированных данных (с половиной переменных в выборке выше и половиной ниже медианного значения), в то время как мода является наиболее часто встречающейся переменной в распределении. Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных. В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
, где σ 2 — дисперсия совокупности, X — среднее значение совокупности, X i — i элемент из популяции, а N — количество элементов в популяции.Дисперсия выборки определяется несколько иной формулой:
, где s 2 — дисперсия выборки, x — среднее значение выборки, x i — i th элемент выборки n — количество элементов в выборке. Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
, где σ — стандартное отклонение совокупности, X — среднее значение совокупности, X i — i th элемент совокупности и N – количество элементов в популяции.SD выборки определяется по несколько иной формуле:
, где s — SD выборки, x — среднее значение выборки, x i — i th элемент выборки и n — количество элементов в выборке. Пример расчета вариации и стандартного отклонения показан на рис.
Пример расчета вариации и стандартного отклонения показан на рис.
Таблица 2
Пример среднего значения, дисперсии, стандартного отклонения
Нормальное распределение или распределение Гаусса
Большинство биологических переменных обычно группируются вокруг центрального значения с симметричными положительными и отрицательными отклонениями относительно этой точки.[1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
Кривая нормального распределения
Наклонное распределение
Это распределение с асимметрией переменных относительно их среднего значения. В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
Кривые, показывающие распределение с отрицательной и положительной асимметрией
Статистика логического вывода
В статистике логического вывода данные анализируются из выборки, чтобы сделать выводы в большей совокупности совокупности. Цель состоит в том, чтобы ответить или проверить гипотезы. Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Вероятность — это мера вероятности того, что событие произойдет. Вероятность определяется как число от 0 до 1 (где 0 означает невозможность, а 1 означает уверенность).
В логической статистике термин «нулевая гипотеза» ( H 0 ‘ H-ноль ,’ ‘ H-нуль ‘) означает, что между рассматриваемыми переменными генеральной совокупности нет связи (различия). .[9]
Альтернативная гипотеза ( H 1 и H a ) означает, что утверждение между переменными, как ожидается, будет истинным. [9]
[9]
Значение P (или вычисленная вероятность) представляет собой вероятность того, что событие произойдет случайно, если нулевая гипотеза верна. Значение P представляет собой число от 0 до 1 и интерпретируется исследователями при принятии решения об отклонении или сохранении нулевой гипотезы [].
Таблица 3
Значения P с интерпретацией
Если значение P меньше произвольно выбранного значения (известного как α или уровень значимости), нулевая гипотеза (H0) отклоняется [].Однако, если нулевая гипотеза (H0) ошибочно отвергается, это называется ошибкой первого рода.[11] Дополнительные сведения об альфа-ошибке, бета-ошибке и расчете размера выборки, а также о факторах, влияющих на них, рассматриваются в другом разделе этого выпуска Das S et al. .[12]
Таблица 4
Иллюстрация для нулевой гипотезы НЕПАРАМЕТРИЧЕСКИЕ ТЕСТЫ
Числовые данные (количественные переменные), которые имеют нормальное распределение, анализируются с помощью параметрических тестов.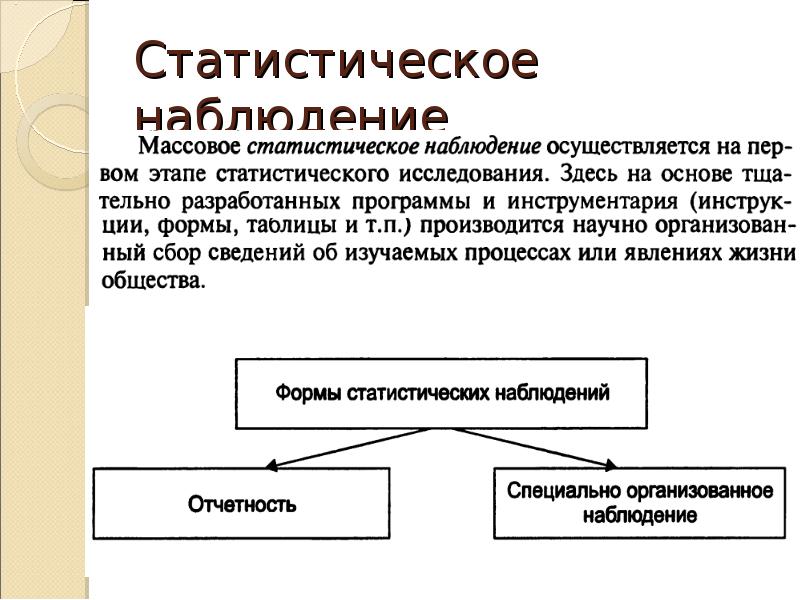 [13]
[13]
Двумя основными предпосылками для параметрического статистического анализа являются: выборки и соответствующая им совокупность равны.
Однако, если распределение выборки смещено в одну сторону или распределение неизвестно из-за небольшого размера выборки, используются непараметрические[14] статистические методы.Непараметрические тесты используются для анализа порядковых и категориальных данных.
Параметрические тесты
Параметрические тесты предполагают, что данные представлены в количественном (числовом) масштабе с нормальным распределением основной совокупности. Выборки имеют одинаковую дисперсию (однородность дисперсий). Выборки случайным образом берутся из населения, и наблюдения внутри группы не зависят друг от друга. Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Критерий Стьюдента t
Критерий Стьюдента t используется для проверки нулевой гипотезы об отсутствии различий между средними значениями двух групп. Он используется в трех случаях:
Он используется в трех случаях:
Чтобы проверить, значительно ли среднее значение выборки (как оценка среднего значения совокупности) отличается от среднего значения данной совокупности (это одновыборочный t -тест)
Формула для одной выборки t — тест равен
, где X = среднее значение выборки, u = среднее значение генеральной совокупности и SE = стандартная ошибка среднего значимо (непарный т -тест).Формула для непарного t -теста:
, где X 1 − X 2 — разница между средними значениями двух групп, а SE обозначает стандартную ошибку разницы.
Проверить, значительно ли различаются средние значения совокупности, оцененные по двум зависимым выборкам (парный t -тест). Обычная установка для парного теста t – это когда измерения проводятся на одних и тех же субъектах до и после лечения.
Формула для парного t -критерия:
, где d — средняя разность, а SE — стандартная ошибка этой разности.
Групповые отклонения можно сравнить с помощью теста F . Критерий F представляет собой отношение дисперсий (вар 1/вар 2). Если F значительно отличается от 1,0, то делается вывод, что групповые дисперсии различаются значительно.
Дисперсионный анализ
Критерий Стьюдента t нельзя использовать для сравнения трех или более групп.Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
В ANOVA мы изучаем две дисперсии – (а) межгрупповую изменчивость и (б) внутригрупповую изменчивость. Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Однако дисперсия между группами (или эффект дисперсии) является результатом нашего лечения. Эти две оценки дисперсии сравниваются с помощью F-теста.
Упрощенная формула для статистики F составляет:
, где мс B — это средние квадраты между группами и мс W — это средние квадраты внутри групп.
Дисперсионный анализ с повторными измерениями
Как и в случае дисперсионного анализа, дисперсионный анализ с повторными измерениями анализирует равенство средних трех или более групп. Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Поскольку переменные измеряются по выборке в разные моменты времени, измерение зависимой переменной повторяется. Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Непараметрические тесты
Когда допущения о нормальности не выполняются, а выборочные средние ненормальны, распределенные параметрические тесты могут привести к ошибочным результатам. Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Как и для параметрических тестов, статистика теста сравнивается с известными значениями выборочного распределения этой статистики, и принимается или отвергается нулевая гипотеза. Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Таблица 5
Аналог параметрического и непараметрического критериев
Критерий медианы для одного образца: критерий знаков и критерий знакового ранга Вилкоксона . Эти тесты проверяют, является ли один экземпляр выборочных данных больше или меньше медианного эталонного значения.
Тест знаков
Этот тест проверяет гипотезу о медиане θ0 совокупности.Он проверяет нулевую гипотезу H0 = θ0. Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Если нулевая гипотеза верна, то будет равное количество знаков + и знаков -.
Проверка знаков игнорирует фактические значения данных и использует только знаки + или -. Поэтому это полезно, когда трудно измерить значения.
Знаковый ранговый критерий Уилкоксона
Критерий знаков имеет существенное ограничение, поскольку мы теряем количественную информацию данных и просто используем знаки + или –. Критерий знакового ранга Уилкоксона не только исследует наблюдаемые значения по сравнению с θ0, но также принимает во внимание относительные размеры, добавляя тесту больше статистической мощности. Как и в тесте на знак, если имеется наблюдаемое значение, равное эталонному значению θ0, это наблюдаемое значение исключается из выборки.
Критерий суммы рангов Уилкоксона ранжирует все точки данных по порядку, вычисляет сумму рангов каждой выборки и сравнивает разницу в суммах рангов.
Критерий Манна-Уитни
Он используется для проверки нулевой гипотезы о том, что две выборки имеют одинаковую медиану, или, наоборот, для проверки того, имеют ли наблюдения в одной выборке больше, чем наблюдения в другой.
Критерий Манна-Уитни сравнивает все данные (xi), принадлежащие группе X, и все данные (yi), принадлежащие группе Y, и вычисляет вероятность того, что xi больше yi: P (xi > yi).Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Критерий Колмогорова-Смирнова
Двухвыборочный критерий Колмогорова-Смирнова (КС) был разработан как общий метод для проверки того, взяты ли две случайные выборки из одного и того же распределения. Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Критерий Краскела-Уоллиса
Критерий Краскела-Уоллиса — это непараметрический критерий для анализа дисперсии.[14] Он анализирует, есть ли какая-либо разница в медианных значениях трех или более независимых выборок. Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Тест Джонкхира
В отличие от теста Крускала–Уоллиса, в тесте Джонкхира существует априорное упорядочение, которое придает ему большую статистическую силу, чем тест Крускала–Уоллиса.[14]
Критерий Фридмана
Критерий Фридмана — это непараметрический критерий для проверки различий между несколькими связанными выборками. Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тесты для анализа категориальных данных
Критерий хи-квадрат, точный критерий Фишера и критерий Макнемара используются для анализа категориальных или номинальных переменных.Тест хи-квадрат сравнивает частоты и проверяет, значительно ли отличаются наблюдаемые данные от ожидаемых данных, если не было различий между группами (т. Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
A Поправочный коэффициент Йейтса используется, когда размер выборки мал.Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Основные статистические инструменты в исследованиях и анализе данных
Описательная статистика[4] пытается описать взаимосвязь между переменными в выборке или генеральной совокупности. Описательная статистика предоставляет сводку данных в виде среднего значения, медианы и моды.Инференциальная статистика [4] использует случайную выборку данных, взятых из совокупности, для описания и выводов о всей совокупности. Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Это ценно, когда нет возможности обследовать каждого члена всей популяции. Примеры описательной и логической статистики проиллюстрированы в .
Описательная статистика
Степень, в которой наблюдения группируются вокруг центрального местоположения, описывается центральной тенденцией, а распространение к крайним значениям описывается степенью дисперсии.
Меры центральной тенденции
Меры центральной тенденции – это среднее значение, медиана и мода[6]. Среднее (или среднее арифметическое) — это сумма всех баллов, деленная на количество баллов. На среднее значение могут сильно влиять экстремальные переменные. Например, на среднее пребывание пациентов с отравлением фосфорорганическими соединениями в ОИТ может повлиять один пациент, который находится в ОИТ около 5 месяцев из-за септицемии. Экстремальные значения называются выбросами. Формула для среднего:
Среднее,
, где x = каждое наблюдение и n = количество наблюдений.Медиана[6] определяется как середина распределения в ранжированных данных (с половиной переменных в выборке выше и половиной ниже медианного значения), в то время как мода является наиболее часто встречающейся переменной в распределении. Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных.В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
Диапазон определяет разброс или изменчивость выборки.[7] Он описывается минимальным и максимальным значениями переменных. Если мы ранжируем данные и после ранжирования сгруппируем наблюдения в процентили, мы сможем получить более точную информацию о характере разброса переменных.В процентилях мы ранжируем наблюдения на 100 равных частей. Затем мы можем описать 25%, 50%, 75% или любую другую процентную величину. Медиана — это 50 900 19 900 20 перцентилей. Межквартильный диапазон будет представлять собой наблюдения в середине 50% наблюдений относительно медианы (25 -75 процентиль). Дисперсия[7] — это мера того, насколько рассредоточено распределение. Это дает представление о том, насколько близко отдельные кластеры наблюдения относятся к среднему значению. Дисперсия совокупности определяется по следующей формуле:
, где σ 2 — дисперсия совокупности, X — среднее значение совокупности, X i — i элемент из популяции, а N — количество элементов в популяции. Дисперсия выборки определяется несколько иной формулой:
Дисперсия выборки определяется несколько иной формулой:
, где s 2 — дисперсия выборки, x — среднее значение выборки, x i — i th элемент выборки n — количество элементов в выборке. Формула дисперсии населения имеет значение « n » в качестве знаменателя. Выражение « n −1» известно как степень свободы и на единицу меньше числа параметров.Каждое наблюдение может варьироваться, кроме последнего, которое должно быть определенным значением. Дисперсия измеряется в квадратных единицах. Чтобы упростить интерпретацию данных и сохранить основную единицу наблюдения, используется квадратный корень из дисперсии. Квадратный корень дисперсии представляет собой стандартное отклонение (SD).[8] Стандартное отклонение совокупности определяется по следующей формуле:
, где σ — стандартное отклонение совокупности, X — среднее значение совокупности, X i — i th элемент совокупности и N – количество элементов в популяции. SD выборки определяется по несколько иной формуле:
SD выборки определяется по несколько иной формуле:
, где s — SD выборки, x — среднее значение выборки, x i — i th элемент выборки и n — количество элементов в выборке. Пример расчета вариации и стандартного отклонения показан на рис.
Таблица 2
Пример среднего значения, дисперсии, стандартного отклонения
Нормальное распределение или распределение Гаусса
Большинство биологических переменных обычно группируются вокруг центрального значения с симметричными положительными и отрицательными отклонениями относительно этой точки.[1] Стандартная кривая нормального распределения имеет форму симметричного колокола. На кривой нормального распределения около 68% баллов находятся в пределах 1 стандартного отклонения от среднего. Около 95% баллов находятся в пределах 2 СО от среднего и 99% в пределах 3 СО от среднего [].
Кривая нормального распределения
Наклонное распределение
Это распределение с асимметрией переменных относительно их среднего значения.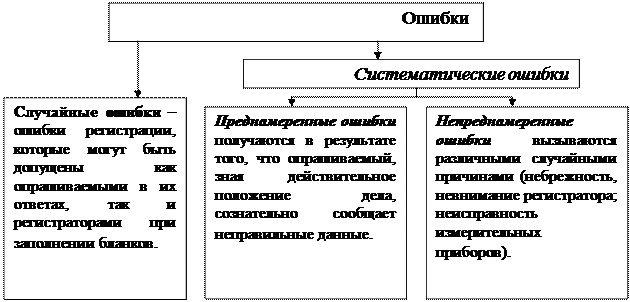 В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
В распределении с отрицательной асимметрией [] масса распределения сосредоточена справа от .В положительно асимметричном распределении [] масса распределения сосредоточена в левой части рисунка, что приводит к более длинному правому хвосту.
Кривые, показывающие распределение с отрицательной и положительной асимметрией
Статистика логического вывода
В статистике логического вывода данные анализируются из выборки, чтобы сделать выводы в большей совокупности совокупности. Цель состоит в том, чтобы ответить или проверить гипотезы. Гипотеза (множественное число гипотез) — это предлагаемое объяснение явления.Таким образом, проверки гипотез являются процедурами для принятия рациональных решений о реальности наблюдаемых эффектов.
Вероятность — это мера вероятности того, что событие произойдет. Вероятность определяется как число от 0 до 1 (где 0 означает невозможность, а 1 означает уверенность).
В логической статистике термин «нулевая гипотеза» ( H 0 ‘ H-ноль ,’ ‘ H-нуль ‘) означает, что между рассматриваемыми переменными генеральной совокупности нет связи (различия). .[9]
.[9]
Альтернативная гипотеза ( H 1 и H a ) означает, что утверждение между переменными, как ожидается, будет истинным.[9]
Значение P (или вычисленная вероятность) представляет собой вероятность того, что событие произойдет случайно, если нулевая гипотеза верна. Значение P представляет собой число от 0 до 1 и интерпретируется исследователями при принятии решения об отклонении или сохранении нулевой гипотезы [].
Таблица 3
Значения P с интерпретацией
Если значение P меньше произвольно выбранного значения (известного как α или уровень значимости), нулевая гипотеза (H0) отклоняется [].Однако, если нулевая гипотеза (H0) ошибочно отвергается, это называется ошибкой первого рода.[11] Дополнительные сведения об альфа-ошибке, бета-ошибке и расчете размера выборки, а также о факторах, влияющих на них, рассматриваются в другом разделе этого выпуска Das S et al. .[12]
.[12]
Таблица 4
Иллюстрация для нулевой гипотезы НЕПАРАМЕТРИЧЕСКИЕ ТЕСТЫ
Числовые данные (количественные переменные), которые имеют нормальное распределение, анализируются с помощью параметрических тестов.[13]
Двумя основными предпосылками для параметрического статистического анализа являются: выборки и соответствующая им совокупность равны.
Однако, если распределение выборки смещено в одну сторону или распределение неизвестно из-за небольшого размера выборки, используются непараметрические[14] статистические методы.Непараметрические тесты используются для анализа порядковых и категориальных данных.
Параметрические тесты
Параметрические тесты предполагают, что данные представлены в количественном (числовом) масштабе с нормальным распределением основной совокупности. Выборки имеют одинаковую дисперсию (однородность дисперсий). Выборки случайным образом берутся из населения, и наблюдения внутри группы не зависят друг от друга. Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Обычно используемыми параметрическими тестами являются тест Стьюдента t , дисперсионный анализ (ANOVA) и повторные измерения ANOVA.
Критерий Стьюдента t
Критерий Стьюдента t используется для проверки нулевой гипотезы об отсутствии различий между средними значениями двух групп. Он используется в трех случаях:
Чтобы проверить, значительно ли среднее значение выборки (как оценка среднего значения совокупности) отличается от среднего значения данной совокупности (это одновыборочный t -тест)
Формула для одной выборки t — тест равен
, где X = среднее значение выборки, u = среднее значение генеральной совокупности и SE = стандартная ошибка среднего значимо (непарный т -тест).Формула для непарного t -теста:
, где X 1 − X 2 — разница между средними значениями двух групп, а SE обозначает стандартную ошибку разницы.
Проверить, значительно ли различаются средние значения совокупности, оцененные по двум зависимым выборкам (парный t -тест). Обычная установка для парного теста t – это когда измерения проводятся на одних и тех же субъектах до и после лечения.

Формула для парного t -критерия:
, где d — средняя разность, а SE — стандартная ошибка этой разности.
Групповые отклонения можно сравнить с помощью теста F . Критерий F представляет собой отношение дисперсий (вар 1/вар 2). Если F значительно отличается от 1,0, то делается вывод, что групповые дисперсии различаются значительно.
Дисперсионный анализ
Критерий Стьюдента t нельзя использовать для сравнения трех или более групп.Цель ANOVA состоит в том, чтобы проверить, есть ли какая-либо существенная разница между средними значениями двух или более групп.
В ANOVA мы изучаем две дисперсии – (а) межгрупповую изменчивость и (б) внутригрупповую изменчивость. Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Внутригрупповая изменчивость (дисперсия ошибок) — это вариация, которая не может быть учтена в плане исследования. Он основан на случайных различиях, присутствующих в наших выборках.
Однако дисперсия между группами (или эффект дисперсии) является результатом нашего лечения. Эти две оценки дисперсии сравниваются с помощью F-теста.
Упрощенная формула для статистики F составляет:
, где мс B — это средние квадраты между группами и мс W — это средние квадраты внутри групп.
Дисперсионный анализ с повторными измерениями
Как и в случае дисперсионного анализа, дисперсионный анализ с повторными измерениями анализирует равенство средних трех или более групп. Однако дисперсионный анализ с повторным измерением используется, когда все переменные выборки измеряются в разных условиях или в разные моменты времени.
Поскольку переменные измеряются по выборке в разные моменты времени, измерение зависимой переменной повторяется. Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Использование стандартного дисперсионного анализа в этом случае не подходит, поскольку он не может смоделировать корреляцию между повторяющимися измерениями: данные нарушают предположение о независимости дисперсионного анализа. Следовательно, при измерении повторяющихся зависимых переменных следует использовать повторные измерения ANOVA.
Непараметрические тесты
Когда допущения о нормальности не выполняются, а выборочные средние ненормальны, распределенные параметрические тесты могут привести к ошибочным результатам.Непараметрические тесты (тест без распределения) используются в такой ситуации, поскольку они не требуют предположения о нормальности.[15] Непараметрические тесты могут не обнаружить существенной разницы по сравнению с параметрическим тестом. То есть они обычно имеют меньшую мощность.
Как и для параметрических тестов, статистика теста сравнивается с известными значениями выборочного распределения этой статистики, и принимается или отвергается нулевая гипотеза. Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Типы методов непараметрического анализа и соответствующие методы параметрического анализа описаны в .
Таблица 5
Аналог параметрического и непараметрического критериев
Критерий медианы для одного образца: критерий знаков и критерий знакового ранга Вилкоксона . Эти тесты проверяют, является ли один экземпляр выборочных данных больше или меньше медианного эталонного значения.
Тест знаков
Этот тест проверяет гипотезу о медиане θ0 совокупности.Он проверяет нулевую гипотезу H0 = θ0. Когда наблюдаемое значение (Xi) больше эталонного значения (θ0), оно помечается как +. Если наблюдаемое значение меньше эталонного значения, оно помечается знаком -. Если наблюдаемое значение равно эталонному значению (θ0), оно исключается из выборки.
Если нулевая гипотеза верна, то будет равное количество знаков + и знаков -.
Проверка знаков игнорирует фактические значения данных и использует только знаки + или -. Поэтому это полезно, когда трудно измерить значения.
Знаковый ранговый критерий Уилкоксона
Критерий знаков имеет существенное ограничение, поскольку мы теряем количественную информацию данных и просто используем знаки + или –. Критерий знакового ранга Уилкоксона не только исследует наблюдаемые значения по сравнению с θ0, но также принимает во внимание относительные размеры, добавляя тесту больше статистической мощности. Как и в тесте на знак, если имеется наблюдаемое значение, равное эталонному значению θ0, это наблюдаемое значение исключается из выборки.
Критерий суммы рангов Уилкоксона ранжирует все точки данных по порядку, вычисляет сумму рангов каждой выборки и сравнивает разницу в суммах рангов.
Критерий Манна-Уитни
Он используется для проверки нулевой гипотезы о том, что две выборки имеют одинаковую медиану, или, наоборот, для проверки того, имеют ли наблюдения в одной выборке больше, чем наблюдения в другой.
Критерий Манна-Уитни сравнивает все данные (xi), принадлежащие группе X, и все данные (yi), принадлежащие группе Y, и вычисляет вероятность того, что xi больше yi: P (xi > yi). Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Нулевая гипотеза утверждает, что P (xi > yi) = P (xi < yi) = 1/2, тогда как альтернативная гипотеза утверждает, что P (xi > yi) ≠ 1/2.
Критерий Колмогорова-Смирнова
Двухвыборочный критерий Колмогорова-Смирнова (КС) был разработан как общий метод для проверки того, взяты ли две случайные выборки из одного и того же распределения. Нулевая гипотеза теста KS состоит в том, что оба распределения идентичны. Статистика теста KS представляет собой расстояние между двумя эмпирическими распределениями, рассчитанное как максимальная абсолютная разница между их кумулятивными кривыми.
Критерий Краскела-Уоллиса
Критерий Краскела-Уоллиса — это непараметрический критерий для анализа дисперсии.[14] Он анализирует, есть ли какая-либо разница в медианных значениях трех или более независимых выборок. Значения данных ранжируются в порядке возрастания, после чего вычисляются ранговые суммы с последующим вычислением тестовой статистики.
Тест Джонкхира
В отличие от теста Крускала–Уоллиса, в тесте Джонкхира существует априорное упорядочение, которое придает ему большую статистическую силу, чем тест Крускала–Уоллиса.[14]
Критерий Фридмана
Критерий Фридмана — это непараметрический критерий для проверки различий между несколькими связанными выборками. Тест Фридмана является альтернативой повторным измерениям ANOVA, который используется, когда один и тот же параметр был измерен в разных условиях у одних и тех же субъектов.
Тесты для анализа категориальных данных
Критерий хи-квадрат, точный критерий Фишера и критерий Макнемара используются для анализа категориальных или номинальных переменных.Тест хи-квадрат сравнивает частоты и проверяет, значительно ли отличаются наблюдаемые данные от ожидаемых данных, если не было различий между группами (т. Е. Нулевая гипотеза). Он рассчитывается путем деления квадрата разницы между наблюдаемыми ( O ) и ожидаемыми ( E ) данными (или отклонением d ) на ожидаемые данные по следующей формуле:
A Поправочный коэффициент Йейтса используется, когда размер выборки мал. Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
Точный критерий Фишера используется для определения наличия неслучайных ассоциаций между двумя категориальными переменными. Он не предполагает случайной выборки и вместо того, чтобы соотносить рассчитанную статистику с распределением выборки, вычисляет точную вероятность. Критерий Макнемара используется для парных номинальных данных. Применяется к таблице 2 × 2 с парно-зависимыми выборками. Он используется для определения того, равны ли частоты строк и столбцов (то есть существует ли «маргинальная однородность»). Нулевая гипотеза состоит в том, что парные пропорции равны.Тест хи-квадрат Мантеля-Хензеля является многомерным тестом, поскольку он анализирует несколько группирующих переменных. Он стратифицируется в соответствии с назначенными вмешивающимися переменными и идентифицирует все, что влияет на первичную переменную результата. Если переменная результата является дихотомической, то используется логистическая регрессия.
7 Методы сбора данных и инструменты для исследований
Основной потребностью в сборе данных является получение качественных доказательств, которые направлены на ответы на все поставленные вопросы. Благодаря сбору данных предприятия или руководство могут получить качественную информацию, которая является необходимым условием для принятия обоснованных решений.
Благодаря сбору данных предприятия или руководство могут получить качественную информацию, которая является необходимым условием для принятия обоснованных решений.
Для повышения качества информации целесообразно собирать данные, чтобы вы могли делать выводы и принимать обоснованные решения о том, что считается фактическим.
В конце этой статьи вы поймете, почему выбор наилучшего метода сбора данных необходим для достижения поставленной цели.
Зарегистрируйтесь в Formplus Builder, чтобы создавать предпочитаемые онлайн-опросы или анкеты для сбора данных.Вам не нужно быть технически подкованным! Начните создавать качественные анкеты с Formplus.
Зарегистрируйтесь для сбора онлайн-данных с помощью Formplus
Что такое сбор данных?
Сбор данных представляет собой методический процесс сбора и анализа конкретной информации для предложения решений соответствующих вопросов и оценки результатов. Он фокусируется на выяснении всего, что касается конкретного предмета. Данные собираются для дальнейшей проверки гипотез, направленных на объяснение явления.
Он фокусируется на выяснении всего, что касается конкретного предмета. Данные собираются для дальнейшей проверки гипотез, направленных на объяснение явления.
Проверка гипотез устраняет предположения при выдвижении предложений на основе разума.
Для сборщиков данных существует ряд результатов, для которых собираются данные. Но ключевая цель, для которой собираются данные, состоит в том, чтобы поставить исследователя в выгодное положение, позволяющее делать прогнозы о будущих вероятностях и тенденциях.
Основными формами, в которых могут быть собраны данные, являются первичные и вторичные данные. В то время как первые собираются исследователем из первых рук, вторые собираются человеком, не являющимся пользователем.
Типы сбора данныхПрежде чем перейти к теме различных типов сбора данных. Уместно отметить, что сбор данных сам по себе подпадает под две широкие категории; Сбор первичных данных и сбор вторичных данных.
Сбор первичных данных Сбор первичных данных по определению представляет собой сбор необработанных данных, собранных в источнике. Это процесс сбора исходных данных, собранных исследователем для конкретной исследовательской цели. Далее его можно разделить на два сегмента; качественные исследования и количественные методы сбора данных.
Это процесс сбора исходных данных, собранных исследователем для конкретной исследовательской цели. Далее его можно разделить на два сегмента; качественные исследования и количественные методы сбора данных.
- Качественный метод исследования
Качественные методы исследования сбора данных не включают сбор данных, который включает числа или необходимость вывода посредством математических расчетов, а основан на не поддающихся количественной оценке элементах, таких как чувство или эмоция исследователя.Примером такого метода является открытая анкета.
Количественные методы представлены в цифрах и требуют математического расчета для вывода. Примером может служить использование вопросника с закрытыми вопросами для получения цифр, подлежащих математическому расчету. А также методы корреляции и регрессии, среднего, моды и медианы.
Читайте также: 15 причин предпочесть количественные исследования качественным
 formpl.us/auth» data-text=»» data-button-text=»Use Formplus as a Primary Data Collection Tool»>
Используйте Formplus в качестве основного инструмента сбора данных Сбор вторичных данных
formpl.us/auth» data-text=»» data-button-text=»Use Formplus as a Primary Data Collection Tool»>
Используйте Formplus в качестве основного инструмента сбора данных Сбор вторичных данных Сбор вторичных данных, с другой стороны, называется сбором вторичных данных, собранных лицом, которое не является первоначальным пользователем.Это процесс сбора данных, которые уже существуют, будь то уже опубликованные книги, журналы и/или онлайн-порталы. С точки зрения простоты, это намного дешевле и проще в сборе.
Выбор между сбором первичных данных и сбором вторичных данных зависит от характера, объема и области вашего исследования, а также от его целей и задач.
ВАЖНОСТЬ СБОРА ДАННЫХСуществует множество основных причин для сбора данных, особенно для исследователя.Проводя вас через них, вот несколько причин;
- Целостность исследования
Основной причиной сбора данных, будь то с помощью количественных или качественных методов, является обеспечение того, чтобы действительно сохранялась целостность вопроса исследования.
- Снижение вероятности ошибок
Правильное использование соответствующих методов сбора данных снижает вероятность ошибок, согласующихся с результатами.
Чтобы свести к минимуму риск ошибок при принятии решений, важно собирать точные данные, чтобы исследователь не принимал неосведомленных решений.
Сбор данных экономит время и средства исследователя, которые в противном случае были бы потрачены впустую без более глубокого понимания темы или предмета исследования.
- Чтобы поддержать потребность в новой идее, изменении и/или инновациях
Чтобы доказать необходимость изменения нормы или введения новой информации, которая будет широко принята, важно собрать данные в качестве доказательства в поддержку этих утверждений.
Что такое инструмент сбора данных? Под средствами сбора данных понимаются устройства/инструменты, используемые для сбора данных, такие как бумажный вопросник или автоматизированная система опроса. Тематические исследования, контрольные списки, интервью, иногда наблюдение, а также опросы или анкеты — все это инструменты, используемые для сбора данных.
Тематические исследования, контрольные списки, интервью, иногда наблюдение, а также опросы или анкеты — все это инструменты, используемые для сбора данных.
Важно выбрать инструменты для сбора данных, поскольку исследования проводятся разными способами и для разных целей. Целью сбора данных является сбор качественных доказательств, которые позволяют анализу привести к формулировке убедительных и заслуживающих доверия ответов на поставленные вопросы.
Целью сбора данных является сбор качественных доказательств, которые позволяют анализу привести к формулированию убедительных и заслуживающих доверия ответов на поставленные вопросы. данные, т.е. необработанные данные, собранные из источника. Вы можете легко получить данные, используя по крайней мере три метода сбора данных с помощью нашего онлайн- и офлайн-инструмента сбора данных. То есть онлайн-анкеты, фокус-группы и отчетность.В наших предыдущих статьях мы объясняли, почему количественные методы исследования более эффективны, чем качественные.
Собирайте онлайн и оффлайн данные с Formplus
Вот 7 лучших методов и инструментов сбора данных для академических исследований, исследований мнений или исследований продуктовНиже приведены 7 лучших методов сбора данных для академических исследований, исследований мнений или продуктов.Также подробно обсуждается природа, плюсы и минусы каждого из них. В конце этого сегмента вы будете лучше информированы о том, какой метод лучше всего подходит для вашего исследования.
ИНТЕРВЬЮИнтервью — это беседа лицом к лицу между двумя людьми с единственной целью собрать соответствующую информацию для достижения цели исследования.
Используйте этот шаблон формы согласия на интервью, чтобы интервьюируемый дал вам согласие на использование данных, полученных в ходе ваших интервью, в исследовательских целях.
- Структурированные интервью — Проще говоря, это анкета, которую вводят в устной форме. С точки зрения глубины, это уровень поверхности и обычно завершается в течение короткого периода времени. Для скорости и эффективности это настоятельно рекомендуется, но ему не хватает глубины.
- Полуструктурированные интервью — В этом методе существует несколько ключевых вопросов, которые охватывают область исследования.Это дает исследователю немного больше свободы для изучения предмета.
- Неструктурированные интервью — Это углубленное интервью, которое позволяет исследователю целенаправленно собрать широкий спектр информации.
Профи
- Подробная информация
- Свобода гибкости
- Точные данные.
Минусы
Каковы лучшие инструменты сбора данных для интервью?
- Занимает много времени
- Дорого в сборе.
Вот несколько инструментов, которые можно использовать для сбора данных с помощью интервью.
Аудиорекордер используется для записи звука на диск, кассету или пленку. Аудиоинформация может удовлетворить потребности широкого круга людей, а также предоставить альтернативу печатным инструментам сбора данных.
Преимущество цифровой камеры в том, что ее можно использовать для передачи этих изображений на экран монитора, когда в этом возникает необходимость.
Видеокамера используется для сбора данных во время интервью.
Хотите провести интервью для исследования качественных данных или специального отчета? Используйте этот шаблон формы согласия на онлайн-интервью, чтобы позволить интервьюируемому дать свое согласие, прежде чем вы будете использовать данные интервью для исследования или отчета. Formplus Builder с премиальными функциями, такими как электронная подпись, поля загрузки, защита форм и т. д., является идеальным инструментом для создания предпочитаемых онлайн-форм согласия без опыта программирования.
АНКЕТЫЭто процесс сбора данных с помощью инструмента, состоящего из ряда вопросов и подсказок для получения ответов от лиц, которым он назначен.
Для ясности важно отметить, что анкета не является опросом, а является его частью. Опрос — это процесс сбора данных, включающий различные методы сбора данных, включая анкетирование.
В анкете используются три вида вопросов. Они есть; фиксированно-альтернативный, масштабный и открытый. При этом каждый из вопросов адаптирован к характеру и объему исследования.
Pros
- Может применяться в больших количествах и экономически эффективен.
- Его можно использовать для сравнения предыдущих исследований с целью измерения изменений.
- Простота визуализации и анализа.
- Анкеты предлагают полезные данные.
- Личность респондента защищена.
- Анкеты могут охватывать все области темы.
- Относительно недорого.
Минусы
Каковы лучшие инструменты сбора данных для вопросника?
- Ответы могут быть нечестными или респонденты теряют интерес на полпути.
- Анкеты не могут предоставить качественные данные.
- Вопросы могут остаться без ответа.
- Респонденты могут иметь скрытые планы.
- Не все вопросы можно легко проанализировать.
Formplus позволяет создавать мощные формы для сбора необходимой информации. Formplus поможет вам создать онлайн-формы, которые вам нравятся. Шаблон формы онлайн-анкеты Formplus для получения действенных тенденций и измеримых ответов.Проведите исследование, оптимизируйте знания о своем бренде или просто познакомьтесь с аудиторией с помощью этого шаблона формы. Шаблон формы быстрый, бесплатный и полностью настраиваемый.
Подпишитесь бесплатно
Бумажный вопросник — это инструмент сбора данных, состоящий из серии вопросов и/или подсказок, предназначенный для сбора информации от респондентов.
Зарегистрируйтесь в Formplus Builder, чтобы создавать предпочтительные онлайн-опросы или анкеты для сбора данных. Вам не нужно быть технически подкованным! Начните создавать качественные анкеты с Formplus.Начать бесплатно
ОТЧЕТНОСТЬОтчетность по определению представляет собой процесс сбора и представления данных для дальнейшего анализа.Ключевым аспектом представления данных является представление точных данных, поскольку представление неточных данных приводит к неосведомленному принятию решений.
Профессионалы
- Информированное принятие решений.
- Легкодоступный.
Минусы
Какие инструменты сбора данных лучше всего подходят для отчетности?
- Самостоятельные ответы могут быть преувеличены.
- На результаты может повлиять систематическая ошибка.
- Респонденты могут стесняться раскрывать все подробности.
- Неточные отчеты приведут к необоснованным решениям.
Средства отчетности позволяют извлекать и представлять данные в виде диаграмм, таблиц и других визуализаций, чтобы пользователи могли найти полезную информацию. Вы можете получить данные для отчетности из отчетов неправительственных организаций (НПО), газет, статей на веб-сайтах, больничных записей.
Отчеты НПО содержат подробный и всесторонний отчет о деятельности НПО, охватывающий такие области, как бизнес и права человека.Информация, содержащаяся в этих отчетах, относится к конкретным исследованиям и формирует приемлемую академическую базу для сбора данных.
Газетные данные относительно легко собрать, и иногда они являются единственным постоянно доступным источником данных о событиях. Несмотря на то, что в газетных данных существует проблема предвзятости, они по-прежнему являются действенным инструментом сбора данных для отчетности.
Сбор и использование данных, содержащихся в статьях на веб-сайтах, также является еще одним инструментом сбора данных.Сбор данных из веб-статей — это более быстрый и менее дорогой сбор данных. Два основных недостатка использования этого метода представления данных — предвзятость, присущая процессу сбора данных, и возможные проблемы с безопасностью/конфиденциальностью.
Здравоохранение включает в себя широкий набор государственных и частных систем сбора данных, включая обследования состояния здоровья, административные записи о регистрации и выставлении счетов, а также медицинские записи, используемые различными организациями, включая больницы, центры медицинского обслуживания, врачи и планы медицинского обслуживания.
СУЩЕСТВУЮЩИЕ ДАННЫЕЭто введение новых следственных вопросов в дополнение к тем, которые первоначально использовались при первоначальном сборе данных. Это включает в себя добавление измерения к исследованию или исследованию. Примером может служить поиск данных из архива.
Профи
- Точность очень высокая.
- Легкодоступная информация.
Минусы
Каковы лучшие инструменты сбора данных для существующих данных?
- Проблемы с оценкой.
- Трудность понимания.
Понятие «Существующие данные» означает, что данные собираются из существующих источников для изучения исследовательских вопросов, отличных от тех, для которых данные были первоначально собраны.
НАБЛЮДЕНИЕ
- Исследовательские журналы . В отличие от газет и журналов, исследовательские журналы предназначены для академической или технической аудитории, а не для обычных читателей.Журнал — это научное издание, содержащее статьи, написанные исследователями, профессорами и другими экспертами.
- Опросы . Опрос — это инструмент сбора данных для сбора информации из выборки населения с целью обобщения результатов для большей совокупности. Опросы преследуют различные цели и могут проводиться разными способами в зависимости от преследуемых целей.
Это метод сбора данных, при котором информация о явлении собирается посредством наблюдения.Характер наблюдения может быть реализован как полный наблюдатель, наблюдатель как участник, участник как наблюдатель или как полный участник. Этот метод является ключевой базой для формулирования гипотезы.
Плюсы
- Простота управления.
- Существует большая точность результатов.
- Это общепринятая практика.
- Размывает ситуацию нежелания респондентов администрировать отчет.
- Подходит для определенных ситуаций.
Минусы
Каковы лучшие инструменты сбора данных для наблюдения?
- Некоторые явления недоступны наблюдению.
- На это нельзя положиться.
- Может возникнуть предвзятость.
- Дорого администрировать.
- Его достоверность нельзя точно предсказать.
Наблюдение предполагает активное получение информации из первоисточника.Наблюдение также может включать восприятие и запись данных с помощью научных инструментов. Лучшими инструментами для наблюдения являются:
ФОКУС-ГРУППЫ
- Контрольные списки — критерии для конкретных штатов, позволяющие пользователям собирать информацию и делать суждения о том, что они должны знать в отношении результатов.
- Непосредственное наблюдение — это наблюдательный метод сбора оценочной информации.Оценщик наблюдает за субъектом в его или ее обычном окружении, не изменяя этого окружения.
В отличие от количественных исследований, которые включают числовые данные, этот метод сбора данных больше фокусируется на качественных исследованиях. Он подпадает под основную категорию данных, основанных на чувствах и мнениях респондентов. Это исследование включает в себя задавание открытых вопросов группе лиц, обычно состоящей из 6–10 человек, для предоставления обратной связи.
Профи
- Полученная информация обычно очень подробная.
- Экономически эффективен по сравнению с индивидуальными интервью.
- Отражает скорость и эффективность предоставления результатов.
Минусы
Каковы лучшие инструменты сбора данных для фокус-групп?
- Отсутствие глубины в освещении мельчайших деталей предмета.
- Предвзятость все еще может быть очевидной.
- Требуется обучение интервьюеров
- Исследователь очень мало контролирует результат.
- Несколько вокальных голосов могут заглушить остальные.
- Сложность при наборе группы «все включено».
Фокус-группа — это метод сбора данных, который тесно организован и структурирован вокруг набора вопросов. Цель встречи – извлечь из участников развернутые ответы на эти вопросы. Лучшие инструменты для работы с фокус-группами:
КОМБИНИРОВАННОЕ ИССЛЕДОВАНИЕ
- Двусторонний — Одна группа наблюдает, как другая группа отвечает на вопросы, заданные модератором.Выслушав то, что может предложить другая группа, группа, которая слушает, может способствовать дальнейшему обсуждению и потенциально может прийти к другим выводам .
- Дуэлянт-Модератор — Есть два модератора, которые играют роль адвоката дьявола.
Этот метод сбора данных включает использование инновационных методов для расширения участия как отдельных лиц, так и групп.Также в основной категории это сочетание интервью и фокус-групп при сборе качественных данных. Этот метод является ключевым при обращении к деликатным темам.
Профи
- Поощряйте участников давать ответы.
- Стимулирует более глубокую связь между участниками.
- Относительная анонимность респондентов увеличивает участие.
- Повышает полноту собираемых данных.
Минусы
Какие инструменты сбора данных лучше всего подходят для комбинированных исследований?
- Стоит больше всего из всех топ 7.
- Это занимает больше всего времени.
Метод комбинированного исследования включает два или более метода сбора данных, например, интервью, а также анкетирование или комбинацию полуструктурированных телефонных интервью и фокус-групп.
- Онлайн-опрос — Здесь объединены два инструмента: онлайн-интервью и использование анкет.Это анкета, которую целевая аудитория может заполнить через Интернет. Это своевременно, эффективно и действенно. Тем более, что собираемые данные носят количественный характер.
- Двойной модератор — Здесь объединены два инструмента: фокус-группы и структурированные анкеты. Структурированные вопросы задают направление относительно направления исследования, в то время как два модератора руководят ходом обсуждения. В то время как один следит за тем, чтобы сеанс фокус-группы проходил гладко, другой следит за тем, чтобы все рассматриваемые темы были охвачены.Фокус-группы с двумя модераторами обычно приводят к более продуктивной сессии и, по сути, к оптимальному сбору данных.
- Широкие возможности настройки форм
С помощью Formplus вы можете создать свою уникальную форму опроса.
Аналитика форм — функция formplus, позволяющая просматривать количество респондентов, уникальные посещения, общее количество посещений, процент отказов и среднее время, затраченное на отправку. Этот инструмент устраняет необходимость ручного расчета полученных данных и/или ответов, а также коэффициента конверсии для вашего опроса.
- Встроить форму опроса на свой веб-сайт
Скопируйте ссылку в свою форму и вставьте в виде iframe, который будет автоматически загружаться при загрузке вашего веб-сайта, или в виде всплывающего окна, которое открывается, когда респондент щелкает ссылку.Вставьте ссылку на свою страницу в Твиттере, чтобы предоставить мгновенный доступ своим подписчикам.
Функция геолокации в Formplus позволяет определить, откуда приходят отдельные ответы. Он использует Google Maps для точного определения долготы и широты респондента вместе с ответами.
Эта функция помогает экономить пространство по горизонтали, поскольку позволяет помещать несколько параметров в одно поле. Это означает включение дополнительной информации в форму опроса.
Читайте также: 10 причин использовать Formplus для сбора данных в Интернете
Вот как использовать Formplus для сбора данных в Интернете за 7 простых шагов.
- Зарегистрируйтесь или зарегистрируйтесь в конструкторе Formplus : Начните создавать предпочитаемую анкету или опрос, зарегистрировавшись с помощью своей учетной записи Google, Facebook или электронной почты.
Formplus предоставляет вам бесплатный план с базовыми функциями, которые вы можете использовать для сбора онлайн-данных.
Создайте онлайн-анкету или опрос бесплатно
2. Введите название опроса и используйте параметры выбора конструктора форм, чтобы начать создавать опросы.
Используйте поля параметров выбора, такие как одиночный выбор, множественный выбор, флажок, радио и выбор изображения, чтобы создавать предпочтительные онлайн-опросы с несколькими вариантами ответов.
3. Хотите, чтобы клиенты оценили доставку ваших товаров или услуг?
Используйте рейтинг, чтобы респонденты опроса могли оценить ваши продукты или услуги.
4. Украсьте свою онлайн-анкету с помощью функций настройки Formplus.
Можно;
- Изменение цвета темы
- Добавление логотипа и изображения вашего бренда в формы
- Изменение ширины и макета формы
- При необходимости отредактируйте кнопку отправки
- сделал пользовательский CSS, чтобы украсить вашу анкету? Если да, просто скопируйте и вставьте его в параметр CSS.
5. Измените настройки анкеты опроса в соответствии со своими потребностями
Выберите, где вы хотите хранить свои файлы и ответы. Выберите крайний срок отправки, выберите часовой пояс, ограничьте ответы респондентов, включите Captcha для предотвращения спама и сбора данных о местоположении клиентов.
Установите вступительное сообщение для респондентов перед тем, как они начнут опрос, включите «кнопку запуска», чтобы опубликовать окончательное сообщение об отправке, или перенаправьте респондентов на другую страницу, когда они отправляют свои анкеты.
Измените список уведомлений по электронной почте и инициируйте автоответчик для всех респондентов вашего опроса. Вы также можете передавать свои формы другим пользователям, которые могут стать администраторами форм.
6. Поделитесь ссылками на страницу анкеты вашего опроса с клиентами.
Существует возможность скопировать и поделиться ссылкой как «Всплывающее окно» или «Встроить код». Инструмент сбора данных автоматически создает QR-код для опросного листа, который вы можете загрузить и поделиться соответствующим образом.
Поздравляем, если вы добрались до этого этапа. Вы можете начать делиться ссылкой на анкету опроса со своими клиентами.
7. Просмотр ваших ответов на анкету опроса
Переключение с представлением вашего резюме из вариантов. Будь то один, стол или карты.
8. Разрешить Formplus Analytics интерпретировать данные анкеты опроса.
7 советов по созданию лучших опросов для сбора данных
- Количество заполнений анкеты опроса
- Количество клиентов, достигших
- Уровень отказа: уровень, с которым клиенты покидают форму, не отправив ее.
- Коэффициент конверсии: процент клиентов, заполнивших онлайн-форму
- Среднее время, затрачиваемое на одно посещение
- Местонахождение клиентов/респондентов.
- Тип устройства, используемого клиентом для заполнения анкеты.
- Определите цель вашего опроса . После определения цели вашего опроса это поможет решить, какие вопросы являются первоочередными.Четкая достижимая цель, например, будет отражать четкую причину того, почему что-то происходит. например «Цель этого опроса — понять, почему сотрудники покидают предприятие».
- Используйте закрытые четко определенные вопросы — Избегайте открытых вопросов и убедитесь, что вы не предлагаете респонденту свой предпочтительный ответ. Если возможно, предложите ряд ответов с вариантами выбора и оценками.
- Перспектива опроса должна быть привлекательной и привлекательной — Привлекательный вид опроса побуждает большее количество получателей принять участие в опросе.
- Заверьте респондентов в безопасности их данных . Вы хотите, чтобы ваши респонденты были уверены в раскрытии вам своих личных данных. Вы обязаны информировать респондентов о том, что данные, которые они предоставляют, являются конфиденциальными и собираются только в целях исследования.
- Убедитесь, что ваш опрос может быть завершен в рекордно короткие сроки — В идеале, в типичном опросе, пользователи должны иметь возможность ответить в течение 100 секунд.Уместно заметить, что они, респонденты, делают вам одолжение. Не подвергайте их стрессу. Будьте кратки и сразу переходите к делу.
- Проведите пробный опрос. . Предварительный просмотр опроса перед его отправкой предполагаемым респондентам. Сделайте пробную версию, которую вы отправите нескольким людям.
- Добавьте награду для пользователей по завершении опроса — Предложите своим респондентам что-то, чего они с нетерпением ждут в конце опроса.Думайте об этом как о копейке за свои проблемы. Это вполне может быть поощрением, в котором они нуждаются, чтобы не бросать опрос на полпути.
Попробуйте Formplus сегодня. Вы можете начать создавать свои собственные опросы с помощью конструктора онлайн-опросов Formplus. Применяя эти советы, вы обязательно получите максимальную отдачу от своих онлайн-опросов.
Лучшие шаблоны опросов для сбора данныхВ шаблоне вы можете собирать данные для измерения удовлетворенности клиентов в таких ключевых областях, как покупка товара и уровень обслуживания, который они получили.Это также дает представление о том, какие продукты понравились покупателю, как часто они покупают такой продукт и может ли покупатель порекомендовать продукт другу или знакомому.
С помощью этого шаблона вы сможете точно измерить соотношение мужчин и женщин, возрастной диапазон и количество безработных в конкретной стране, а также получить их личные данные, такие как имена и адреса.
Респонденты также могут высказать свои религиозные и политические взгляды в отношении рассматриваемой страны.
В шаблоне онлайн-формы обратной связи содержится подробная информация об используемом продукте и/или услуге. Идентификация этого продукта или услуги и документирование того, как долго клиент их использовал.
Измеряется общее удовлетворение, а также предоставление услуг. Также измеряется вероятность того, что клиент также порекомендует указанный продукт.
Шаблон онлайн-анкеты содержит данные респондента, а также сведения об образовании для сбора информации, которая будет использоваться в научных исследованиях.
Респонденты также могут указать свой пол, расу, область обучения, а также представить условия жизни в качестве предварительных данных для исследования.
Шаблон представляет собой лист данных, содержащий всю необходимую информацию об учащемся. Имя учащегося, домашний адрес, имя опекуна, посещаемость, а также успеваемость в школе хорошо представлены в этом шаблоне. Это идеальный метод сбора данных для школы или образовательной организации.
Также включена запись взаимодействия с другими, а также место для краткого комментария об общей успеваемости и отношении учащегося.
Этот шаблон формы согласия на онлайн-интервью позволяет интервьюируемому подписать свое согласие на использование данных интервью для исследования или репортажа для журналиста. Formplus Builder с премиальными функциями, такими как короткие текстовые поля, загрузка, электронная подпись и т. д., является идеальным инструментом для создания предпочтительных онлайн-форм согласия без опыта программирования.
Каков наилучший метод сбора качественных данных?Ответ: Комбинированное исследование
Лучшим методом сбора данных для исследователя для сбора качественных данных, которые обычно представляют собой данные, основанные на чувствах, мнениях и убеждениях респондентов, является комбинированное исследование.
Причина, по которой комбинированное исследование лучше всего подходит, заключается в том, что оно охватывает атрибуты интервью и фокус-групп. Это также полезно при сборе конфиденциальных данных. Его можно охарактеризовать как универсальный метод сбора количественных данных.
Помимо всего прочего, комбинированное исследование увеличивает богатство собираемых данных по сравнению с другими методами сбора качественных данных.
Каков наилучший метод сбора данных для количественных исследований?Ответ: Анкета
Наилучший метод сбора данных, который исследователь может использовать для сбора количественных данных, который принимает во внимание данные, которые могут быть представлены в числах и числах, которые могут быть выведены математически, — это Анкета.
Их можно назначать большому количеству респондентов, экономя при этом затраты. Для количественных данных, которые могут быть громоздкими или объемными по своему характеру, использование Вопросника упрощает визуализацию и анализ таких данных.
Еще одним ключевым преимуществом Анкеты является то, что ее можно использовать для сравнения и противопоставления предыдущих исследований, проведенных для измерения изменений.
Зарегистрируйтесь в Formplus Builder, чтобы создавать предпочитаемые онлайн-опросы или анкеты для сбора данных.Вам не нужно быть технически подкованным! Собирайте онлайн и оффлайн данные с Formplus
Используйте пакет инструментов анализа для выполнения комплексного анализа данных
Инструменты анализа Two-Sample t-Test проверяют равенство совокупностей, лежащих в основе каждой выборки. В трех инструментах используются разные предположения: дисперсии популяции равны, дисперсии популяции не равны и что две выборки представляют собой наблюдения до и после лечения одних и тех же субъектов.
Для всех трех инструментов ниже вычисляется значение t-Statistic, t, которое отображается как «t Stat» в выходных таблицах. В зависимости от данных это значение t может быть отрицательным или неотрицательным. В предположении равной базовой совокупности означает, что если t < 0, «P (T <= t) односторонний» дает вероятность того, что будет наблюдаться значение t-статистики, которое будет более отрицательным, чем t. Если t >=0, «P(T <= t) one-tail" дает вероятность того, что будет наблюдаться значение t-статистики, которое будет более положительным, чем t.«t Critical one-tail» дает значение отсечки, так что вероятность наблюдения значения t-Statistic, большего или равного «t Critical one-tail», равна Alpha.
«P(T <= t) two-tail" дает вероятность того, что будет наблюдаться значение t-статистики, которое по абсолютной величине больше, чем t. «P Критический двухсторонний» дает пороговое значение, так что вероятность того, что наблюдаемая t-статистика больше по абсолютному значению, чем «P Критический двухсторонний», равна Альфа.
t-тест: два образца в паре для среднего
Вы можете использовать парный тест, когда в выборках есть естественное спаривание наблюдений, например, когда группа выборок тестируется дважды — до и после эксперимента.Этот инструмент анализа и его формула выполняют парный t-критерий Стьюдента для двух выборок, чтобы определить, вероятно ли, что наблюдения, полученные до обработки, и наблюдения, полученные после обработки, получены из распределений с равными средними значениями совокупности. Эта форма t-критерия не предполагает, что дисперсии обеих совокупностей равны.
Примечание. Среди результатов, генерируемых этим инструментом, есть объединенная дисперсия, накопленная мера разброса данных о среднем значении, полученная по следующей формуле.
t-критерий: две выборки при условии равенства дисперсий
Этот инструмент анализа выполняет t-критерий Стьюдента для двух выборок. Эта форма t-теста предполагает, что два набора данных получены из распределений с одинаковыми дисперсиями. Он называется гомоскедастическим t-критерием. Вы можете использовать этот t-критерий, чтобы определить, вероятно ли, что две выборки получены из распределений с равными средними значениями генеральной совокупности.
t-критерий: две выборки с предположением о неравных дисперсиях
Этот инструмент анализа выполняет t-критерий Стьюдента для двух выборок. Эта форма t-теста предполагает, что два набора данных получены из распределений с неравной дисперсией. Он называется гетероскедастическим t-критерием. Как и в предыдущем случае с равными отклонениями, вы можете использовать этот t-критерий, чтобы определить, вероятно ли, что две выборки получены из распределений с равными средними значениями генеральной совокупности.Используйте этот тест, когда в двух выборках есть разные предметы. Используйте парный тест, описанный в следующем примере, когда есть один набор субъектов, и две выборки представляют измерения для каждого субъекта до и после лечения.
Следующая формула используется для определения статистического значения t .
Следующая формула используется для расчета степеней свободы, df. Поскольку результат вычисления обычно не является целым числом, значение df округляется до ближайшего целого числа, чтобы получить критическое значение из таблицы t.Функция листа Excel T . ТЕСТ использует рассчитанное значение df без округления, поскольку можно вычислить значение для T . TEST с нецелым df. Из-за этих разных подходов к определению степеней свободы результаты T . ТЕСТ и этот инструмент t-теста будут отличаться в случае неравных отклонений.
.
 Однако с помощью инструмента сбора данных Formplus вы можете собирать все типы первичных данных для научных исследований, исследований мнений или продуктов.
Однако с помощью инструмента сбора данных Formplus вы можете собирать все типы первичных данных для научных исследований, исследований мнений или продуктов. Интервью бывают разных типов, а именно; Структурированные, полуструктурированные и неструктурированные, каждый из которых имеет небольшие отличия от другого.
Интервью бывают разных типов, а именно; Структурированные, полуструктурированные и неструктурированные, каждый из которых имеет небольшие отличия от другого. Преимуществом этого метода является свобода, которую он дает исследователю, чтобы сочетать структуру с гибкостью, даже если это требует больше времени.
Преимуществом этого метода является свобода, которую он дает исследователю, чтобы сочетать структуру с гибкостью, даже если это требует больше времени. Он сочетает в себе функции аудиорекордера и видеокамеры. Предоставленные данные носят качественный характер и позволяют респондентам исчерпывающе ответить на заданные вопросы. Если вам нужно собрать конфиденциальную информацию во время интервью, видеокамера может вам не подойти, поскольку вам нужно будет сохранить конфиденциальность вашего субъекта.
Он сочетает в себе функции аудиорекордера и видеокамеры. Предоставленные данные носят качественный характер и позволяют респондентам исчерпывающе ответить на заданные вопросы. Если вам нужно собрать конфиденциальную информацию во время интервью, видеокамера может вам не подойти, поскольку вам нужно будет сохранить конфиденциальность вашего субъекта. Анкеты предназначены для сбора данных от группы.
Анкеты предназначены для сбора данных от группы.
 В основном предназначенные для статистического анализа ответов, они также могут использоваться как форма сбора данных.
В основном предназначенные для статистического анализа ответов, они также могут использоваться как форма сбора данных.
 НПО часто сосредотачиваются на проектах развития, организованных для продвижения конкретных целей.
НПО часто сосредотачиваются на проектах развития, организованных для продвижения конкретных целей. Предоставленные данные являются четкими, беспристрастными и точными, но должны быть получены законным путем, поскольку медицинские данные хранятся в соответствии с самыми строгими правилами.
Предоставленные данные являются четкими, беспристрастными и точными, но должны быть получены законным путем, поскольку медицинские данные хранятся в соответствии с самыми строгими правилами. Инструменты для сбора существующих данных включают:
Инструменты для сбора существующих данных включают: 
 Они предлагают систематические способы сбора данных о конкретном поведении, знаниях и навыках.
Они предлагают систематические способы сбора данных о конкретном поведении, знаниях и навыках.
 Главный положительный момент фокус-группы дуэлянтов-модераторов заключается в том, чтобы способствовать выдвижению новых идей путем введения новых способов мышления и различных точек зрения.
Главный положительный момент фокус-группы дуэлянтов-модераторов заключается в том, чтобы способствовать выдвижению новых идей путем введения новых способов мышления и различных точек зрения. Лучшие инструменты для комбинированного исследования:
Лучшие инструменты для комбинированного исследования:  С возможностью изменения темы, цвета шрифта, шрифта, типа шрифта, макета, ширины и т. д. вы можете создать привлекательную форму опроса. Конструктор также предоставляет вам как можно больше функций на выбор, и вам не нужно быть графическим дизайнером, чтобы создать форму.
С возможностью изменения темы, цвета шрифта, шрифта, типа шрифта, макета, ширины и т. д. вы можете создать привлекательную форму опроса. Конструктор также предоставляет вам как можно больше функций на выбор, и вам не нужно быть графическим дизайнером, чтобы создать форму.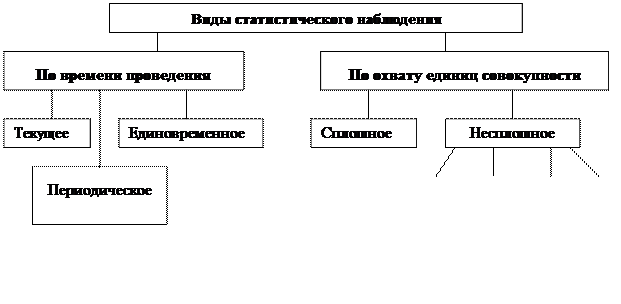
 Тарифные планы с широкими возможностями начинаются с 20 долларов в месяц с разумными скидками для образовательных и некоммерческих организаций.
Тарифные планы с широкими возможностями начинаются с 20 долларов в месяц с разумными скидками для образовательных и некоммерческих организаций. Это идеальный количественный исследовательский метод сбора данных.
Это идеальный количественный исследовательский метод сбора данных.

 Ознакомьтесь с конструктором Formplus, чтобы найти красочные варианты, которые можно интегрировать в дизайн вашего опроса. Вы можете использовать изображения и видео, чтобы участники не отрывались от своих экранов.
Ознакомьтесь с конструктором Formplus, чтобы найти красочные варианты, которые можно интегрировать в дизайн вашего опроса. Вы можете использовать изображения и видео, чтобы участники не отрывались от своих экранов. Основываясь на их ответах, вы можете сделать выводы и решить, готов ли ваш опрос к большому времени.
Основываясь на их ответах, вы можете сделать выводы и решить, готов ли ваш опрос к большому времени.